






本文的作者是 Ilya Sklyar, Anna Piunova, Yulan Liu。Amazon Alexa。
动机:
端到端的语音识别系统开始研究有重叠片段的多个说话人的语音了,但是,因为有低延迟的限制,所以不太适合语音助手之类的交互。本论文主要是集中于多个说话人识别上,在低延迟的可能下提高识别精度,而且是在线识别。采用了一种流式的RNN-T的两种方法:确定性输出目标分配(DAT)和PIT,研究的结果表明模型实现了很好的性能。
单通道的语音上多个说话人部分或者全部重叠的语音识别取得了很大的进步,这个领域的研究工作主要分成了两种算法,一种算法是特定说话人分离前后端的模块化系统,比如深度聚类等等。另一种是训练多个说话人,这种是直接得到真实的输出,不需要中间信号的重建。这些方法都是依赖PIT,而PIT的计算复杂度很高,所以SOT(serialized output training)淡化了PIT的缺点。
很多的研究都是在低延迟的端到端的模型上实现多个说话人的识别,所以就促使本文的作者使用RNN-T模型以时间同步的方式(这里理解为低延迟)处理重叠的语音片段,并且同步多个说话人的文本序列。之后还采用了用语音序列标签、多风格训练的方式提高泛化性。
最原始的RNN-T模型是由三部分组成:一个编码器,一个预测网络,一个联合网络。编码器是把声学特征向量处理为高维特征向量,预测网络是在给定前面labels的条件下预测下一个label是什么,在训练的时候,真实的label作为上下文信息输入到预测网络中,测试阶段,用到的是前面的非空白性输出。联合网络是一个前馈网络,处理的是来自编码器和预测网络的输出作为它的输入,而它的输出是全部输出labels的概率分布。损失函数是一个负的对数似然函数。
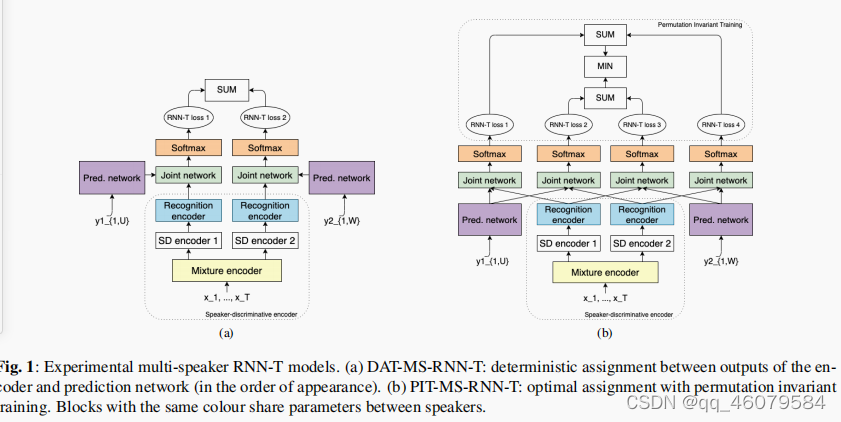
本文用到的是扩展的RNN-T,(MS-RNN-T)---多说话人网络。用编码器实现了语音分离。预测网络和联合网络都和原始的RNN-T一样。编码器主要包括三部分:一个混合的编码器,多个说话人独立的编码器(SD),一个识别编码器。整个的编码器叫做说话人鉴别编码器(speaker-discriminative encoder)。编码器的工作机制是:首先输入到混合编码器,混合编码器得到混合语音的声学特征表示,之后混合的声学特征表示输入到SD编码器,SD编码器针对每一个说话人参数都是不同的,所以会让模型产生分离的中间结果表示,这种设计假使已经提前知道要分离的说话人的数量了(有多少个SD就有多少个说话人)这个SD的输出可以让识别编码器并行处理,识别编码器的参数是共享的,为了计算分离编码器特征和相应的目标标签序列之间的对齐(assignment,对齐可能翻译的准确),需要找到说话人鉴别编码器的输出和预测网络输出之间的对齐。说话人对齐在多说话人之间是一种挑战,因为现在还不清楚用那些假设---参考说话者对其进行训练。所以就是前文提到的一种方法是DAT,一种是PIT。DAT考虑到两个说话人,模型有两个输出,第一个输出针对第一个说话者的标签序列开始优化,第二个输出针对后续的说话人的标签序列进行优化。训练的时候,为了让输出和目标之间对齐,在SD编码器里面加入一个对应的固定说话人的序列label进行标志。而PIT是会有多种组合方式,选择其中一种最合适的。
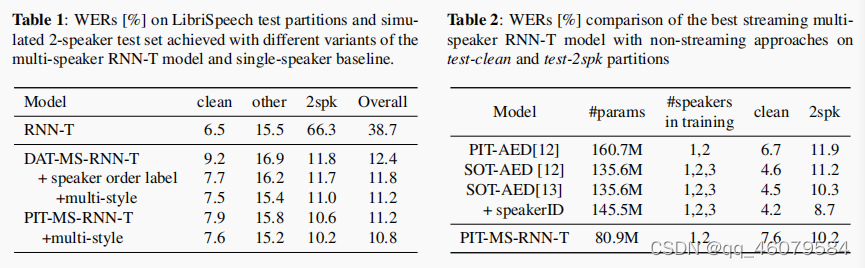
第一幅图是DAT,第二幅图是PIT(用edit distances的加和最小来选择最可能的排列组合)。
数据的制作:两个说话人需要有重叠的片段,第一个说话人和第二个说话人必须至少有0.5秒的时间间隔,第二名说话者的延迟是随机取样的。

















 744
744

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









