







 本文介绍了K-NN(K最近邻)算法的基础知识,包括K-NN分类的工作原理和在二分类及多分类问题中的应用。通过Python的Scikit-Learn库,演示了如何加载数据集、划分训练集和测试集、创建KNeighborsClassifier模型、拟合数据以及进行预测和评估模型精度。在示例中,模型在测试集上的准确率为86%。
本文介绍了K-NN(K最近邻)算法的基础知识,包括K-NN分类的工作原理和在二分类及多分类问题中的应用。通过Python的Scikit-Learn库,演示了如何加载数据集、划分训练集和测试集、创建KNeighborsClassifier模型、拟合数据以及进行预测和评估模型精度。在示例中,模型在测试集上的准确率为86%。
最近在自学图灵教材《Python机器学习基础教程》,在csdn以博客的形式做些笔记。
K-NN算法是最简单的机器学习算法。其模型的构建仅仅是保存训练集数据。想要对新数据点做出预测,算法会在训练集数据中找到最近的数据点,即“最邻近”点。
K临近分类
我们首先以只考虑一个临近的最简单版本来了解knn分类,也就是说预测结果为想要预测数据点最近的训练数据点,如下图所示:

当然我们也可以考虑任意多个(k个)邻居,如下图:
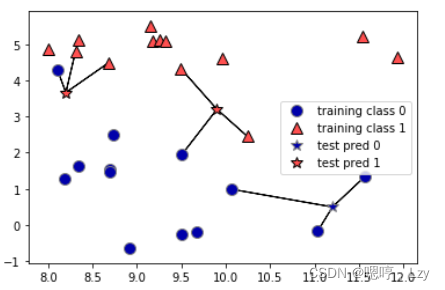
显然上述图对应的问题为二分类问题,但其方法也同样适用于多分类问题。
接下来我们看一下如何通过python的scikit-learn库来应用k-nn算法
首先导入数据集,将其分为训练集和测试集
from sklearn.model_selection import train_test_split
X, y = mglearn.datasets.make_forge()
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=0)上述代码中 mglearn.datasets.make_forge()为书中给出的数据集,你也可以使用自己的数据集
如果你想使用书中数据集,则需要导入mglearn库,通过pip install mglearn下载该库,并通过import mglearn导入
接下来导入knn算法类,将模型实例化,设置参数(邻居个数设置为3)
from sklearn.neighbors import KNeighborsClassifier
clf = KNeighborsClassifier(n_neighbors=3)然后可以使用训练集对分类器进行拟合
clf.fit(X_train, y_train)我们接下来可以使用predict方法对测试数据进行预测。对于测试集中的每个数据点,都要计算它在训练集的最邻近,然后找出其中出现次数最多的类别:
print("Test set predictions:", clf.predict(X_test))
为了评估模型泛化能力的好坏,我们可以对测试数据和测试标签调用score方法:
print("Test set accuracy: {:.2f}".format(clf.score(X_test, y_test))) 
可以看到,此模型的精确的为0.86,也就是说预测结果有86%是正确的。
这就是k临近分类的基本流程了,至于数据集的获取,数据的清洗等等事先需要完成的工作,在此不做讨论。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









