







 本文介绍了在Flink实时数仓中进行维表关联时,如何通过引入旁路缓存模式优化查询性能。优化策略包括使用Redis作为缓存,并讨论了缓存设置的关键点,如过期时间、数据变化管理和缓存选型。代码实现部分提到了流程图,但具体细节未展开。
本文介绍了在Flink实时数仓中进行维表关联时,如何通过引入旁路缓存模式优化查询性能。优化策略包括使用Redis作为缓存,并讨论了缓存设置的关键点,如过期时间、数据变化管理和缓存选型。代码实现部分提到了流程图,但具体细节未展开。
维表关联代码实现
维度关联实际上就是在流中查询存储在 HBase 中的数据表。但是即使通过主键的方式查询,HBase 速度的查询也是不及流之间的 join。外部数据源的查询常常是流式计算的性能瓶颈,所以咱们再这个基础上还有进行一定的优化。
优化1:加入旁路缓存模式
旁路缓存模式是一种非常常见的按需分配缓存的模式。如下图,任何请求优先访问缓存,缓存命中,直接获得数据返回请求。如果未命中则查询数据库,同时把结果写入缓存以备后续请求使用。
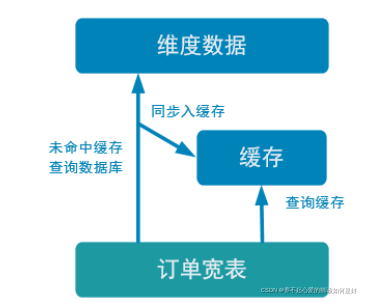
- 缓存策略注意点
- 缓存要设过期时间,不然冷数据会常驻缓存浪费资源。
- 要考虑维度数据是否会发生变化,如果发生变化要主动清除缓存。
- 堆缓存,从性能角度看更好,毕竟访问数据路径更短,减少过程消耗。但是管理性差, 其他进程无法维护缓存中的数据。
- 独立缓存服务(redis,memcache)性能也不错,不过会有创建连接、网络 IO
等消耗。但是考虑到数据如果会发生变化,那还是独立缓存服务管理性更强,而且如果数据量特别大,独立缓存更容易扩展。
因为咱们的维度数据都是可变数据,所以这里还是采用 Redis 管理缓存。
代码实现:
//数据流:web/app -> nginx -> SpringBoot -> Mysql -> FlinkApp -> Kafka(ods) -> FlinkApp -> Kafka/Phoenix(dwd-dim) -> FlinkApp(redis) -> Kafka(dwm)
//程 序: MockDb -> Mysql -> FlinkCDC -> Kafka(ZK) -> BaseDbApp -> Kafka/Phoenix(zk/hdfs/hbase) -> OrderWideApp(Redis) -> Kafka
public class OrderWideApp {
public static void main(String[] args) throws Exception {
//TODO 1.获取执行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
//1.1 设置CK&状态后端
//env.setStateBackend(new FsStateBackend("hdfs://hadoop102:8020/gmall-flink-210325/ck"));
//env.enableCheckpointing(5000L);
//env.getCheckpointConfig().setCheckpointingMode(CheckpointingMode.EXACTLY_ONCE);
//env.getCheckpointConfig().setCheckpointTimeout(10000L);
//env.getCheckpointConfig().setMaxConcurrentCheckpoints(2);
//env.getCheckpointConfig().setMinPauseBetweenCheckpoints(3000);
//env.setRestartStrategy(RestartStrategies.fixedDelayRestart());
//TODO 2.读取Kafka 主题的数据 并转换为JavaBean对象&提取时间戳生成WaterMark
String orderInfoSourceTopic = "dwd_order_info";
String orderDetailSourceTopic = "dwd_order_detail";
String orderWideSinkTopic = "dwm_order_wide";
String groupId = "order_wide_group_0325 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 860
860

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









