







前言
随着无人机技术的发展和深度学习的进步,无人机在环境监测和垃圾管理中的应用越来越广泛。YOLO系列模型因其实时性和高精度在目标检测领域被广泛应用。本项目旨在开发一个基于YOLO的无人机垃圾分割检测系统,该系统能够利用无人机拍摄的图像进行垃圾的自动识别和分割,为城市环境管理和垃圾分类提供技术支持。通过使用YOLOv8模型,我们能够实现对无人机图像中垃圾目标的快速检测和精确分割,这对于提高垃圾处理效率和减少环境污染具有重要意义。
基于此项目,设计了一个使用Pyqt5库来搭建页面展示系统。本系统支持的功能包括训练模型的导入、初始化;置信度与IOU阈值的调节、图像上传、检测、可视化结果展示、结果导出与结束检测;视频的上传、检测、可视化结果展示、结果导出与结束检测;摄像头的上传、检测、可视化结果展示与结束检测;已检测目标信息列表、位置信息;以及推理用时。本博文提供了完整的Python代码和使用教程,适合新入门的朋友参考,完整代码资源文件请转至文末的下载链接。
优势
-
高准确性:YOLO模型以其先进的特征提取网络和改进的检测算法,在保证高准确率的同时,提升检测速度。
-
实时性:系统能够快速处理图像数据,提供实时的垃圾检测和分割结果,适用于需要快速响应的环境监测场景。
-
鲁棒性:YOLO模型在不同光照和复杂背景下均能保持较高的识别率和分割精度,显示出良好的鲁棒性。
-
灵活性:YOLO模型提供了不同大小的版本,可以根据无人机的计算资源和性能要求进行选择,以实现最佳的性能平衡。
应用前景
-
环境监测:系统可以用于无人机在城市和自然环境中的垃圾监测,提供实时数据支持,帮助制定有效的垃圾清理策略。
-
垃圾分类:通过精确的图像分割,系统能够辅助垃圾分类工作,提高垃圾分类的自动化水平和效率。
-
数据分析:收集的垃圾检测数据可用于分析垃圾分布和种类,为城市环境管理和政策制定提供数据支持。
-
环境保护:系统有助于提高垃圾处理的及时性和准确性,减少环境污染,促进可持续发展。
-
技术拓展:基于YOLO的无人机垃圾检测技术将为环境监测和治理工作提供新的思路和方法,有望在未来实现更广泛的应用。
一、软件核心功能介绍及效果演示
软件主要功能
-
支持
图片、图片批量、视频及摄像头进行检测,同时摄像头可支持内置摄像头和外设摄像头; -
可对
检测结果进行单独分析,并且显示单个检测物体的坐标、置信度等; -
界面可实时显示
目标位置、检测结果、检测时间、置信度、检测结果回滚等信息; -
支持
图片、视频及摄像头的结果保存,将检测结果保持为excel文件;
视频演示
无人机垃圾分割检测系统
图片检测演示
-
点击
打开图片按钮,选择需要检测的图片,或者点击打开文件夹按钮,选择需要批量检测图片所在的文件夹,操作演示如下: -
点击表格中的指定行,界面会显示该行表格所写的信息内容。
视频检测演示
-
点击
视频按钮图标,打开选择需要检测的视频,在点击开始运行会自动显示检测结果。再次点击停止按钮,会停止检测视频。 -
点击表格中的指定行,界面会显示该行表格所写的信息内容。
摄像头检测演示
-
在
选择相机源中输入需要检测的摄像头(可以是电脑自带摄像头,也可以是外接摄像头,视频流等方式),然后点击摄像头图标来固定选择的推理流方式,最后在点击开始运行即可开始检测,当点击停止运行时则关闭摄像头检测。 -
点击表格中的指定行,界面会显示该行表格所写的信息内容。
检测结果保存
点击导出数据按钮后,会将当前选择的图片【含批量图片】、视频或者摄像头的检测结果进行保存为excel文档,结果会存储在output目录下。
二、环境搭建
创建专属环境
conda create -n yolo python==3.8
激活专属环境
conda activate yolo
安装torch-GPU库
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple "torch-2.0.1+cu118-cp38-cp38-win_amd64.whl"
安装torchvision-GPU库
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple "torchvision-0.15.2+cu118-cp38-cp38-win_amd64.whl"
安装ultralytics库
pip install ultralytics -i https://pypi.tuna.tsinghua.edu.cn/simple
测试环境
yolo predict model=yolov8n.pt source='https://ultralytics.com/images/bus.jpg'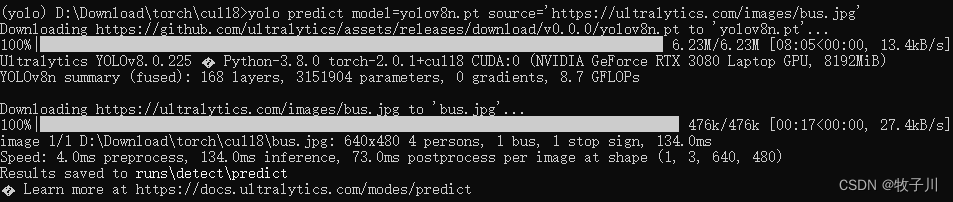

此时就表明环境安装成功!!!
安装图形化界面库 pyqt5
pip install pyqt5 -i https://pypi.tuna.tsinghua.edu.cn/simple
pip install pyqt5-tools -i https://pypi.tuna.tsinghua.edu.cn/simple三、算法原理
YOLOv8是一种前沿的深度学习技术,它基于先前YOLO版本在目标检测任务上的成功,进一步提升了性能和灵活性,在精度和速度方面都具有尖端性能。在之前YOLO 版本的基础上,YOLOv8 引入了新的功能和优化,使其成为广泛应用中各种物体检测任务的理想选择。主要的创新点包括一个新的骨干网络、一个新的 Ancher-Free 检测头和一个新的损失函数,可以在从 CPU 到 GPU 的各种硬件平台上运行。
YOLOv8目标检测算法具有如下的几点优势:
(1)更友好的安装/运行方式;
(2)速度更快、准确率更高;
(3)新的backbone,将YOLOv5中的C3更换为C2F;
(4)YOLO系列第一次使用anchor-free;
(5)新的损失函数。
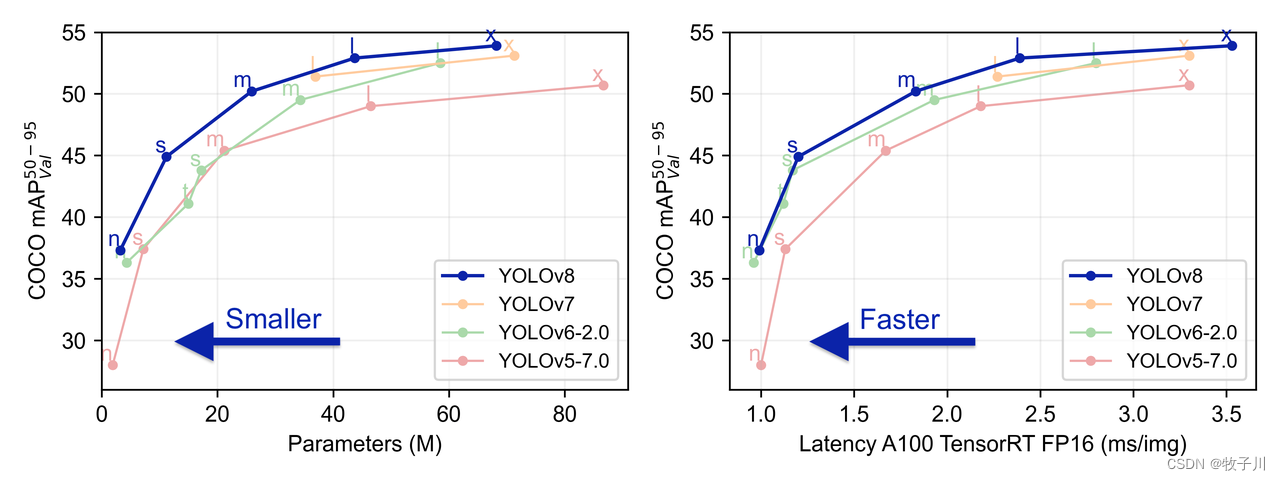
YOLO各版本性能对比
YOLOv8模型网络结构
YOLOv8模型的整体结构如下图所示:
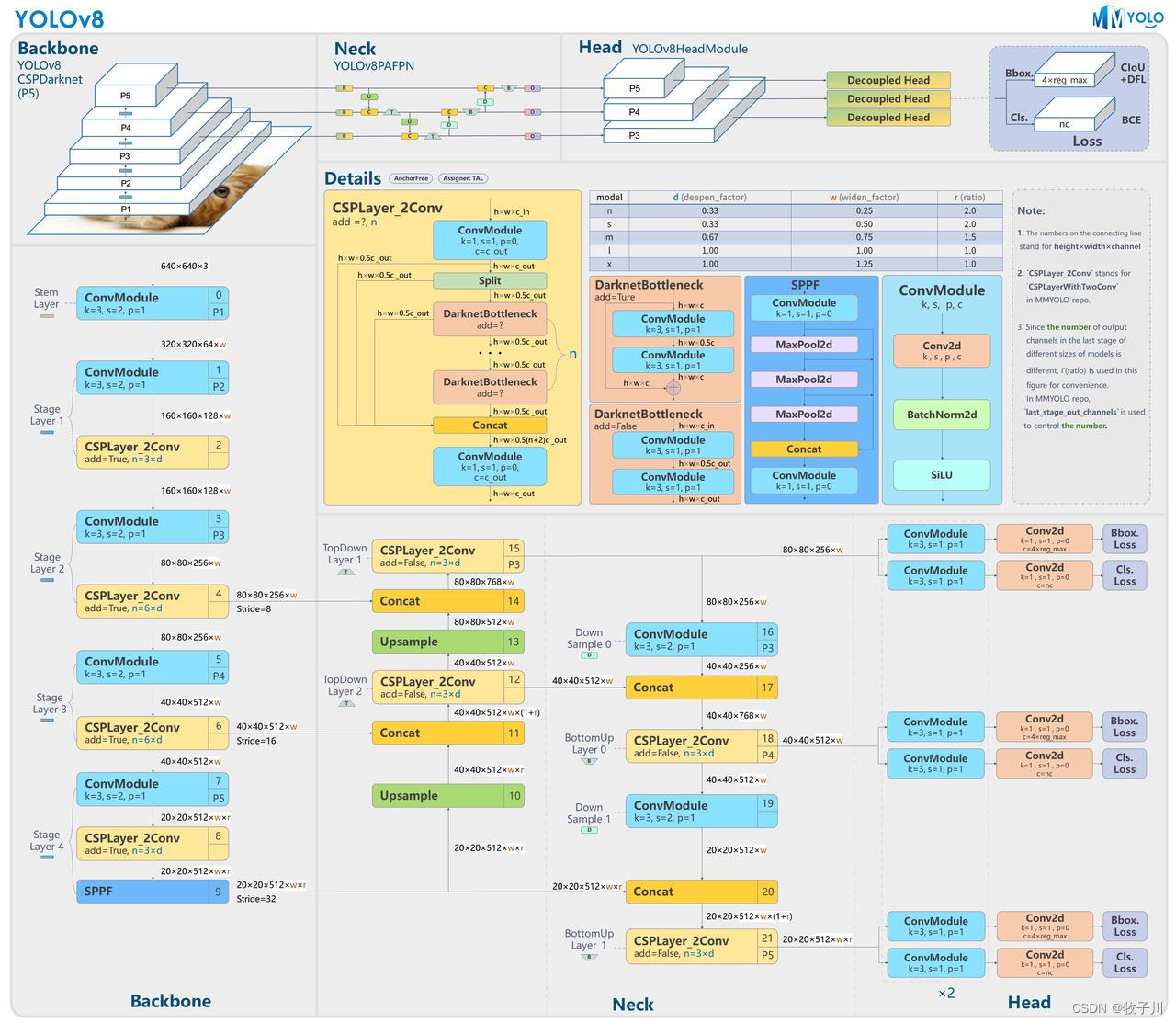
YOLOv8与YOLOv5模型最明显的差异是使用C2F模块替换了原来的C3模块;另外Head 部分变化最大,从原先的耦合头变成了解耦头,并且从 YOLOv5 的 Anchor-Based 变成了 Anchor-Free。
YOLOv8的网络架构包含了多个关键组件,这些组件共同工作以实现快速而准确的目标检测。首先是其创新的特征提取网络(Backbone),YOLOv8的Backbone采用了最新的网络设计理念,通过深层次的特征融合和精细的特征提取策略来增强对目标的识别能力。这一策略的成功关键在于其特征提取器能够充分捕获目标的细微特征,同时保持计算效率。
YOLOv8在训练策略上也进行了优化。与YOLOv7相比,YOLOv8采用了SPFF(Spatial Pyramid Fusion Fast)策略,该策略通过高效的多尺度特征融合提高了模型对不同大小目标的检测能力。此外,YOLOv8在训练过程中引入了一种名为Task Aligned Assigner的新技术,这种技术能够更精准地将预测框与真实目标对齐,从而提高检测的准确率。
在损失函数的设计上,YOLOv8进行了创新,采用了JFL(Joint Family Losses),这是一种集成了多个损失函数的复合损失函数,能够同时优化目标检测的多个方面。这些损失函数包括用于提升模型对目标位置和大小预测准确性的CIOU Loss,以及优化分类准确性的分类损失函数。JFL的设计允许YOLOv8更全面地考虑检测任务中的不同需求,通过协调各种损失来提升总体的性能。
YOLOv8的原理不仅在于其创新的技术点,更在于这些技术如何被综合应用于解决实际的目标检测问题。通过其精心设计的网络架构、高效的训练策略以及综合的损失函数设计,YOLOv8实现了在保持实时性的同时,提高了在复杂场景下的检测准确率。这些改进使得YOLOv8成为了一个强大的工具,适用于从自动驾驶到智能视频监控等多种应用场景。
四、模型的训练、评估与推理
数据集准备
本文使用的UAVVaste dataset 数据集,该包含772张图像和3718条注释。创建数据集的主要动机是缺乏特定领域的数据。因此,建议将此图像集用于目标检测评估基准测试,也可用于开发与无人机、遥感甚至环境清洁相关的解决方案。
图片数据集的存放格式如下:
注意:只需要修改mydata.yaml 里面的路径。
模型训练
数据准备完成后,通过调用train.py文件进行模型训练,epochs参数用于调整训练的轮数,代码如下:
from ultralytics import YOLO
if __name__ == "__main__":
# Load a model
model = YOLO('./weights/yolov8n-seg.pt') # load a pretrained model (recommended for training)
# Train the model
model.train(data='./COCOData/mydata.yaml', epochs=100, imgsz=640)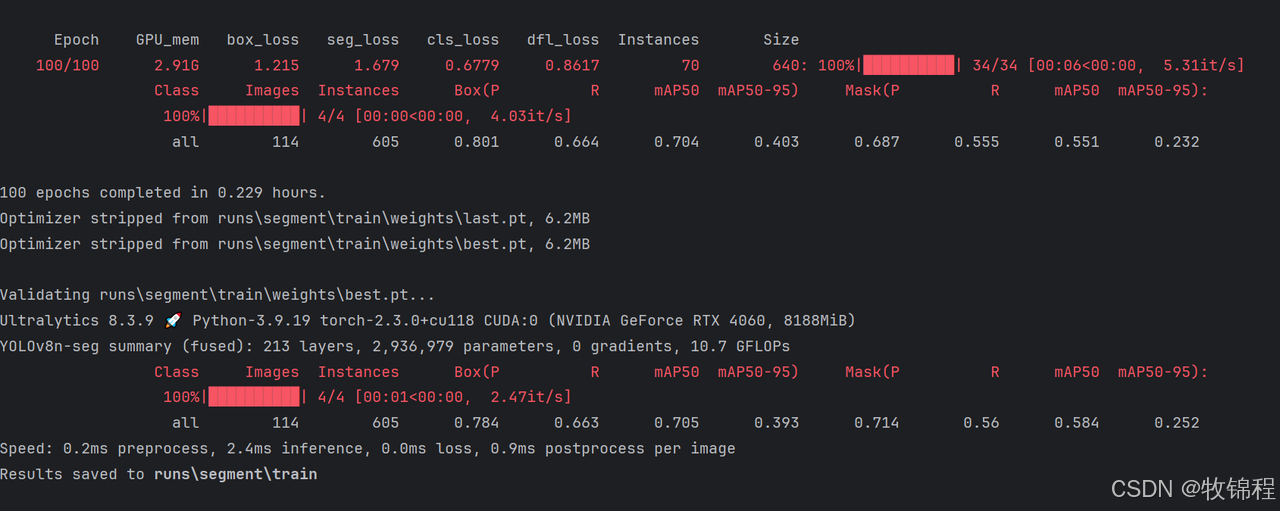
训练结果分析
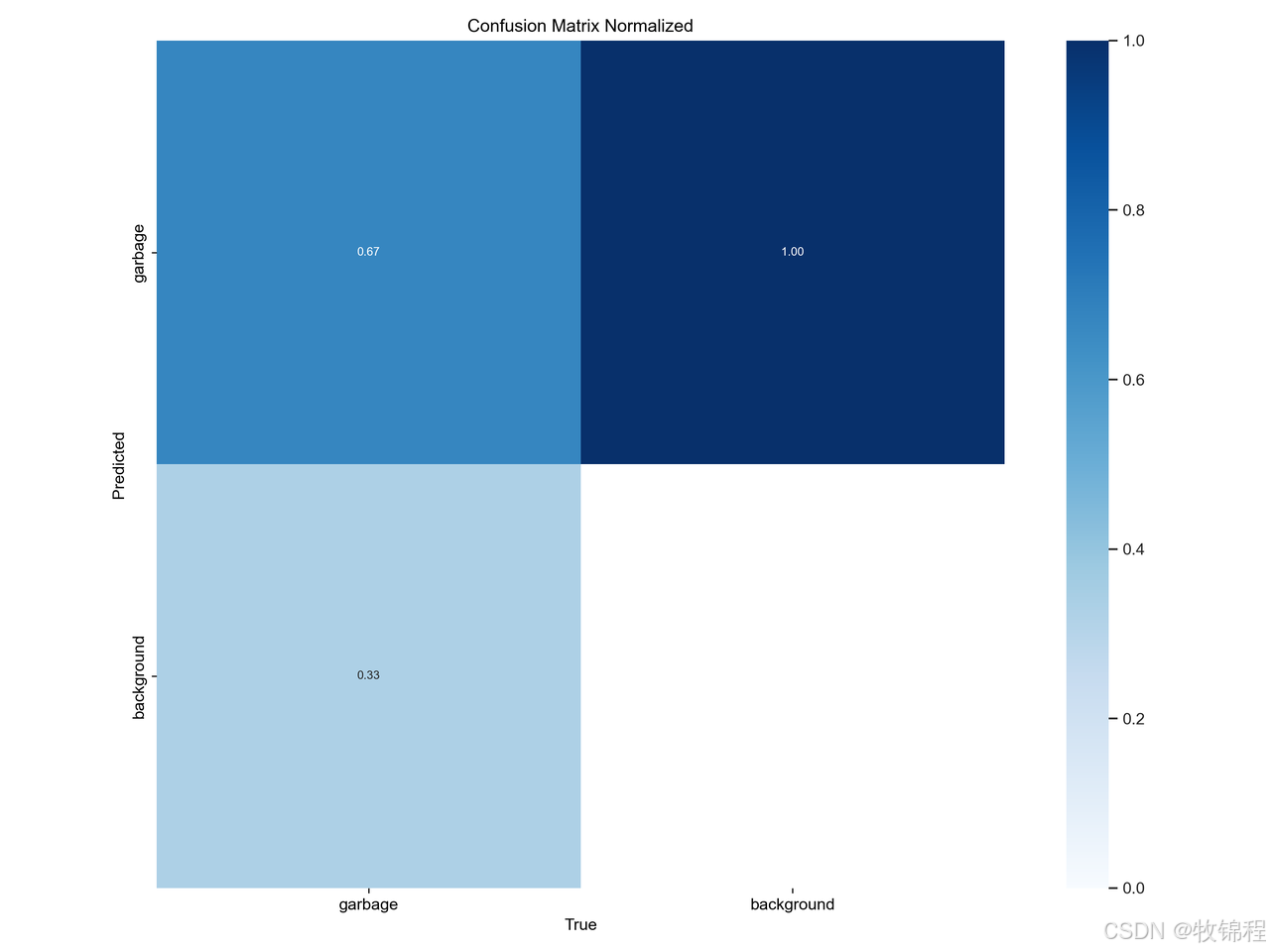
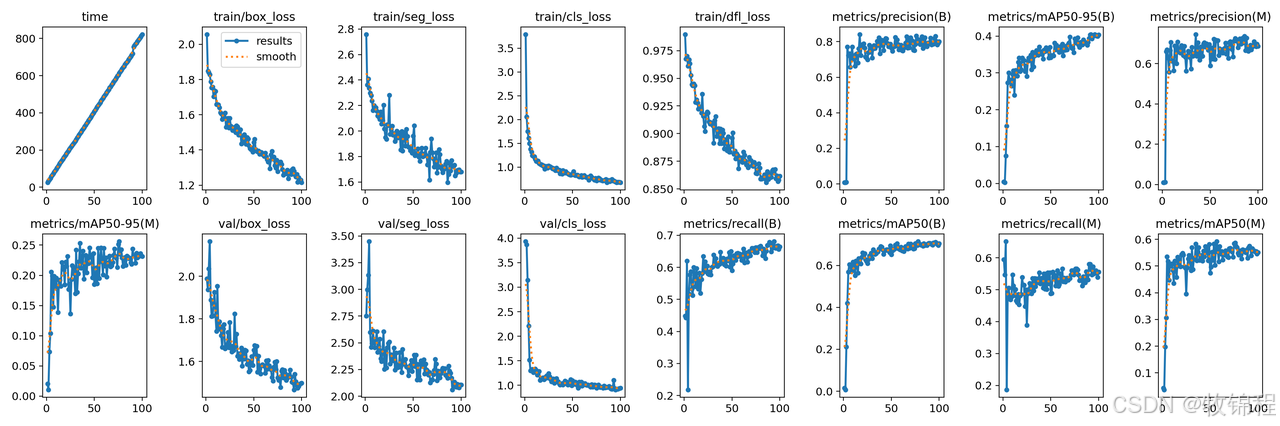
YOLOv8在训练结束后,可以在runs/目录下找到训练过程及结果文件,如下所示:

confusion_matrix_normalized.png
results.png
训练 batch

验证 batch

模型推理
模型训练完成后,可以得到一个最佳的训练结果模型best.pt文件,在runs/trian/weights目录下。我们通过使用该文件进行后续的推理检测。
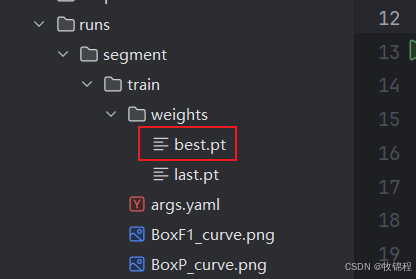
图片检测代码如下:
from ultralytics import YOLO
if __name__ == "__main__":
# Load a model
model = YOLO('./runs/detect/train/weights/best.pt')
# Run batched inference on a list of images
model("./img", save=True, device=0)执行上述代码后,会将执行的结果直接标注在图片上,结果如下:
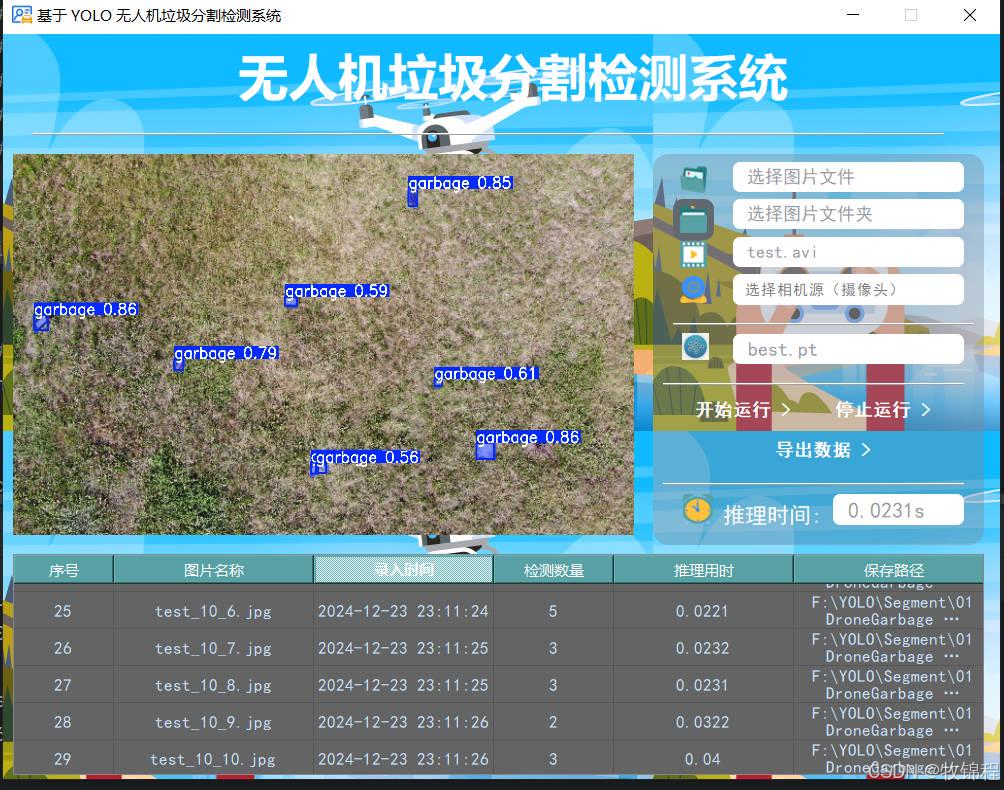
关于该系统涉及到的完整源码、UI界面代码、数据集、训练代码、测试图片视频等相关文件,均已打包上传,感兴趣的小伙伴可以通过下载链接自行获取。
五、获取方式
本文涉及到的完整全部程序文件:包括 python源码、数据集、训练好的结果文件、训练代码、UI源码、测试图片视频等(见下图),获取方式见文末:
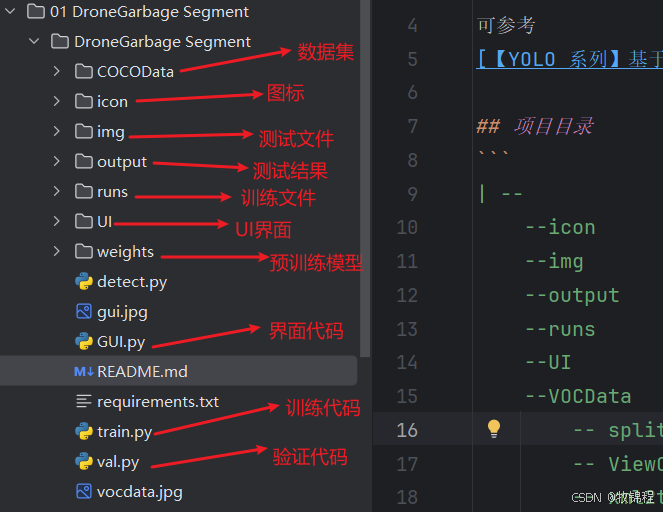
注意:该代码基于Python3.8开发,运行界面的主程序为GUI.py,其他测试脚本说明见上图。为确保程序顺利运行,请按照requirements.txt配置软件运行所需环境。
硬性的标准其实限制不了无限可能的我们,所以啊!少年们加油吧!


















 233
233

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











