



在自然语言处理(NLP)领域,Prompt 调优是一种强大的技术,它可以显著提高模型的性能和准确性。Prompt 调优可以帮助我们更有效地利用预训练模型,让模型更好地适应特定任务和数据集。本文以文心一言为主,介绍 Prompt 调优的过程、技巧和实用示例,帮助大家更好地掌握这一技术。
如何通俗的理解大模型
如何通俗的理解大模型?
我们可以把它类比为一个学习了好多年的一个人的大脑,这个「大脑」通过多年的海量知识的学习,知道了大量的通用知识,能够进行基础计算,进行推理预测,用身边工具进行复杂的计算,有时还会说谎。
我们来看如今大模型产品的几个特点,并与人的例子进行对比:
| 特点 | 大模型 | 人 |
| 庞大的参数规模和训练数据量 | 大模型的参数规模通常在百亿级别以上,甚至高达万亿,相比之下,以往模型的参数规模较小。大模型通过大量数据的训练,具有更强的泛化能力,可以完成多个不同的任务 | 一个人多年的学习,掌握了大量的知识 |
| 通用性 | 大模型是一座通用基础模型,可以支撑多种任务,而以往的模型大多是弱人工智能,只能完成单一的任务。大模型的出现降低了开发人工智能产品的门槛,不再需要为每个任务开发不同的模型,只需要一个基座模型就可以支撑非常多的服务 | 一个人经过多年的学习,掌握了很多这个世界的通用知识,这能够帮助他在生活中解决很多日常的问题,同时这个人也可以通过专业的学习获得某一方面的专长 |
| 不断学习和优化 | 大模型具有不断学习和优化的能力,它可以根据新的数据和反馈不断调整和改进自己的表现,从而不断提高自己的性能和智能水平 | 人在学习掌握了知识之后,可以根据在使用这些知识过程中获得的反馈,不断的更新和更正自己的知识库,也就是经验沉淀 |
| 可以使用插件 | 如今成熟的大模型产品不论是 GPT 或是文心一言等,都有一些缺点,比如对时事的了解并不多,比如无法进行复杂的逻辑推理和数学计算等。这些都可以使用不同的插件来让回答的内容更加准确和专业 | 人可以使用工具,例如可以借助计算机实现精密复杂的计算,借助交通工具实现快速的位置移动 |
| 大模型有时会产生幻觉 | 它们在回答某些问题时会出现明显的错误,看上去像是在一本正经的胡说八道 | 人有的时候也会说谎话 |
我们来重点理解一下大模型幻觉,要理解幻觉是如何产生的,我们先大致了解一下他是如何回答问题的。
通俗来讲,大模型并不是真的在回答你的问题,大模型作为一个生成模型,或者说统计模型,它做的仅仅是根据输入来预测下一个词元(token)是什么,目标是尽量让文本看起来更完整,举个例子:

文心一言并不知道我今天的早餐是什么,但是它却能够详细的描述出我的早餐的内容。这是因为它根据自己所掌握的数据,认为早餐通常都是这样描述的。
那么,一个真正的人会产生这种「幻觉」么?
想象这样一个场景,一个学生 A 对学生 B 说,猜我的今天早上吃了什么?这种时候,学生 B 会根据自己以往掌握的信息,思考之后给出他认为比较合理的 A 可能会吃的东西,但是实际上 B 并不知道这个回答是否正确,他只是在尽量让这个对话完整,给出一个合理的内容。
所以,「幻觉」从大模型的角度来看,是它经过「思考」给出了的一个它认为「合理」的答案。至于为什么它会认为这个回答「合理」,就和大模型的训练数据量和数据质量等等有关系了。
什么是 Prompt
Prompt 英文单词直译为:提示
我们可以从两个角度来认识:
- Prompt 是一段任务描述,这个任务对于文本生成场景,可以是一段描述或者一个主题,对于问答系统,可以是一个问题或者一段条件描述;对于图片生成,可以是一个图片要求的描述;对于图片分类,可以是一个类别或者标签信息。总之,Prompt 是驱动大模型的方式,大模型根据输入的 Prompt 给出我们想要的结果
- Prompt 是一种新的交互方式,我们的人机交互方式经历了从 CLI,到 GUI,再到 NUI,也就是如今的手势交互,身体交互,眼球交互等。所有这些交互方式都是人和计算设备的交互,而大模型也可以看成一个计算设备,人们与它的交互方式,就是 Prompt。我们只需要告诉大模型我们需要他干什么,他就会干什么,尽管现在我们仍然需要使用键盘鼠标或者通过一些终端设备输入文字,但是相信在将来,大模型发展的更加成熟之后,我们就可以与他进行非常自然的语言对话,届时和人与人之间的对话相比就没什么大的差别了。
为什么 Prompt 调优如此重要
前面提到 Prompt 就是我们与大模型的交互方式,我们通过 Prompt 描述我们的需求,对大模型下达任务和指令,那么我们如何准确的表述出我们的需求,让大模型能够正确理解和计算,给出我们想要的结果,自然就很重要了。
有研究表明,1 个 Prompt 相当于 100 个真实数据样本。这充分说明了 Prompt 蕴含的「信息量」之巨大。并且,prompt 在下游任务数据缺乏的场景下、甚至是 Zero-Shot 场景下,有着无可比拟的优势。因为大模型通常无法在小数据上微调。因此,基于 Prompt 的微调技术便成为了首要选择。
Prompt 优化
Prompt 调优有一个大的前提,我们需要假定大模型是正确的,如果得到了不符合预期的结果,那就是我们 Prompt 的问题。
我们通过一个例子大概体会一下 Prompt 优化调试的过程,在这个例子中,我们让模型倒序输出一句话「我有一条非常美丽的狗」:

可以看到这个结果并不正确。为什么会是这样?我们来思考一下,假如我们来做这件事,可以一次就将自己说的话倒着说出来么?并不行。我们需要思考,思考过程大致是这样的:
- 我有一句话:我有一条非常美丽的狗
- 拆解一下:我,有,一,条,非,常,美,丽,的,狗
- 倒过来读一下:狗的丽美常非条一有我
那么,我们是否能够让大模型也有这样一个思考过程呢?当然可以,这个叫做:Chain-of-Thought,也就是思维链。还是上面的例子,我们换一个提问方式:

可以看到比之前好了很多,但是其中有一些词语并没有正确的倒序,比如「美丽」和「非常」。这是因为大模型是基于 transformer 架构,这个架构只能够预测下一个词元(token)是什么,不能够知道接下来的一句话是什么,在这个例子中,「美丽」和「非常」都是一个独立的词元,所以它不会对这两个词语进行拆分倒序。那么接下来我们只需要进一步告诉他,不要以词元为单位进行拆分就可以了:

可以看到这次我们拿到了符合预期的正确的答案,这就是一个简单的 Prompt 优化的过程,我们通过对我们 Prompt 的调整,让大模型给出了我们满意的答案,并且,这种 Prompt 有些都是可以模板化的,比如将上面例子中的 Prompt 变成这种模板:「倒序这句话:${sentence},给出详细的思考过程,注意不要以token倒序,要拆解为单个汉字或者字符。」,这种模板就可以应用在很多需要倒序输出的场景中。
下面我们尝试总结一下 Prompt 的优化方法
通过前面的类比,我们大概可以感觉到,使用 Prompt 和大模型交互,是有些类似人与人之间的交互的,我们需要把我们的需求和意图准确地表达出来,让对方理解,必要时还会对对方加以引导。
Prompt 优化方式
Prompt 从不同的角度可以有一些不同的优化方式:
从 Prompt 的结构上看,可以有:
- Few-Shot(FS)是指模型在推理时给予少量样本,但不允许进行权重更新。
- One-Shot(1S)与 Few-Shot 类似,但只允许一个样本。
- Zero-Shot(0S)和 One-Shot 类似,但不允许提供样本,只给出描述任务的自然语言指令。该方法提供了最大的方便性、稳健性以及避免虚假相关的可能性,但也是最具挑战性的设置。在某些情况下,Zero-Shot 是最接近人类执行任务的方法。
从 Prompt 的内容上来看,可以有:
- Role Prompt: 与大模型玩「角色扮演」游戏。让大模型想象自己是某方面专家、因而获得更好的任务效果。
- Instruction Prompt: 指令形式的 Prompt。
- Chain-of-Thought(CoT) Prompt: 常见于推理任务中,通过让大模型 “Let's think step by step” 来逐步解决较难的推理问题,比如进行应用数学计算。
- Multimodal Prompt: 多模态 Prompt。顾名思义,输入不再是单一模态的 Prompt,而是包含了众多模态的信息。比如同时输入文本和图像与多模态大模型进行交互
这其中比较重要的是 Few-Shot Prompt 和 Chain-of-Thought Prompt。它们对后续人们构建 AI Agent 应用以及各项大模型产品落地起到了关键的作用。
Few-Shot Prompt
OpenAI 的 论文《Language Models are Few-Shot Learners》中显示了 Few-Shot 相对于 One-Shot 和 Zero-Shot 的效果:
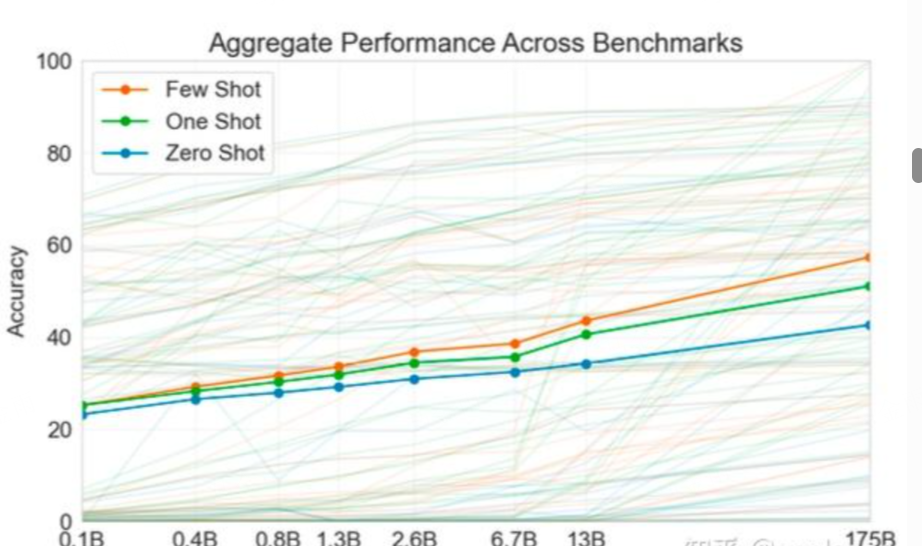
同时 Few-Shot Prompt 对应着一个 In-Context-Learning(ICL) 的概念,可以利用大模型的学习能力,使用少量文本对大模型进行调优。以下是一个关于Zero-Shot,One-Shot 和 Few-Shot 的例子:
示例 1:尝试给老虎取个名字

Zero-Shot

Few-Shot
示例 2:给一个不存在的东西写一个描述性的句子

Zero-Shot

Few-Shot
可以看到,在示例 1 中,对于起名字,在不提供示例的场景中,大模型给出的名字通常比较常规化,而在我们提供示例的场景中,大模型能够了解我们的取名倾向,并给出和示例风格一致的名字。
在示例 2 中,在不提供额外信息的情况下,大模型无法理解「云狗」这个概念,提供的回答比较常规化,只是一种可能的比较合理的解释。在提供了「苍石」这个信息和示例之后,大模型可以类比理解「云狗」是一种动物,并且给出和示例相近的介绍和例句。
Chain-of-Thought Prompt
CoT Prompt 则能够大幅提高大模型的多步推理能力:
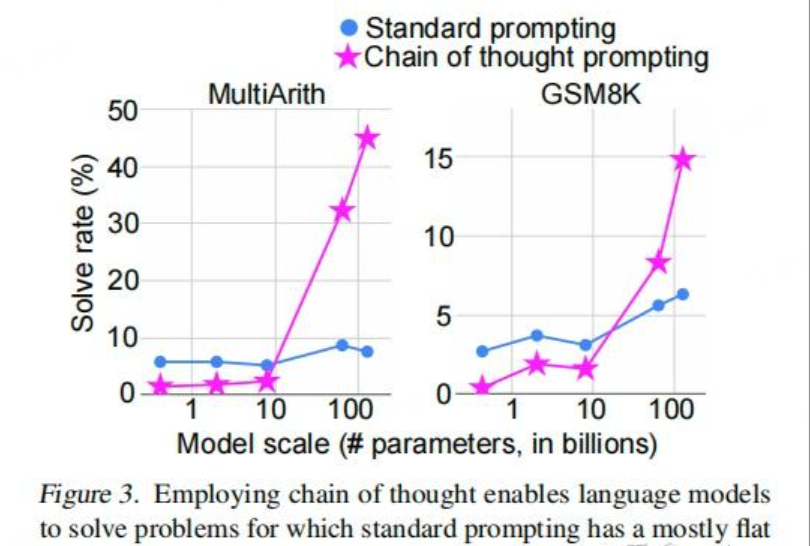
下面是一个 CoT Prompt 的例子:


可以看出,对于这道简单的应用题,大模型在直接给出结果时,结果是明显错误的,但是我们只需要改动一下 Prompt,让他输出详细的计算过程或者思考过程,大模型就能够给出正确的结果。
CRISPE 框架
以上这些 Prompt 优化方法并不是独立的,合理组合使用这些 Prompt 优化方法,就可以让 Prompt 的效果更好,那么如何合理的组合呢?这里可以使用一个提问框架:https://zhuanlan.zhihu.com/p/619590249CRISPE ,这个框架的整体结构是这样的:
- CR:Capacity and Role(能力与角色)。你希望 AI 扮演怎样的角色
- I:Insight(洞察),提供背景信息和上下文
- S:Statement(陈述),你希望 AI 做什么。
- P:Personality(个性),你希望 AI 以什么风格或方式回答你。
- E:Experiment(实验),要求 AI 为你提供多个答案
接下来我们使用文心一言应用一下这个框架:
假设我们的目标是获取一个浅显易懂的关于导数的解释方式,第一种方式是:

第二种方式我们来应用一下框架:

我们可以把上面的 Prompt 不同的形式应用到 CRISPE 框架中:
框架中的 CR实际上就是 Role Prompt。
我们可以在 Insight 阶段给它一些示例参考,一些背景,这就是 One-Shot 和 Few-Shot,对于支持多模态输入的模型,我们也可以给它一些其他形式的参考,这就是 Multimodal Prompt
Statement 部分通常都会是一段 Instruction Prompt
Personality 部分可以控制模型的输出方式,我们可以在这部分来让它不直接输出内容,而是展示出详细的思考过程,引导它不直接预测结果而是一步一步的推导,这就是 CoT Prompt
Prompt 的持续优化
Prompt 的优化并不是一蹴而就的,而是一个持续的过程,使用上述方式和框架也不能够保证每次都可以一次就拿到满意的结果,尤其是当我们需要大模型完成一些比较复杂的工作时。但是遵循这些方法,我们可以有更高的可能性能够通过较少的调整次数得到一个满意的结果,并且能够在这个结果上进行微调,比如润色,适当地增加图表等。
Prompt 除了人工调节,也可以让机器自动调节,也就是由机器自动生成 Prompt,这就是 Prompt Tuning。
AutoPrompt 就是一种自动调节 Prompt 的技术,它可以通过梯度优化,自动从一系列候选词中生成对目标任务最佳的 Prompt,详细可以看考论文:
AUTOPROMPT: Eliciting Knowledge from Language Models with Automatically Generated Prompts
扩展
AI Agent
什么是 AI Agent?简单的说,他是一个能够将大模型落地的方式,是比起简单的聊天更加方便更加实用的使用大模型的方式。通常我们与人工智能交互的方式都是通过 Prompt,但是总是一问一答,每次我们需要一些新的输出内容,我们都要给一个新的 Prompt,需要人来手动启动这个过程。而且通过前面我们可以看到大模型会有些缺点,如:幻觉,结果的不真实性,对时事的了解非常有限,很难应对复杂的计算。而 AI Agent 则不同,你只需要给他一个总目标,它就会根据情况自己生成一系列的任务列表并开始工作,可以理解为它可以进行自我提示(Self Prompt),下图比较好的概括了 AI Agent 的结构:
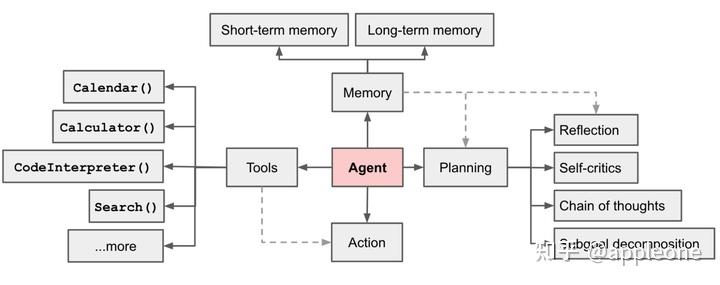
AI Agent 通常有四个结构部分:
记忆( Memory ):记忆和人类一样,可以分为短期记忆和长期记忆,短期记忆可以通过上下文学习,例如直接写到 Prompt 中的信息。长期记忆通常需要结合数据存储。
工具( Tools ):AI Agent 可以通过使用适当的工具来弥补 LLM 的缺点,比如一个可以获取外部数据的 API 集合,一个能够进行精确复杂计算的数学工具等
规划( Planning ):AI Agent 能够通过合理的 Prompt 进行自动规划,这其中包含了前面提到的 CoT 以及 Self-Critics 自我怀疑验证等。AI Agent 中使用的比较多的一种 Prompt 结构是 ReAct,即:Reason and Act。它和 CoT 有些像,但区别在于 CoT 是一次交互,而 ReAct 是动态的多次迭代调用 LLM。ReAct 中迭代使用 3 个元素:Thought,Action,Observation。其中 Thought 和 Action 由 LLM 生成,Observation是执行 Action 后获得的返回结果。步骤大概如下:
- Step 1:LLM 基于 Question 先 think( reasoning ),然后再决定采取什么行动。这样 LLM 就会生成 Thought 1 和 Action 1 。执行 Action 1 获得 Observation 1。
- Step 2:LLM 基于 Question,Thought 1,Action 1 和 Observation 1,汇总所有信息先 think( reasoning ),然后再决定采取什么行动。这样 LLM 就会生成 Thought 2 和 Action 2 。执行 Action 2 获得 Observation 2。
- Step 3:LLM基于 Question,Thought 1,Action 1,Observation 1,Thought 2,Action 2 和 Observation 2,汇总所有信息先 think( reasoning ),然后再决定采取什么行动。这样LLM就会生成 Thought 3 和 Action 3 。执行 Action 3 获得 Observation 3。以此类推直到 Action 表示结束。
行动( Action ):根据规划自行采取对应的行动来达到最终目标
LangChain
文档地址:https://www.langchain.asia
LangChain 是一个基于语言模型的应用程序开发框架,可以对接多种语言模型,通过这个框架,可以比较方便简单的实现一些能够用于生产的 AI 集成应用,它们中大多数都可以算作是 AI Agent。框架提供了 Python 和 JS/TS 两种语言版本,整体思想和 AI Agent 差不太多。
TypeChat
文档地址:https://microsoft.github.io/TypeChat/docs/introduction
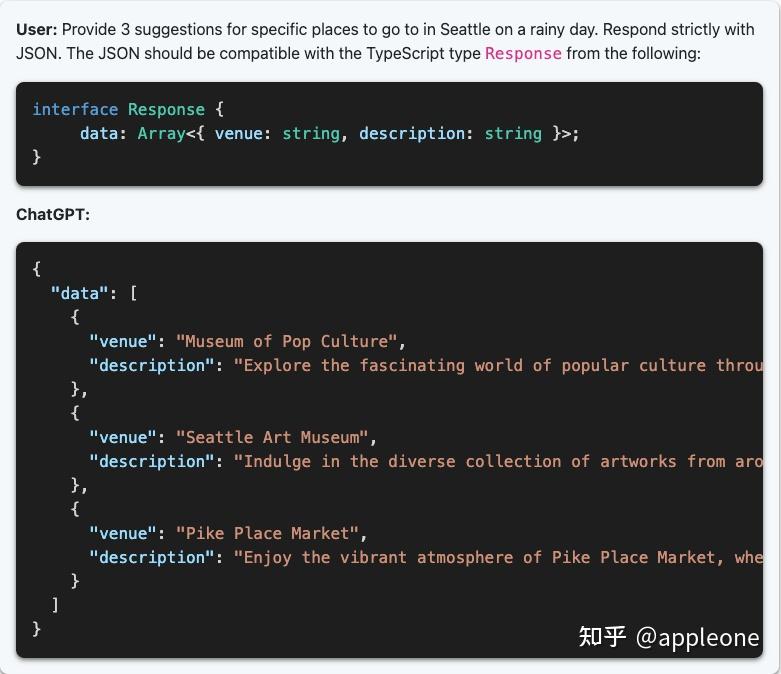
TypeChat 是微软开发的一个开源项目,根据文档所说,TypeChat 是一个可以轻松使用类型构建自然语言界面的库。
TypeChat 主要解决的问题点是:大模型独立作为一个聊天助手很不错,但是我们没有办法把它们很方便的集成到其它常规程序中,因为其它常规程序的数据处理维度通常都是字节,字符,JSON,Blob 等,但是大模型给出来的数据都是在自然语言层面。
TypeChat 的核心思想是:我们只需要提供一个 request 和一个 schema,也就是一些类型,就可以将大模型很好的集成到我们常规的程序中,并且数据都会有很好的结构和类型。
TypeChat 都做了什么呢?在我们定义好类型之后,TypeChat 做了这些事情:
- 使用我们提供的类型构建 Prompt
- 利用 schema 校验大模型的返回数据,如果校验错误,则会通过继续与大模型交互来修正这些错误的输出
- 简要总结大模型给出的实例确认他符合用户的意图
它做的事情可以从下面这张图做个简单的理解:
参考文档
- 什么是 Prompt?
- Language Models are Few-Shot Learners
- AUTOPROMPT: Eliciting Knowledge from Language Models with Automatically Generated Prompts
- GPT-3:《Language Models are Few-Shot Learners》论文分享
- Pretrain, Prompt and Predict, A Systematic Survey of Prompting Methods in NLP
- 如何更好地向 ChatGPT 提问?- 从文艺复兴到提示工程
- Prompt 的使用技巧
- 《大模型时代的科研》之2: Prompt Engineering (提示词工程)
- 如何写出优雅的prompt? - 通用的万能框架
- In Context Learning (ICL)
- Chain of Thought Prompting Elicits Reasoning in Large Language Models
- 思维链(Chain-of-thoughts)作为提示
- 大模型思维链(Chain-of-Thought)技术原理
- LangChain 完整指南:使用大语言模型构建强大的应用程序
- LangChain—Prompt Engineering:大模型炼金术
- LangChain:一个让你的LLM变得更强大的开源框架
- LangChain 完整指南:使用大语言模型构建强大的应用程序
- LangChain 中文网
- (万字长文)手把手教你认识学会 LangChain
- TypeChat 全面指南:从核心概念到使用
- Microsoft - TypeChat
- 细说 AI Agent
- What is an AI agent?
- ReAct: Synergizing Reasoning and Acting in Language Models

















 922
922

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









