






 Tacotron2.0是一个用于从文本到语音合成的模型,采用encoder-decoder架构。Encoder部分包括Embedding层、1d卷积层和双向LSTM,用于捕捉文本的上下文信息。Decoder包含Pre-Net、位置敏感注意力机制和Post-Net,用于生成高质量的频谱帧。模型通过位置敏感注意力机制实现对长时依赖的建模,并利用Post-Net改进频谱重构。损失函数包括Mel谱的MSE和L1损失、终止符号的交叉熵损失,以及注意力损失,确保合成语音的质量和序列的连贯性。
Tacotron2.0是一个用于从文本到语音合成的模型,采用encoder-decoder架构。Encoder部分包括Embedding层、1d卷积层和双向LSTM,用于捕捉文本的上下文信息。Decoder包含Pre-Net、位置敏感注意力机制和Post-Net,用于生成高质量的频谱帧。模型通过位置敏感注意力机制实现对长时依赖的建模,并利用Post-Net改进频谱重构。损失函数包括Mel谱的MSE和L1损失、终止符号的交叉熵损失,以及注意力损失,确保合成语音的质量和序列的连贯性。
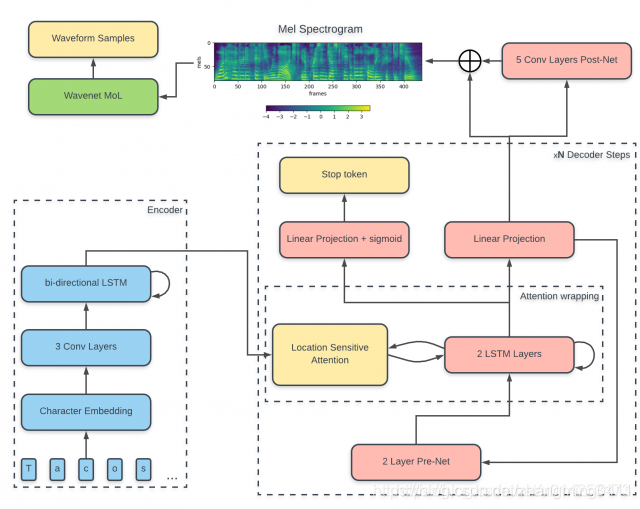
Tacotron 2.0模型结构
Tacotron是一个端到端的从文本合成语音的模型,也是典型的encoder2decoder结构。encoder用来将文本特征转化为中间特征(可以类比为phoneme特征吧);decoder使用自回归的方式,使用中间特征与上一时刻的mel特征输出去生成这一时刻的mel特征。
Encoder

Encoder主要包含Embeding层、三层的1d的卷积层、以及一层双向的LSTM层。
Input为(Batch,L,F)L为文本长度,F为文本特征维度。
- Embeding层将字母转换为512维词向量。
- 卷积层:每个卷积层的输出channel为512,kernel为5x1的卷积核,即每层卷积横跨五个字符,后面接上bn层与relu激活函数,通过使用多层的卷积操作来对输入的文本序列进行上下文建模,用来获得上下文特征关系。主要是因为实践中rnn很难捕获长时的依赖
双向的LSTM层:为一层,输出的维度为512,来生成编码特征,编码特征维度为(Batch,L,512)。
Decoder
Decoder是一个包含了一个两层FC的Pre-Net、5层卷积的Post-Net以及包含的位置敏感的注意力机制模块。在训练时Pre-Net采用真实的Mel特征作为输入,进行训练。测试时,上一时刻Linear Projection的输出作为Pre-Net的这一时刻的输入。
-
Pre-Net为两层维度为512的全连接层的网络,作为信息瓶颈层,对学习注意力是必要的。Pre-Net的输入为特定一帧(也可以几帧拼接一下输入)的Mel特征维度为(Batch,D)。D为Mel特征的维度80。输出为(Batch,512)。
- 将这一时刻Pre-Net的输出与注意力模块输出的上一时刻上下文特征进行拼接操作后,送入到两层的由1024单元组成的LSTM层中,获得LSTM的输出,其特征维度为(Batch,1024)。
- 将Encoder的输出、步骤2中的LSTM输出、与累加的注意力权重变量(初始化为0)作为注意力机制的输入,并输出这一时刻的注意力权重与这一时刻的上下文特征。其中Encoder的输出可以视为Value、LSTM的输出视为Query、累加的注意力权重变量可以视作位置特征。注意力的具体操作为步骤四
- 对于注意力,Tacotron2使用的是位置敏感注意力(我看了它引用的那篇注意力得到论文,但是我觉得更像是结合内容与位置的混合注意力机制,并不是单纯的位置注意力)下图为解释:(来自于一个博客,懒得自己码公式了)

对于tanh激活函数里的第一项,其实就是解码器的这一时刻的隐状态做了一个映射(也就是LSTM的输出做了一个映射);第二项为编码器的隐状态做了一个映射(也就是Encoder的输出做了一个映射);第三项为累加的注意力权重变量做了一个映射。第一项加第二项相当于基于内容的注意力机制,第二项加第三项相当于基于位置的注意力机制。
这样等于说“使得模型在沿着输入序列向前移动的时候保持前后一致,减少了解码过程中潜在的子序列重复或遗漏”。
5.在步骤四等到注意力权重后,与Encoder的输出做加权和,等到这一时刻的上下文特征。此时,这一时刻的上下文特征再次与步骤二中的LSTM的输出进行拼接后,经过Linear Projection层的映射后,得到这一时刻的目标频谱帧6
6.将这一时刻的目标频谱帧经过5层的Post-net来预测一个残差叠加到卷积前的频谱帧上,用以改善频谱重构的整个过程。post-net每层由512个5X1卷积核组成,后接批归一化层,除了最后一层卷积,每层批归一化都用tanh激活。
7.另外步骤五得到目标频谱帧经过另外一个并行的Linear Projection+sigmoid层,来预测输出序列是否已经完成的概率。
损失函数
在Anthea中损失函数共有四项,分别是步骤五与步骤六得到的目标频谱与gt的mse loss项与L1 loss项、步骤七的交叉熵 loss项,以及注意力损失项(目的是为了使注意力排列更加单调)
但是在官方的文档中只有前三项,没有第四项的注意力损失。


















 331
331

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









