







 文章探讨了GPU的工作原理,包括渲染管线、SIMD和SIMT架构,以及NVIDIAFermi架构。提到了GPU优化策略,如减少CPU-GPU通讯和提高缓存效率。此外,文章还涉及了游戏对象的渲染,如顶点数据、材质和着色器,以及可见性裁剪技术如BVH和PVS。深度预计算和纹理压缩技术也有所提及,以提高渲染效率。最后,讨论了现代建模工具和游戏引擎如UE的Nanite技术,展示了GPU在游戏开发中的重要角色。
文章探讨了GPU的工作原理,包括渲染管线、SIMD和SIMT架构,以及NVIDIAFermi架构。提到了GPU优化策略,如减少CPU-GPU通讯和提高缓存效率。此外,文章还涉及了游戏对象的渲染,如顶点数据、材质和着色器,以及可见性裁剪技术如BVH和PVS。深度预计算和纹理压缩技术也有所提及,以提高渲染效率。最后,讨论了现代建模工具和游戏引擎如UE的Nanite技术,展示了GPU在游戏开发中的重要角色。
30FPS+ —— runtime级别
about 10FPS —— interactive级别
课程未涉及——卡通渲染、2D渲染引擎、次表面(皮肤材质)、毛发
渲染管线
-
顶点数据Vert
-
三角数据Tri
-
光栅化Rasterization
-
片元Fragment
-
材质作为参数进行片元着色Fragment Shader得到纹理Texture
包括纹理采样Texture Sampling技术,例如Mipmaps、抗锯齿,处理不好就可能发生走样。
-
输出像素组成的图像
显卡
SIMD
单指令多数据
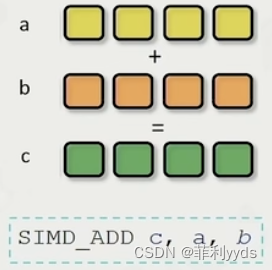
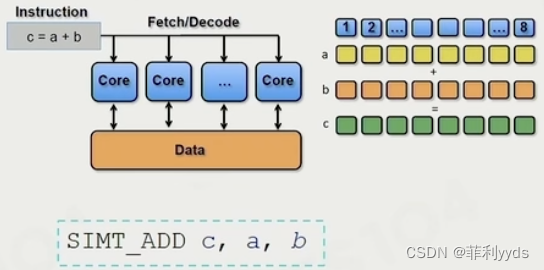
SIMT
单指令多线程
NVIDIA Fermi架构
-
GPC
图形处理簇(Graphics Processing Cluster),实现渲染管线(计算-光栅化-着色-纹理)的硬件部分
-
SM
流处理器(Streaming Multiprocessor),运行CUDA核心的GPU部分
-
CUDA Core
包含浮点、整型单元,并行计算数据
-
Texture Units
纹理单元,获取纹理并对其进行滤波
-
Warp
一组线程
关于GPU的优化策略:
为了减少时延,减少CPU和GPU之间通讯次数,GPU尽可能不要回调CPU。
关注cache效率,谨防纽曼瓶颈(CPU GPU运算够快,缓存速度不够)
一些Bounds(瓶颈):
内存Bounds, ALU Bounds,TMU(纹理映射单元)Bound,BW(带宽)Bound
可渲染物体Renderable
Mesh Primitive
网格由三角形组成,每个三角形由三个顶点的索引组成。(使用索引节约空间Index Buffer),顶点数据统一由Vertex Buffer管理。
每个顶点Vertex由position, color和normal组成
Materials
- Material Models: Phong模型,PBR(基于物理的渲染),Burley次表面
- Texture纹理:数据形式呈现
- Shader着色器:一段代码,可以实现上述材质模型
渲染过程
-
通过进行坐标系变换得到屏幕空间坐标
-
SubMesh——子网格,一个GO中不同的部分可能使用不同材质(例如头盔、皮肤、服饰、鞋子),这时需要将Mesh切分为多个SubMesh.
-
Resource Pool——为了避免不同GO使用同一资源浪费空间,将Mesh,Shader Texture分别放到不同Pool中。然后GO从资源池中引用这些资源,避免了重复存储。GO对这些资源的引用称为Instance实例。
-
GPU Batch Rendering——GPU每次Drawcall时尽量将引用资源相同的实例分组在一起进行渲染,可以提高效率。
可见性裁剪Visibility Culling
我们只渲染处于视锥范围内的GO,在范围外的则被裁切。用到的数据结构和算法有BVH和如下一些方式。另外,鼓励使用新的算法和GPU硬件并行实现。
Bound包围体
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-bsV6rM5o-1681375629658)(/Users/g/Library/Application Support/typora-user-images/Screenshot 2023-04-13 at 14.34.18.png)]](https://i-blog.csdnimg.cn/blog_migrate/def146ee068638c3b2f41b53b2819ad2.png)
AABB——世界坐标轴对齐包围盒(只需维护对角线两个端点的世界坐标)
OBB——GO坐标轴对齐包围盒
Convex Hull——凸包
PVS(Potentially Visibility Set) 潜在可见集
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-RHzLhzMP-1681375629659)(/Users/g/Library/Application Support/typora-user-images/Screenshot 2023-04-13 at 15.08.12.png)]](https://i-blog.csdnimg.cn/blog_migrate/1e140ef01b84c7e5389b84db3f1d816b.png)
从每个Portal(类比于门窗)看去,最多能看到哪些房间?如果只能看到这几个房间,则只需要渲染这几个房间中的物体。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-LaA3gz2V-1681375629659)(/Users/g/Library/Application Support/typora-user-images/Screenshot 2023-04-13 at 15.09.48.png)]](https://i-blog.csdnimg.cn/blog_migrate/6d8be98f512ffa6f9043b471f5d0eb48.png)
优点:
-
效率远高于BSP和八叉树
-
灵活、兼容性好
-
可以用于预加载资源。
深度
预先计算每个像素待渲染GO的深度,如果同一像素有深度较小和较大的一方同时出现,则深度较大的渲染流程可以被跳过,甚至该GO都不再被渲染。
纹理压缩
传统的图片压缩格式(JPG、PNG)
- 压缩率高
- 随机访问性能差
游戏中的纹理压缩算法:
- 编解码速度快
- 随机访问强
- 压缩率和视觉效果都有保证
常用的纹理压缩算法:
一种经典算法是基于4*4的块进行压缩:
- 先根据明暗度排序
- 记录下最亮和最暗的像素颜色信息
- 压缩后只记录了每个像素的明度级别
- 最后通过最亮和最暗像素的插值来还原颜色
| Modern | Old | |
|---|---|---|
| PC | BC7 | DXTC |
| Mobile | ASTC | ETC/PVRTC |
建模工具软件
-
多面体建模工具——3dsMax MAYA Blender
-
雕刻工具(更为灵活自由)——ZBrush
-
扫描工具
-
程序生成建模工具(结合AI)——Houdini、Unreal
基于簇的模型管线——Cluster-Based Mesh Pipeline
簇是一些三角形的渲染单元。有利于创作者增加细节,是引擎未来主要的发展方向之一。
GPU驱动的渲染管线(2015)
- 网格簇渲染:每次drawcall生成随机数量的网格,GPU每次对簇进行排序,按照簇的边缘进行裁剪
几何渲染管线架构(2021)
渲染单元按如下方式划分:
- Batch: 一次drawcall由多个surfs组成
- Surf: 基于材质的子网格,包含很多clusters
- 每个Cluster由64个三角形组成
UE——Nanite
像素级的网格渲染,基于以下技术实现:
- 带有连续边界的分级LOD(多层次细节,降低不重要GO的细节和面数)
- 无需硬件支持,通过GPU的计算着色器线程(而非任务着色器)预先计算的BVH树实现分级cluster culling
总结
- 游戏引擎设计和硬件架构设计紧密相关
- 子网格常用于带有多个材质的模型
- 使用裁剪算法尽量减少绘制的GO
- GPU快速发展,使得大量工作转向GPU,称之为GPU-Driven
Piccolo引擎源码简介
build好之后,引擎源码均在./build目录下
-
PiccoloPreCompile:自动生成,类似于UE的反射机制,自动反射出资源读取方式
-
PiccoloShaderCompile:着色器,使用GLSL,编译出来的文件需要单独管理,故单独分层
-
PiccoloRuntime:核心层、功能层、平台层、资源层
-
PiccoloEditor:编辑器
Asset资产在./engine/asset目录下

















 603
603

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









