




 本文详细介绍了双向带头循环链表的概念、基本接口,包括头插、尾插、删除等操作,并对比了与顺序表的优缺点。重点讨论了为何一级指针用于带头链表,而二级指针用于无头链表。
本文详细介绍了双向带头循环链表的概念、基本接口,包括头插、尾插、删除等操作,并对比了与顺序表的优缺点。重点讨论了为何一级指针用于带头链表,而二级指针用于无头链表。
链表
概念:链表是一种物理存储结构上可能非连续、可能非顺序的存储结构,数据元素的逻辑结构是连续存放的
以下是个单链表

链表分类
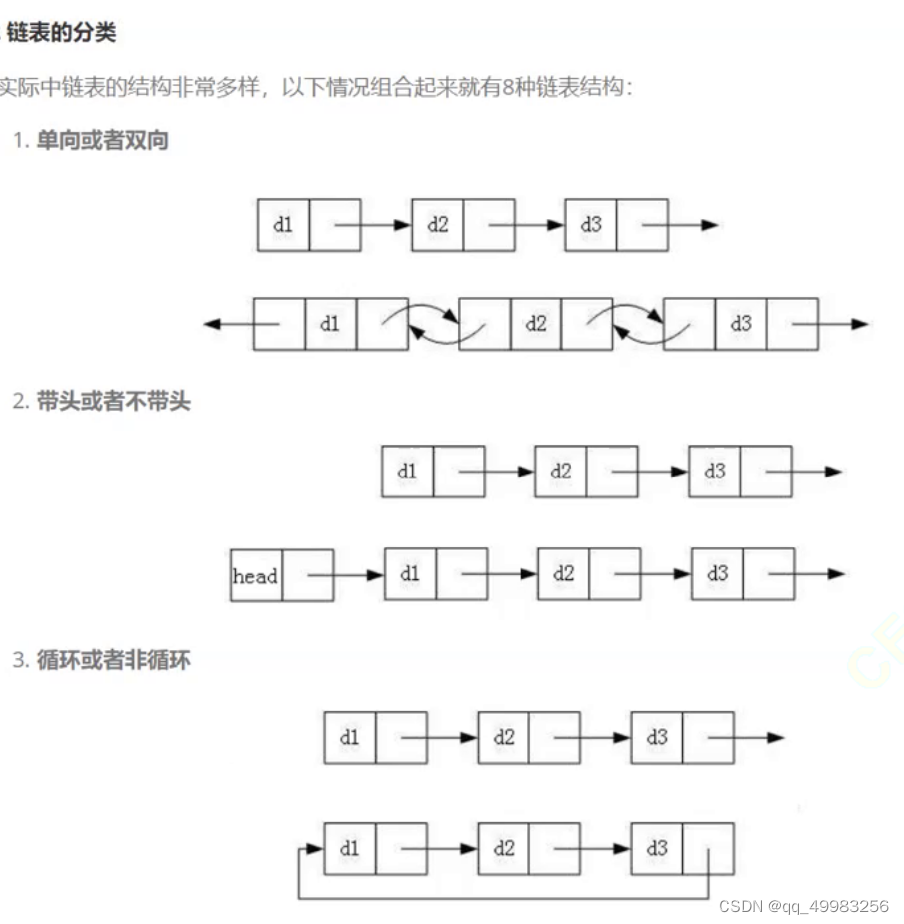
常用
1. 无头单向非循环链表:结构简单,一般不会单独用来存数据。实际中更多是作为其他数据结构的子结构,如哈希桶、图的邻接表等等。
2. 带头双向循环链表:结构最复杂,一般用在单独存储数据。实际中使用的链表数据结构,都是带头双向循环链表。另外这个结构虽然结构复杂,但是使用代码实现以后会发现结构会带来很多优势
双向循环链表可以处理大规模串口通信。
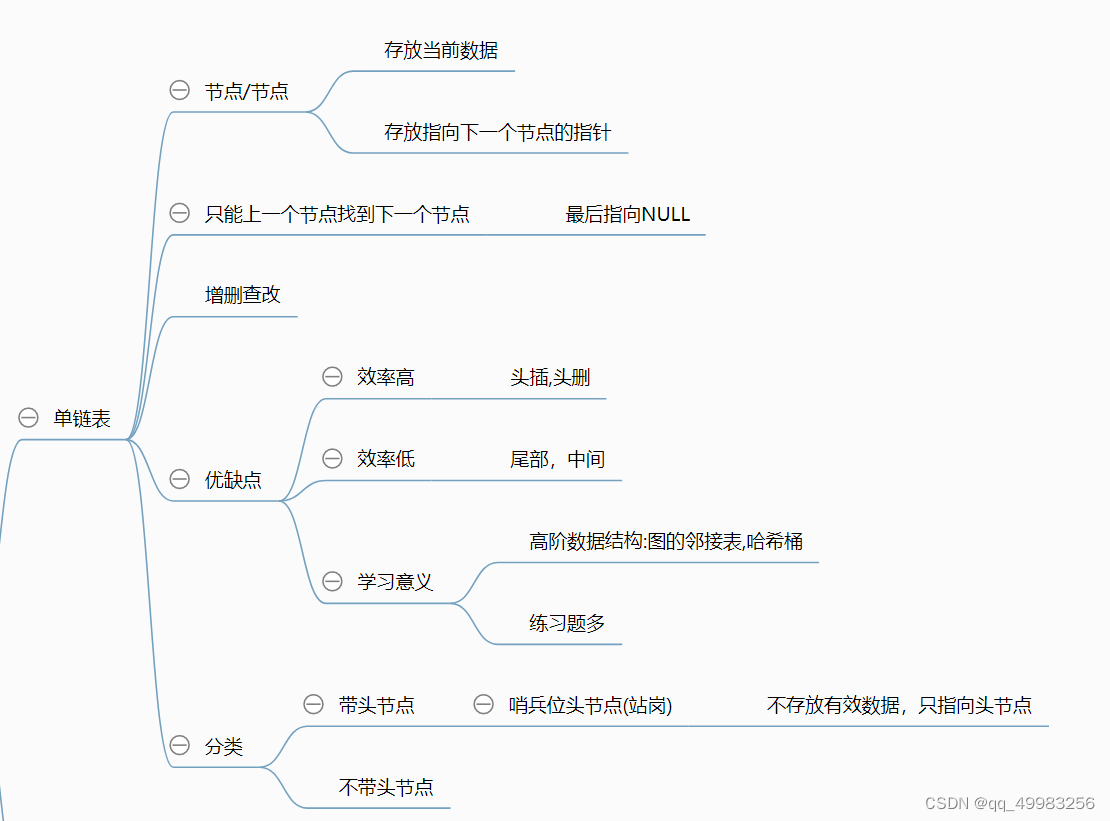
单链表基本接口
尾插与尾删
void SListPrintf(SListNode* phead)
{
//assert(phead);
//空链表也可以打印,直接就打印NULL了
SListNode* cur = phead;
while (cur != NULL)//当next==NULL时说明单链表到头了
{
printf("%d->", cur->data);//打印数据
cur = cur->next;//把next中的地址赋给cur,使得cur跳转到那个地址
}
printf("NULL\n");
}
SListNode* BuySListNode(int x)
{
SListNode* newcode = (SListNode*)malloc(sizeof(SListNode));
if (newcode == NULL)
{
printf("malloc fail\n");
exit(-1);
}
else//开辟一个新节点
{
newcode->data = x;//存储要存储的数据
newcode->next = NULL;//最后一个节点指向NULL;
}
return newcode;//返回这个新节点的地址
}
void SListPushBack(SListNode** phead,int x)//尾插
{
assert(phead);
SListNode* newcode = BuySListNode(x);//创建新节点
if (NULL == *phead)//如果phead为空链表
{
//直接把新创建的节点赋值给phead;
*phead = newcode;
}
else
{
//找尾
SListNode* tail = *phead;
while (tail->next != NULL)
{
tail = tail->next;
}
//找到了原链表最后一个节点
tail->next = newcode;//把新节点地址存给结构体指针
}
}
关于为什么使用SListNode**
//要改变int,就要传int*
//要改变int*,就要传int**,int *也是一种类型,要传这种类型对应的数据的地址才能改变这种类型对应的数据
函数那边如果是一级指针,slist作为一个实参传给那边的形参,那边的改变是不会影响slist的
这里传入的是SListNode**,因为我们要改变SListNode*里面的内容
当然最好函数里面写pphead,我这里写的不是很规范

测试代码
void test1()
{
SListNode* slist = NULL;//指针类型,传指针需要二级指针接受
int i = 0;
for (i = 0;i < 4;i++)
{
SListPushBack(&slist, i);
//实参传给形参,形参改变不影响实参
//要改变int,就要传int*
//要改变int*,就要传int**
函数那边如果是一级指针,slist作为一个实参传给那边的形参,那边的改变是不会影响slist的
这里传入的是SListNode**,因为我们要改变SListNode*里面的内容
//所以。后面的函数接口,都需要用到二级指针
}
SListPrintf(slist);//打印并不需要改变实参
}
void SListPopBack(SListNode** phead)//尾删
{
assert(phead);
size_t flag = 0;
//空
if ((*phead) == NULL)//第一个为空
{
printf("SListPopBack失败,链表为空\n");
return;//空就啥也不干
}
//一个节点
else if ((*phead)->next == NULL)
{
free(*phead);//释放掉某个节点
*phead = NULL;//该节点置空
return;
}
//双指针解决尾删时找不到上一个节点的问题,常用
//极端思维,一个节点?
else
{
SListNode* prev = *phead;//用来指向tail的前一个,以释放其后面的,置空
SListNode* tail = *phead;//一个节点用来找NULL
while (tail->next != NULL)
{
prev = tail;
tail = tail->next;
}
free(tail);
prev->next = NULL;//符合单链表规定,最后为NULL
如果这样写
/*两次指向,这样恰好能使tail指向要删除节点的前方
//如果是一个节点,直接释放if ((*phead)->next == NULL)
{
free(*phead);
*phead = NULL;
return;
}
//新创建的指针只是对*phead的拷贝,对它改变没用,需要对结构体的内容改变!!!
SListNode* tail = *phead;
//会导致很严重的访问内存失败问题
while (tail->next->next != NULL)//如果是一个节点的话会导致程序异常退出,但还是会删除这个节点
{
tail = tail->next;
}
free(tail->next);//释放掉tail指向的下一个节点的地址
tail->next = NULL;*/}
}
头插与头删
void SListPushFront(SListNode** phead, int x)//头插
{
assert(phead);
SListNode* newcode = BuySListNode(x);
if (NULL == *phead)//如果phead为空链表,直接插上就行
{
//把新创建的节点赋值给phead;
*phead = newcode;
}
else
{
newcode->next = *phead;//将新节点的next指向*phead这第一个节点
*phead = newcode;//把新节点的地址传给*phead
//最后都是改变的*phead
}
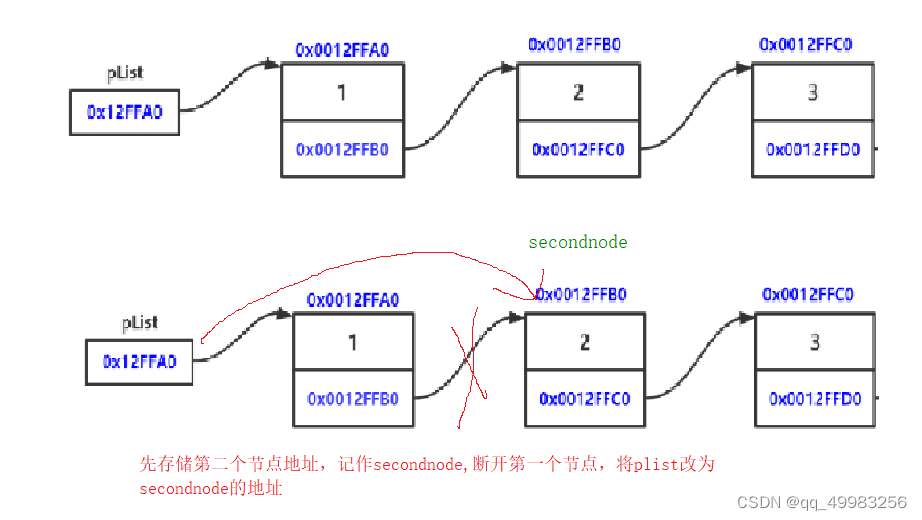
}void SListPopFront(SListNode** phead)//头删
{
assert(phead);
//空
if ((*phead) == NULL)//第一个为空
{
printf("SListPopFront失败,链表为空\n");
return;//空就啥也不干
}
//非空(头删不会去找下一个节点),因此不需要区分是不是一个节点
/*else if ((*phead)->next == NULL)
{
free(*phead);
*phead = NULL;
return;
}*/
else
{
//将指针指向第二个节点
SListNode* secondnode = (*phead)->next;
/*SListNode* firstnode = *phead;
firstnode->next = NULL;*/
free(*phead);
(*phead) = secondnode;//把secondnode指向的第二个节点赋值给slist;
}
}
查找
SListNode* SListFind(SListNode* phead, int x)//查找
{
if (NULL==phead)//不要写一个=
//先写左值,不要先写右值
{
//说明链表为空,直接返回
printf("链表为NULL\n");
return NULL;
}
else
{
//遍历链表
SListNode* prev = phead;
while (prev != NULL)//说明没到头
{
if (prev->data == x)
{
return prev;//返回tmp这个节点
}
prev = prev->next;
}
printf("没找到%d\n", x);
}
return NULL;
}
任意位置插入与删除
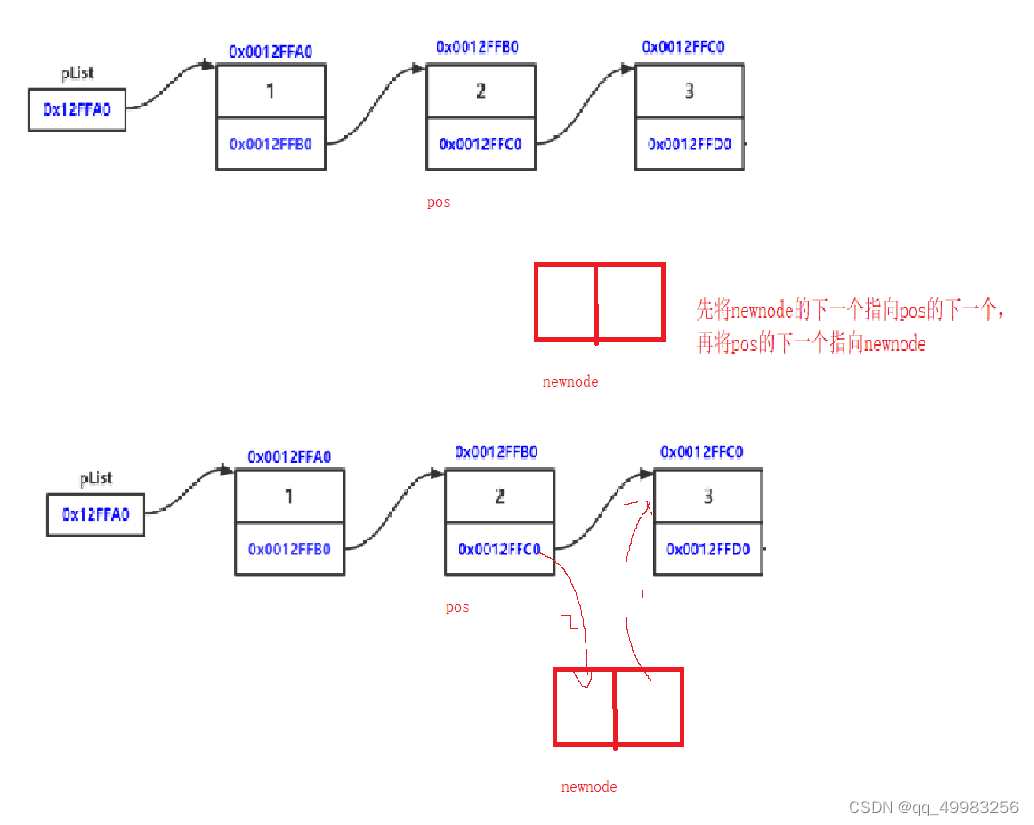
void SListInsertAfter(SListNode** phead, SListNode* pos, int x)//pos之后插入
{
assert(phead);
//记录下,pos下一个节点
SListNode* next = pos->next;//记录下很重要,否则可能找不到下一个节点的地址
SListNode* newcode = BuySListNode(x);
pos->next = newcode;
newcode->next = next;//如果有一个next指针,则不需要关注两者的顺序,如果不写next的指针,则一定要关注顺序
}
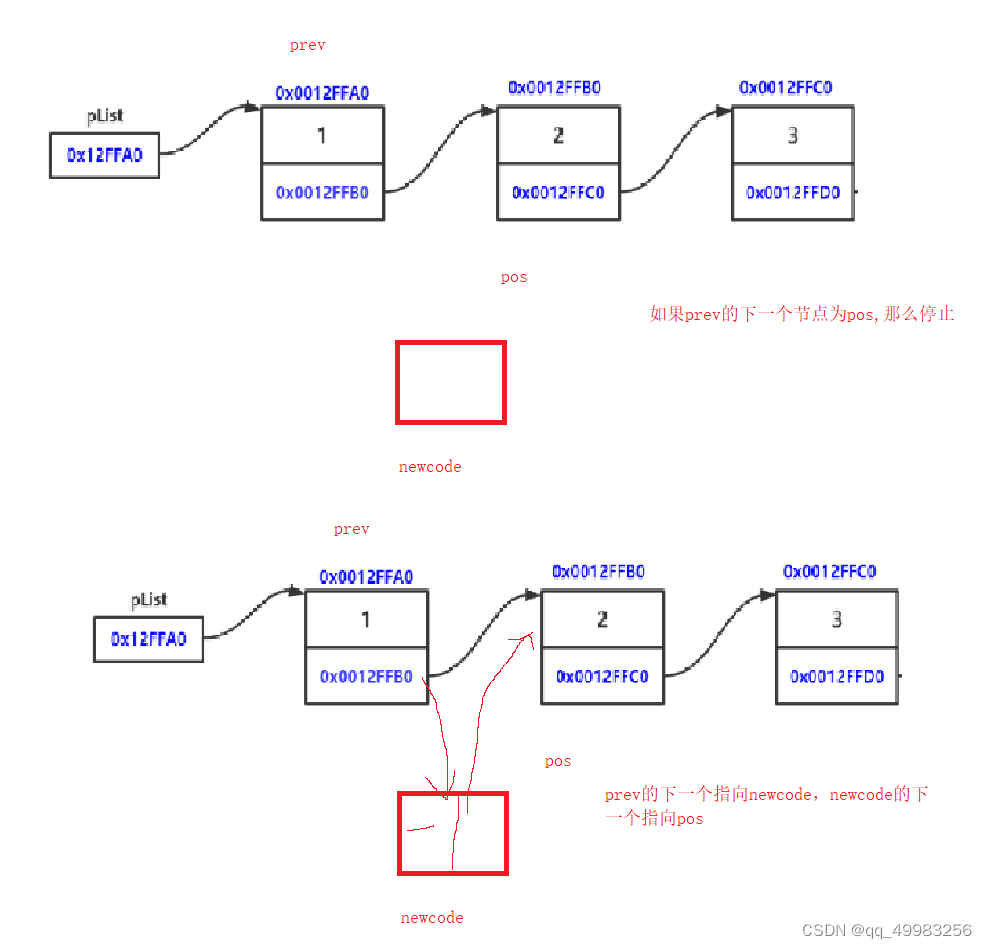
void SListInsertBefore(SListNode** phead, SListNode* pos, int x)//之前插入
{
assert(phead);
//assert(pos);
if (NULL == pos)//如果找不到pos的位置,说明找不到要插入的位置
{
printf("找不到pos的位置\n");
return;
}
SListNode* prev = (*phead);//1:pos是第一个节点
if (prev == pos)//说明地址相同是第一个节点
{
/* newcode->next = pos;
tmp = newcode;//局部变量被销毁了*/
SListPushFront(phead, 100);//复用头插}
else
{
//2:pos不是第一个节点
//创建一个要插入的新节点
//链表的插入需要先断开后插入
//找到节点前一个节点
while (prev->next != pos)
{
prev = prev->next;
}
SListNode* newcode = BuySListNode(x);//把tmp的节点指向新创建的节点
prev->next = newcode;
newcode->next = pos;
}
}
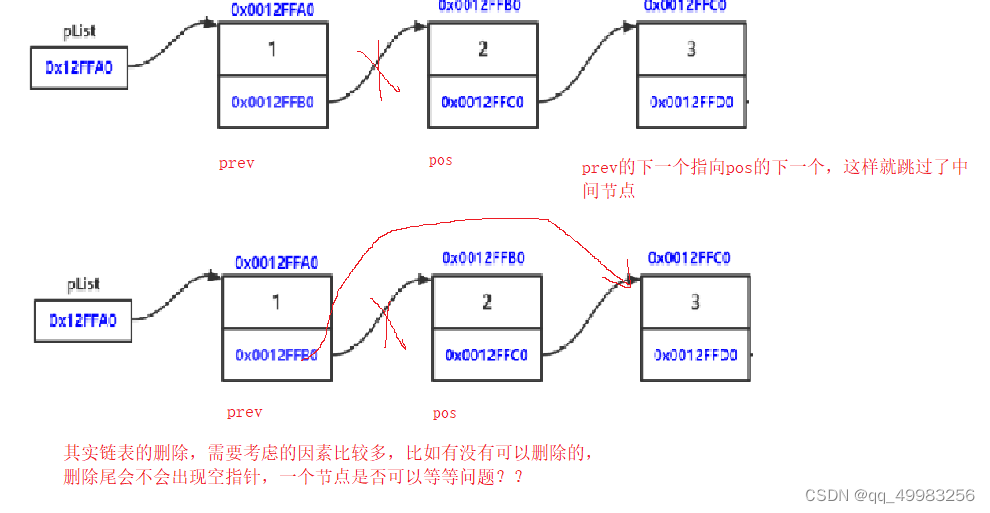
void SListErase(SListNode** phead, SListNode* pos)//删除
{
//删除是删除pos位置处的元素
assert(phead);
//1:删除位置不知道
if (NULL == pos)//如果找不到pos的位置,说明找不到要插入的位置
{
printf("链表为空,删除失败\n");
return;
}
//2:头删
else if (*phead == pos)
{
SListPopFront(phead);
}
//3:删中间和结尾
else
{
//释放链表,保存下一个链表的节点
SListNode* prev = *phead;
while (prev->next != pos)
{
prev = prev->next;
}
prev->next = pos->next;//跳过要删除的元素
//pos->next = NULL;//要删除的节点的指向置空
free(pos);
pos = NULL;
}
}
void SListEraseAfter(SListNode** phead, SListNode* pos)//删除pos之后的节点
{
assert(pos);
//没有头删了
SListNode* next = pos->next;
//如果next为空?说明pos在尾节点
if (NULL == next)
{
printf("尾节点之后没节点了\n");
return;
}
pos->next = next->next;
free(next);
next = NULL;
}
销毁单链表
void SListDestory(SListNode** phead)//销毁
{
assert(phead);
//一个一个释放
SListNode* cur = *phead;
while (cur != NULL)
{
SListNode* next = cur->next;//循环作用free(cur);
//free cur之后cur就不能指向next了
cur = next;
}
*phead = NULL;
}
带哨兵位的单链表

哨兵位的数据hi随机的,可以是任意数。
带头双向循环链表
基本接口
// 2、带头+双向+循环链表增删查改实现
typedef struct ListNode
{
int _data;
struct ListNode* next;
struct ListNode* prev;
}ListNode;
// 创建返回链表的头结点.
ListNode* ListCreate();
// 双向链表销毁
void ListDestory(ListNode* plist);
// 双向链表打印
void ListPrint(ListNode* plist);
// 双向链表尾插
void ListPushBack(ListNode* plist, int x);
// 双向链表尾删
void ListPopBack(ListNode* plist);
// 双向链表头插
void ListPushFront(ListNode* plist, int x);
// 双向链表头删
void ListPopFront(ListNode* plist);
// 双向链表查找
ListNode* ListFind(ListNode* plist, int x);
// 双向链表在pos的前面进行插入
void ListInsert(ListNode* pos, int x);
// 双向链表删除pos位置的节点
void ListErase(ListNode* pos);
重点!!!!
解释一下为什么这里传入一级指针。而单链表那里传入二级指针。
首先思考,我们为什么要传入指针,因为我们要通过指针改变指针所指向的内容。
带头双向循环链表这里因为我们定义的是个带哨兵位的链表,开辟好一块空间,找到一个指针指向开好的这块空间(结构体),是不是就可以改变他的内容了?
单链表那里,定义一个结构体指针,因为自身结构的原因,比如头插头删,需要改变这个结构体指针的位置,因此需要传入结构体的指针的地址。
简单的说,带头的链表,已经开好了一块空间,而这个头(这里不是指链表头)的地址不需要发生改变了。
不带头的链表,因为自身结构,需要改变结构体指针的地址(头节点的地址)。
具体实现
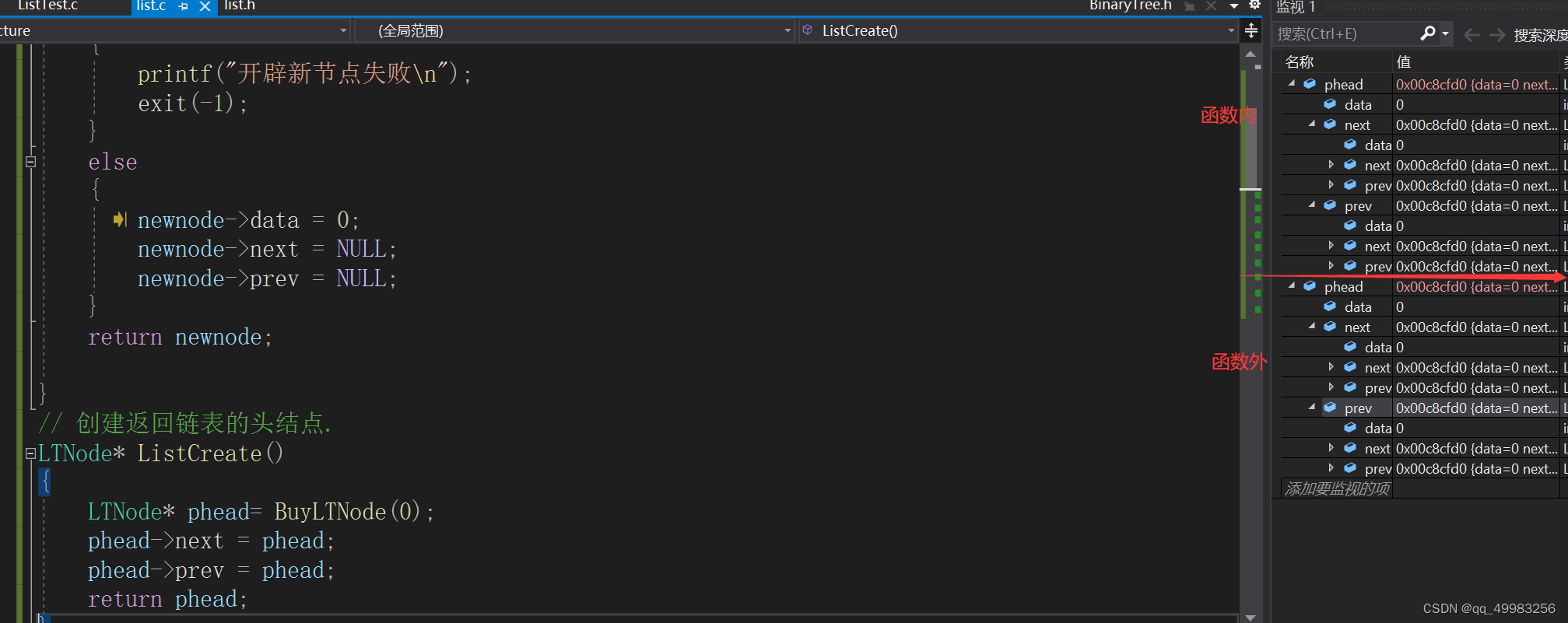
初始化带哨兵位的双向循环链表
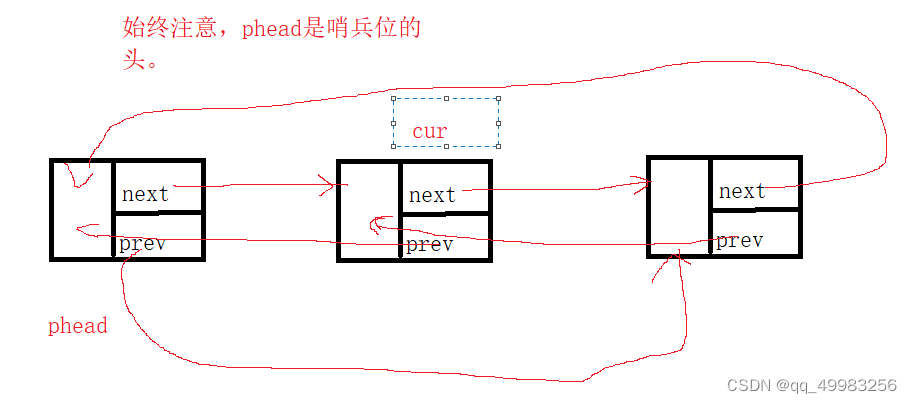
LTNode* BuyLTNode(int x) { LTNode* newnode = (LTNode*)malloc(sizeof(LTNode)); if (newnode==NULL) { printf("开辟新节点失败\n"); exit(-1); } else { newnode->data = 0; newnode->next = NULL; newnode->prev = NULL; } return newnode; } // 创建返回链表的头结点. LTNode* ListCreate() { LTNode* phead= BuyLTNode(0); phead->next = phead;//只有哨兵位的时候,哨兵位的next指向自己 phead->prev = phead; return phead; }堆上申请的节点,不会随着函数的退出而呗销毁
// 双向链表查找 LTNode* ListFind(LTNode* phead, int x) { assert(phead); LTNode* cur = phead->next; while (cur->next != phead) { if (cur->data == x)//查找第一个元素 { return cur; } cur = cur->next; } return NULL; }
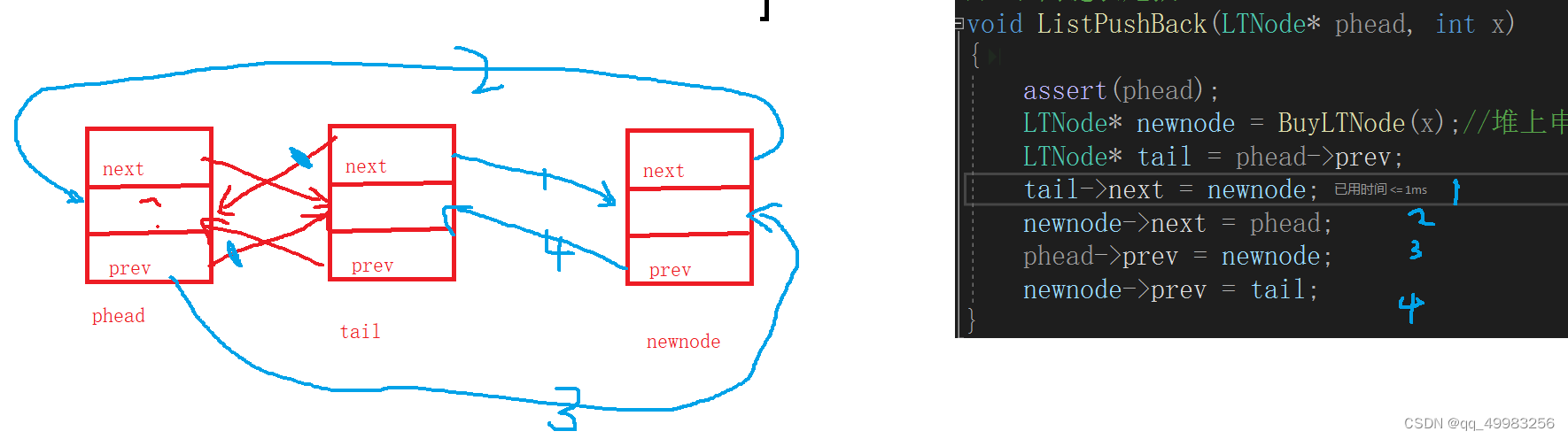
// 双向链表打印 void ListPrint(LTNode* phead) { assert(phead); LTNode* cur = phead->next; while (cur != phead) { printf("%d ", cur->data); cur = cur->next; } printf("\n"); } // 双向链表尾插 void ListPushBack(LTNode* phead, int x) { assert(phead); LTNode* newnode = BuyLTNode(x);//堆上申请的节点,不会随着函数的退出而被销毁 LTNode* tail = phead->prev; tail->next = newnode; newnode->next = phead; phead->prev = newnode; newnode->prev = tail; }
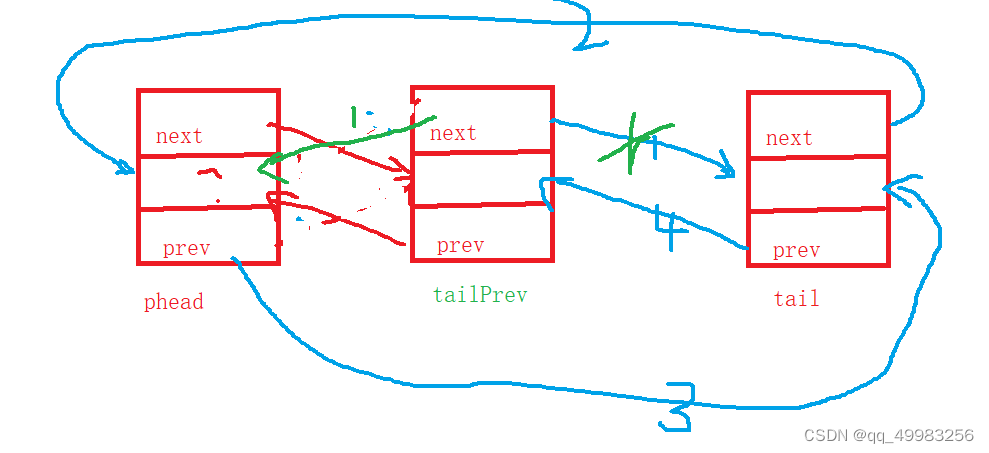
// 双向链表尾删 void ListPopBack(LTNode* phead) { assert(phead); if (phead->next == phead) { printf("已经没有可以删除的节点了\n"); return; } LTNode* tail = phead->prev; LTNode* tailPrev = tail->prev; free(tail); tail = NULL; tailPrev->next = phead; phead->prev = tailPrev; }
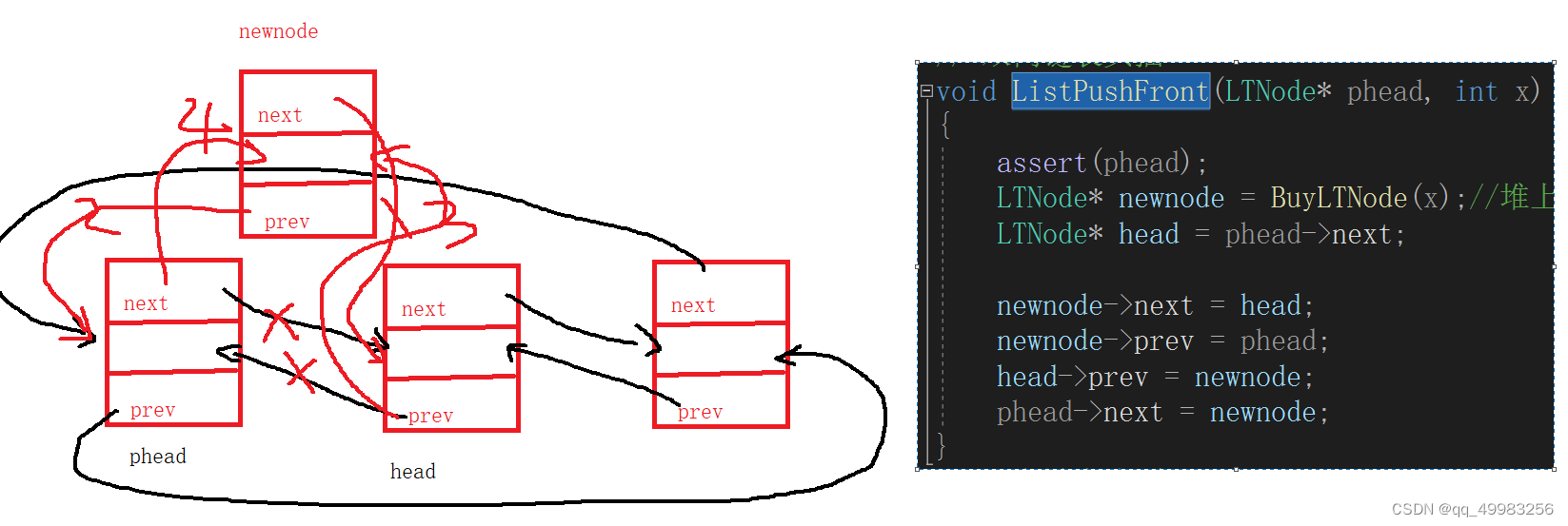
// 双向链表头插 void ListPushFront(LTNode* phead, int x) { assert(phead); LTNode* newnode = BuyLTNode(x);//堆上申请的节点,不会随着函数的退出而被销毁 LTNode* head = phead->next; newnode->next = head; newnode->prev = phead; head->prev = newnode; phead->next = newnode; }
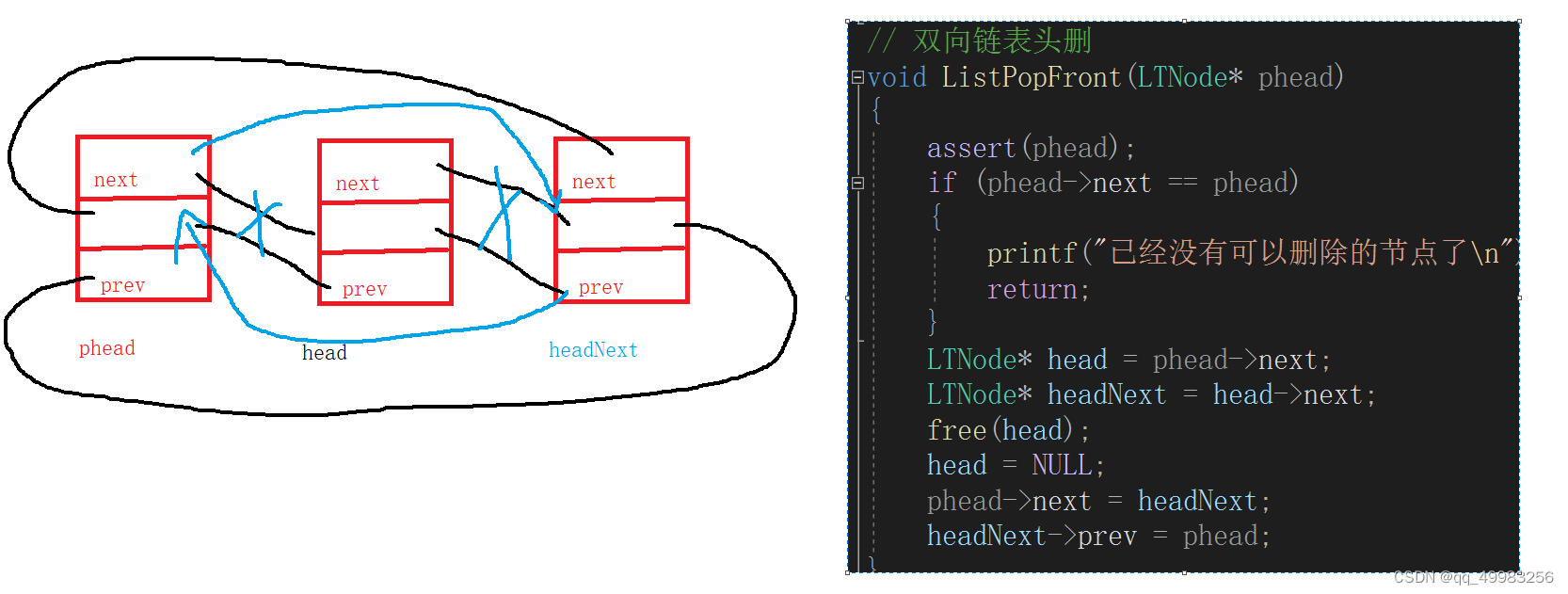
// 双向链表头删 void ListPopFront(LTNode* phead) { assert(phead); if (phead->next == phead) { printf("已经没有可以删除的节点了\n"); return; } LTNode* head = phead->next; LTNode* headNext = head->next; free(head); head = NULL; phead->next = headNext; headNext->prev = phead; }
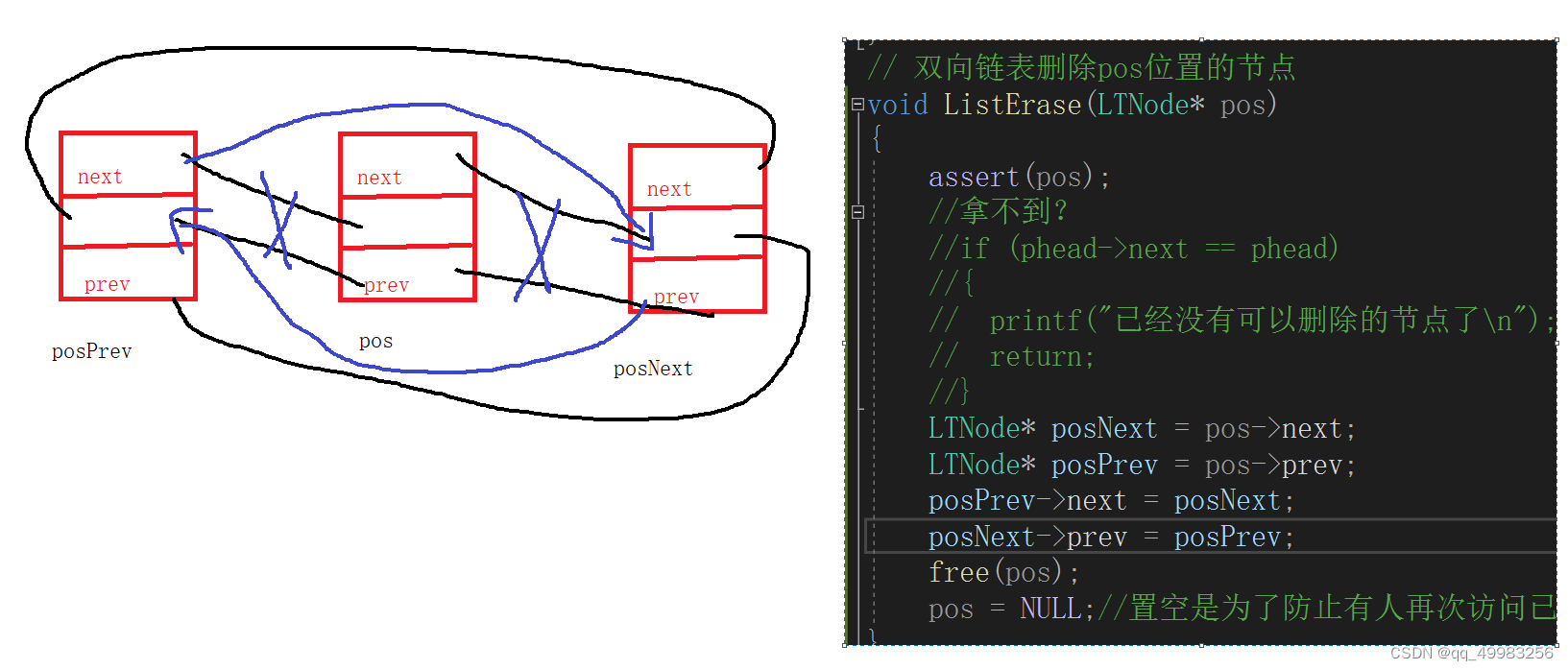
// 双向链表删除pos位置的节点 void ListErase(LTNode* pos) { assert(pos); //拿不到? //if (phead->next == phead) //{ // printf("已经没有可以删除的节点了\n"); // return; //} LTNode* posNext = pos->next; LTNode* posPrev = pos->prev; posPrev->next = posNext; posNext->prev = posPrev; free(pos); pos = NULL;//置空是为了防止有人再次访问已经被释放的空间 }
最后!
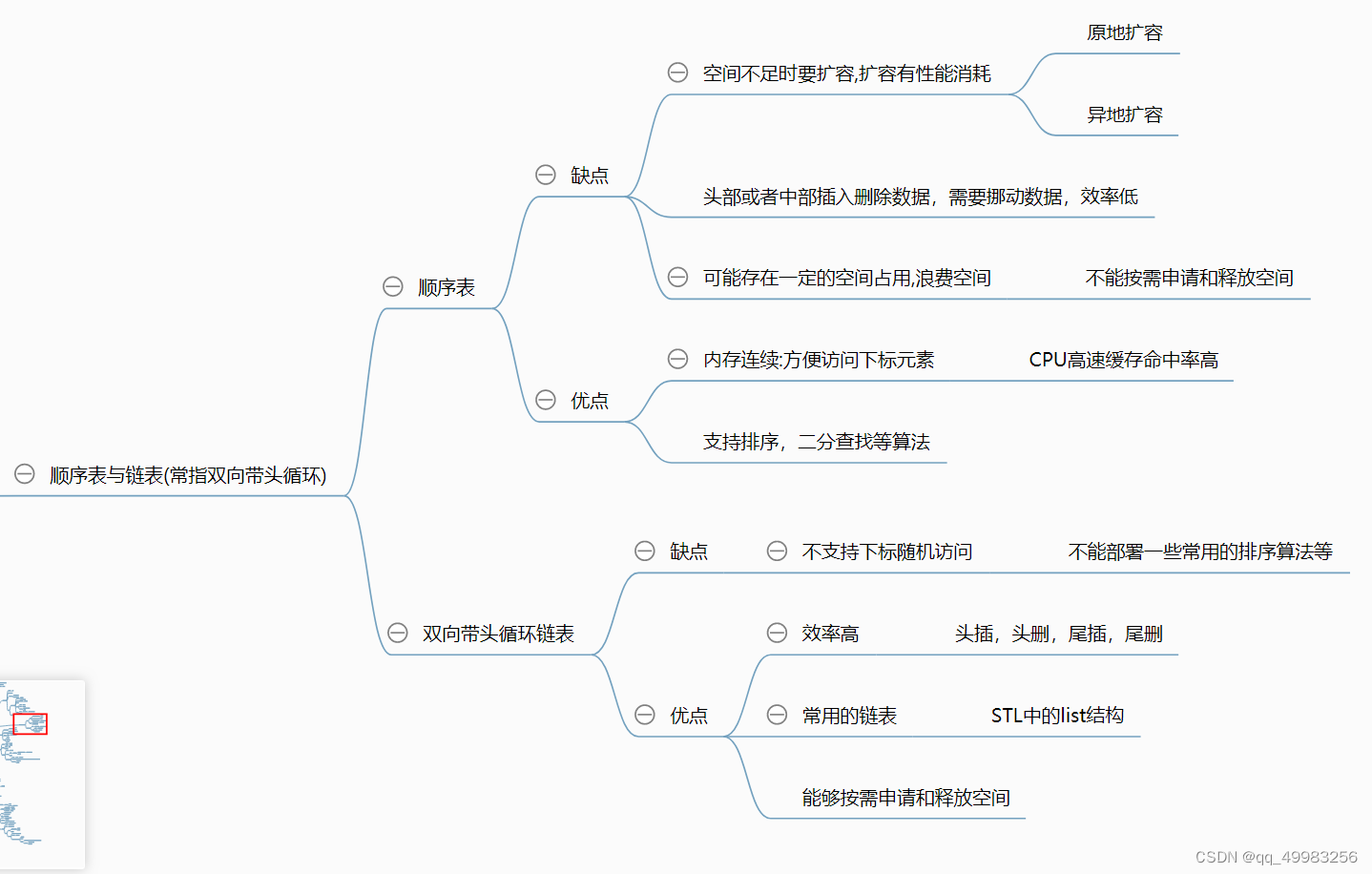
总结一下链表(指双向带头循环链表)和顺序表的优缺点
如何理解CPU高速缓存命中率高?
先看下存储器的存储结构
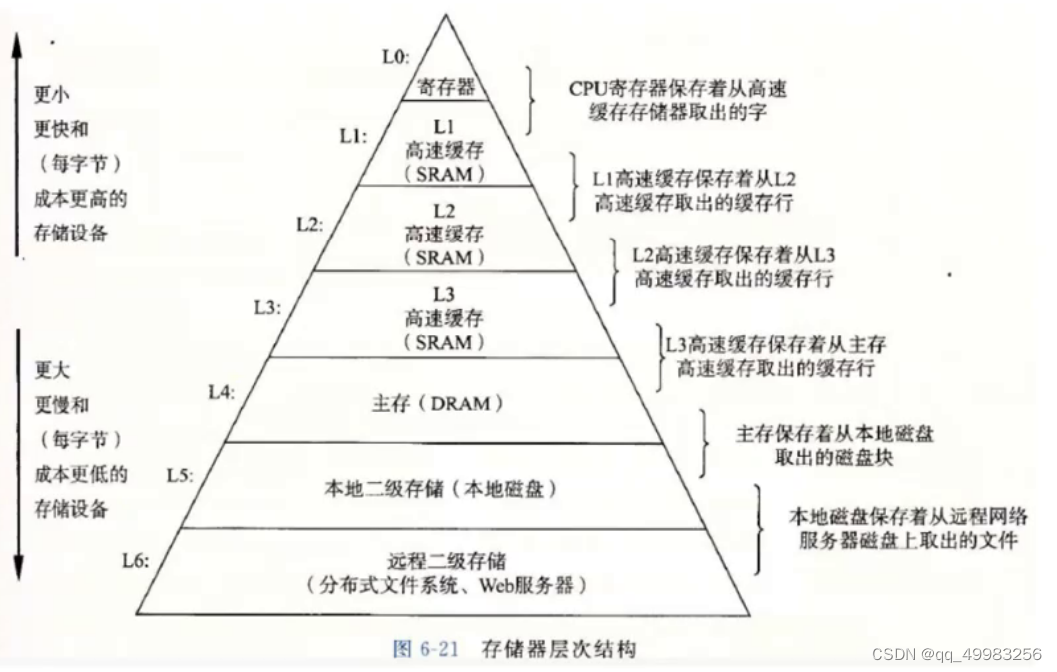
我们平常写的程序是在主存上面(内存),内存是带电存储的,掉电就会丢失。保存下来的数据存储到本地磁盘,也就是硬盘。
编写好的代码,会进入高速缓存(三级缓存), cpu能够在程序中读到想要的数据称之为命中,不命中则继续从内存加载程序到高速缓存中。还有一点,加载数据一般连同想要的附近数据一起加载。
了解这些,就可以解释为什么数组CPU高速缓存命中率高了。
数组存储是连续的,在cpu未命中的时候,会从内存的一块连续空间中加载到高速缓存区,这样cpu可以命中数组中的某个数据,比如arr[0],并且arr[1]与arr[0]是连续存储的,arr[1]也被加载到高速缓存区了。
然而链表。随机存储,可能会命中好一点,最坏的情况是一个节点就要加载缓存一次,也就是命中率不高

















 1562
1562

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









