









 本文详细介绍了Linux驱动开发的基础步骤,包括驱动框架的三个阶段、如何操作硬件(如使用ioremap映射寄存器)、与应用程序的数据传输,以及字符设备的注册与注销、模块加载和卸载。还讨论了设备号的分配策略。
本文详细介绍了Linux驱动开发的基础步骤,包括驱动框架的三个阶段、如何操作硬件(如使用ioremap映射寄存器)、与应用程序的数据传输,以及字符设备的注册与注销、模块加载和卸载。还讨论了设备号的分配策略。
初级框架
驱动框架一阶段
我们怎样去点亮一个 LED 呢?分为三步:
- 看原理图确定引脚,确定引脚输出什么电平才能点亮/熄灭 LED
- 看主芯片手册,确定寄存器操作方法:哪些寄存器?哪些位?地址是?
- 编写驱动:先写框架,再写硬件操作的代码
注意
:在芯片手册中确定的寄存器地址被称为
物理地址
,在
Linux
内核中无法直接使用。
需要使用内核提供的
ioremap
把物理地址映射为
虚拟地址
,使用虚拟地址。
ioremap 函数的使用:

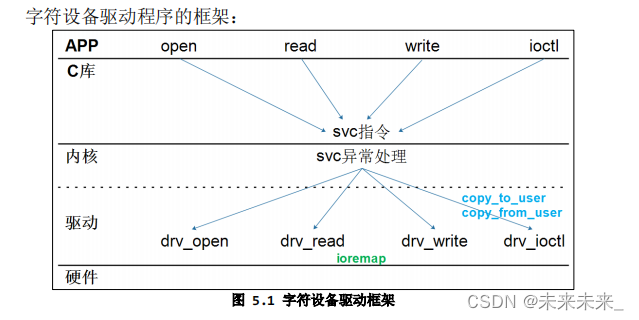
编写驱动程序的套路:
- 确定主设备号,也可以让内核分配;
- 定义自己的 file_operations 结构体;
- 实现对应的 drv_open/drv_read/drv_write 等函数,填入 file_operations 结构体;
- 把 file_operations 结构体告诉内核:register_chrdev;
- 谁来注册驱动程序啊?得有一个入口函数:安装驱动程序时,就会去调用这个入口函数;
- 有入口函数就应该有出口函数:卸载驱动程序时,出口函数调用 unregister_chrdev
- 其他完善:提供设备信息,自动创建设备节点:class_create, device_create
⚫
驱动怎么操作硬件?
◼
通过
ioremap 映射寄存器的物理地址得到虚拟地址,读写虚拟地址。驱动层访问硬件外设寄存器依靠的是 ioremap 函数去映射到寄存器地址,然后开始控制寄存器。
⚫
驱动怎么和 APP 传输数据?
◼
通过
copy_to_user
、
copy_from_user
这
2
个函数。
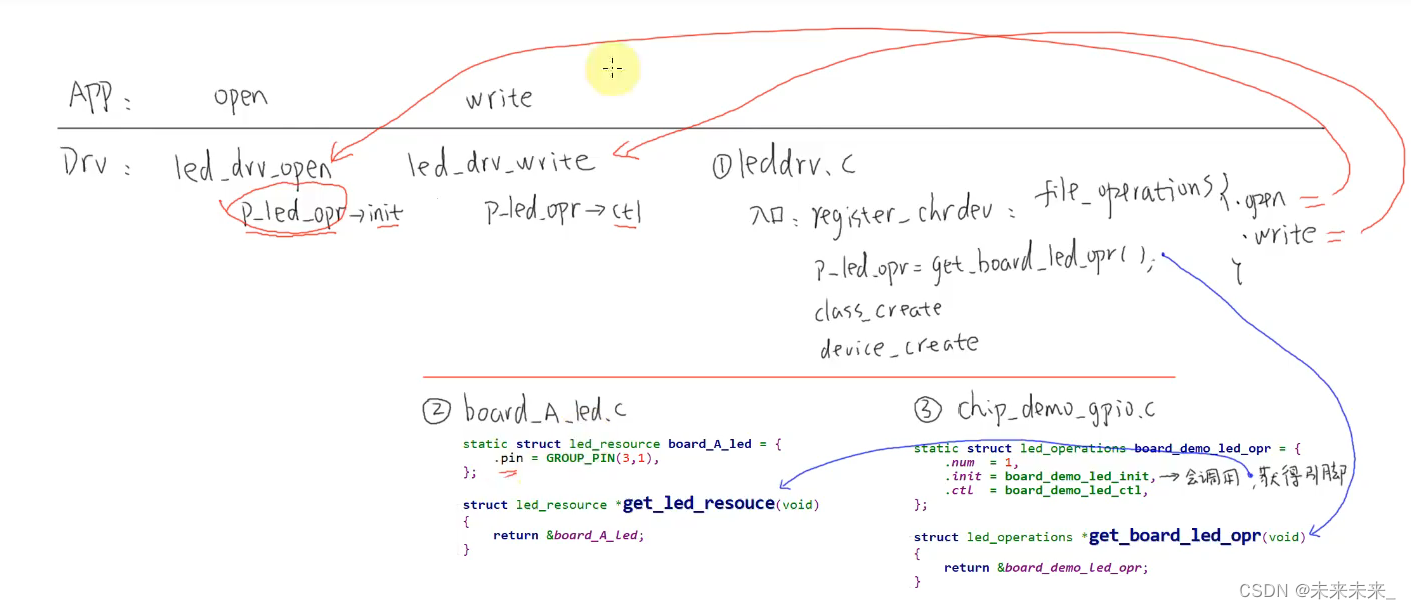
驱动框架二阶段:分层思想
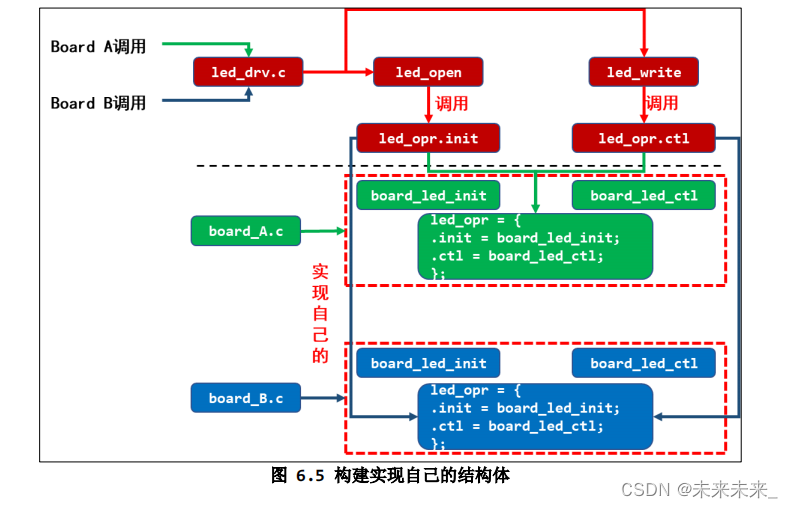
- 上层实现硬件无关的操作,比如注册字符设备驱动:leddrv.c
- 下层实现硬件相关的操作,比如 board_A.c 实现单板 A 的 LED 操作
驱动框架三阶段:分离
引脚操作那么有规律,并且这是跟主芯片相关的,那可以针对该芯片写出比较通用的硬件操作代码。
比如
board_A.c
使用芯片
chipY
,那就可以写出:
chipY_gpio.c
,它实现 芯片 Y
的
GPIO
操作,适用于芯片
Y
的所有
GPIO
引脚。
使用时,我们只需要在
board_A_led.c
中指定使用哪一个引脚即可。程序结构如下:
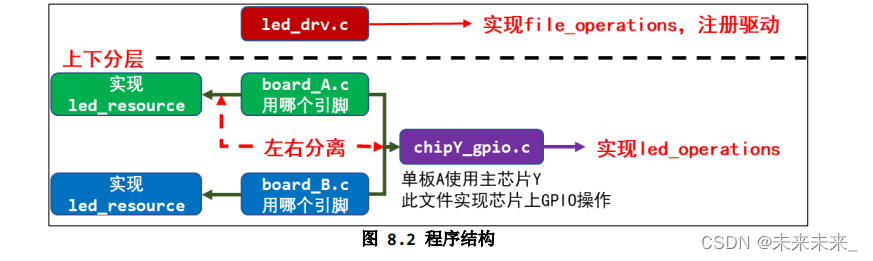
以面向对象的思想,在
board_A_led.c
中实现
led_resouce
结构体,它定 义“资源”──要用哪一个引脚。
在
chipY_gpio.c
中仍是实现
led_operations
结构体,它要写得更完善,支持所有 GPIO
。
总结:
程序仍分为上下结构:
上层
leddrv.c
向内核注册
file_operations
结构体;
下层 chip_demo_gpio.c
提供
led_operations
结构体来操作硬件。
下层的代码分为 2 个:
- chip_demo_gpio.c 实现通用的 GPIO 操作,
- board_A_led.c 指定使用哪个 GPIO,即“资源”,也就是硬件的引脚信息,它实现一个 led_resource 结构体,并提供访问函数。
进阶框架
一、驱动模块的加载和卸载
Linux 驱动有两种运行方式,
第一种就是将驱动编译进 Linux 内核中,这样当 Linux 内核启动的时候就会自动运行驱动程序。
第二种就是将驱动编译成模块(Linux 下模块扩展名为.ko),在Linux 内核启动以后使用“insmod”命令加载驱动模块。在调试驱动的时候一般都选择将其编译为模块,这样我们修改驱动以后只需要编译一下驱动代码即可,不需要编译整个 Linux 代码。而且在调试的时候只需要加载或者卸载驱动模块即可,不需要重启整个系统。
总之,将驱动编译为模块最大的好处就是方便开发,当驱动开发完成,确定没有问题以后就可以将驱动编译进Linux 内核中,当然也可以不编译进 Linux 内核中,具体看自己的需求。
module_init(xxx_init); //注册模块加载函数
module_exit(xxx_exit); //注册模块卸载函数二、字符设备注册与注销
对于字符设备驱动而言,当驱动模块加载成功以后需要注册字符设备,同样,卸载驱动模
块的时候也需要注销掉字符设备。字符设备的注册和注销函数原型如下所示
:
static inline int register_chrdev(unsigned int major, const char *name,
const struct file_operations *fops)
static inline void unregister_chrdev(unsigned int major, const char *name)
register_chrdev
函数用于注册字符设备,此函数一共有三个参数,这三个参数的含义如下:
major
:
主设备号,
Linux
下每个设备都有一个设备号,设备号分为主设备号和次设备号两部分,主设备号可以系统分配也可以自己指定。
name
:设备名字,指向一串字符串。
fops
:
结构体
file_operations
类型指针,指向设备的操作函数集合变量。
unregister_chrdev
函数用户注销字符设备,此函数有两个参数,这两个参数含义如下:
major
:
要注销的设备对应的主设备号。
name
:
要注销的设备对应的设备名。
一般字符设备的注册在驱动模块的入口函数 xxx_init 中进行,字符设备的注销在驱动模块的出口函数 xxx_exit 中进行。
三、实现设备具体操作函数
file_operations
结构体就是设备的具体操作函数
四、添加LICENSE和作者信息
最后我们需要在驱动中加入
LICENSE
信息和作者信息,其中
LICENSE
是必须添加的,否则的话编译的时候会报错,作者信息可以添加也可以不添加。LICENSE
和作者信息的添加使用 如下两个函数:
MODULE_LICENSE() //添加模块 LICENSE 信息
MODULE_AUTHOR() //添加模块作者信息
至此,字符设备驱动开发的完整步骤就讲解完了,而且也编写好了一个完整的字符设备驱
动模板,以后字符设备驱动开发都可以在此模板上进行。
补充:
1、Linux设备号
为了方便管理,
Linux
中每个设备都有一个设备号,设备号由主设备号和次设备号两部分组成,主设备号表示某一个具体的驱动,次设备号表示使用这个驱动的各个设备。
Linux
提供了 一个名为 dev_t
的数据类型表示设备号,
dev_t
定义在文件
include/linux/types.h
里面,dev_t 其实就是 unsigned int 类型,是一个 32 位的数据类型。这 32 位的数据构成了主和次设备号两部分设备号,其中高 12 位为主设备号,低 20 位为次设备号。因此 Linux系统中主设备号范围为 0~4095,所以在选择主设备号的时候一定不要超过这个范围。
2.设备号的分配
1
、静态分配设备号
注 册字符设备的时候需要给设备指定一个设备号,这个设备号可以是驱动开发者静态的指定一个 设备号,比如选择 200
这个主设备号。有一些常用的设备号已经被
Linux
内核开发者给分配了,具体分配的内容可以查看文档 Documentation/devices.txt
。并不是说内核开发者已经分配掉的主设备号我们就不能用了,具体能不能用还得看我们的硬件平台运行过程中有没有使用这个主设备号,使用“cat /proc/devices
”命令即可查看当前系统中所有已经使用了的设备号。
2
、动态分配设备号
Linux
社区推荐使用动态分配设备号,在注册字符设备之前先申请一个设备号,系统会自动给你一个没有被使用的设备号,这样就避免了冲突。卸载驱动的时候释放掉这个设备号即可,设备号的申请函数如下:
int alloc_chrdev_region(dev_t *dev, unsigned baseminor, unsigned count, const char *name)
















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









