







1. 前言
自从chatgpt出现,大模型的发展就进入了快车道,各种各样的大模型卷上天,作为一个在大模型时代的科研人,即使你不向前,也会被时代裹挟着向前,所以还是自己走快一点比较好,免得被后浪拍死在沙滩上。对于我而言,写文章更多的是对知识的总结和回顾,当然如果我的文章能够对你的学习有所帮助我也是挺开心的。
这篇文章主要参考B站上的这位大神的视频以及Huggingface上的总结
B站视频LLM分词
Huggingface Tokenizers
另外大家也可以通过这个分词网站来玩一下分词:https://tiktokenizer.vercel.app
这里放上一张思维导图,方便大家理解整篇文章的脉络。

2. Token,Tokenization和Tokenizer的概念
首先,什么是Token?什么是Tokenization? 什么又是Tokenizer
Token:是文本数据的基本单元也即词元,通常表示一个词、子词或字符.
Tokenization:Tokenization中文翻译为分词,是将原始文本字符串分割成一系列Token的过程。这个过程可以有不同的粒度,比如单词级别分词(Word-based Tokenization)、字符级别分词(Character-based Tokenization)和子词级别分词(Subword-based Tokenization)。
Tokenizer: 是将文本切分成多个tokens的工具或算法,例如:Word-based Tokenizer,Character-based Tokenizer,Subword-based Tokenizer.
另外在NLP中我们经常会遇到一个词OOV(Out Of Vocabulary),意思是有些单词在词典中查询不到,例如一些根据词根现造的词,或者拼写错误的词等
接下来,我们首先介绍两种比较容易理解的分词Word-based Tokenizer 和Character-based Tokenizer
3. Word-based Tokenizer
Word-based Tokenizer 是将将文本划分为一个个词(包括标点)
我们以这句话为例:"Don't you love 🤗 Transformers? We sure do."
一种最简单的方法是通过空格进行划分:
["Don't", "you", "love", "🤗", "Transformers?", "We", "sure", "do."]
在这种划分下,标点和单词是粘在一起的: ["Transformers?","do."],,如果把标点也作为一个词的话,可以进一步划分:
["Don", "'", "t", "you", "love", "🤗", "Transformers", "?", "We", "sure", "do", "."]
但是这里的Don't 应该被划分为Do,n't,引入规则之后事情就变得复杂起来了。
英文的划分有两个常用的基于规则的工具spaCy 和 Moses,划分如下:
["Do", "n't", "you", "love", "🤗", "Transformers", "?", "We", "sure", "do", "."]
使用Word-base Tokenizer,
优点是:符合人的自然语言和直觉。
缺点是: ①相同意思的词被划分为不同的token,比如:dog和dogs ② 最终的词表会非常大

因此我们可以设置词表上限比如上限为10000,未知的词用Unkown表示

但是这样会损失大量的信息,模型性能大打折扣!
4. Character-based Tokenizer
Character-based Tokenizer 将文本划分为一个个字符(包括标点)。
我们以这个例子为例: Today is Sunday.
按照Character 划分,我们可以得到
["T","o","d","a","y","i","s","S","u","n","d","a","y"]
使用Character-based Tokenizer 划分的优点是
① 大大减少了词汇量,在256个ASCII码表示的范围内
② 可以表示任意字符,不会出现unkown的情况
缺点是
①字母包含的信息量低,一个字母"T” 无法知道它具体指代的是什么,但如果是"Today"语义就比较明确
②相对于Word-based Tokenizer ,会产生很长的token序列
③如果是中文,依然会有很大的词汇量
5. Subword-based Tokenizer
在了解了Word-based Tokenizer和Character-based Tokenizer之后,我知道它们各有优缺点,接下来要介绍的Subword-based Tokenizer 则是这两种方法的折中。

Subword-based Tokenizer有BPE/BBPE,Unigram,WordPiece和SentencePiece,这些分词算法在下列模型中有应用

5.1 BPE/BBPE
5.1.1 BPE
BPE分词最早在 Neural Machine Translation of Rare Words with Subword Units (Sennrich et al.2015)中提出.BPE分为两部分“词频统计”和“词表合并”。词频统计依赖于一个预分词器(pre-tokenization)将训练数据分成单词。预分词器可以非常简单,按照空格进行分词。例如GPT2,RoBERTa等就是这样实现的,更高级的预分词器引入了基于规则的分词,例如XLM,FlauBERT 使用Moses, GPT 使用spaCy 和 ftfy来统计语料中每个单词的词频。
在预分词之后,创建一个包含不同单词和对应词频的集合,接下来根据这个集合创建包含所有字符的词表,再根据合并规则两两合并形成一个新字符,将频率最高的新字符加入词表,直到达到预先设置的数量,停止合并。
仅仅讲概念可能会比较抽象,我们这里举个例子:
假设在预分词(一般采用Word-based Tokenization)之后,得到如下的包含词频的集合:
("hug", 10), ("pug", 5), ("pun", 12), ("bun", 4), ("hugs", 5)
因此,基本词汇表是这样的:["b", "g", "h", "n", "p", "s", "u"] ,将所有单词按照词汇表里的字符切割得到如下形式:
("h" "u" "g", 10), ("p" "u" "g", 5), ("p" "u" "n", 12), ("b" "u" "n", 4), ("h" "u" "g" "s", 5)
接下来统计相邻的两个字符组成的字符对的出现的频率:

ug出现了20次,出现次数最高,因此把ug加入词汇表,并将出现在一起的u,g用ug替换,然后在此统计词频un出现的频率最高,将un加入到词表,并将出现在一起的u,n用un替换。

接着进行第三次

假设基本词汇有478个,经过了40000次合并就有40478个,然后我利用这个词表进行分词,对于不在词表中的设置为特殊词<unk>

5.1.2 BBPE
重点介绍一下BBPE ,因为GPT2,GPT3,GPT4和LLaMA用的就是它,BBPE即 Byte-level BPE 。
如果仅仅是英文,那么BPE的基本词汇表大小就是ascii的词汇表大小,但如果是多种语言,比如加入了韩语,中文,日语甚至表情,那么BPE的基本词汇表就变成了全部Unicode字符,这个时候词汇表就将非常庞大,那么这个时候我们就会思考,有没有一种可能用统一的方式表示各种语言呢,那就是用字节Byte表示,也就是先将所有的字符转成UTF-8编码。
UTF-8编码是通过1-4个字节来表示一个字符。这里直接放上UTF-8介绍,每一个字节都是8位bit,8位bit的无符号整数范围为0-255,因此,BPE的基本词汇表又回到了256,是不是特别神奇。接下来就回归到BPE算法的原先操作了。
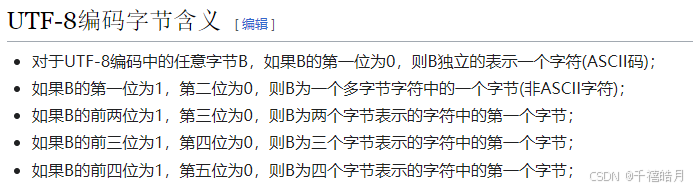
可能有人会问为什么不用UTF-16或者UTF-32?我们不妨举个例子。
text="我爱 🤗 Hugging"
print("Unicode:",[ord(x) for x in text])
print("UTF-8:",list(text.encode("utf-8")))
print("UTF-16:",list(text.encode("utf-16")))
print("UTF-32:",list(text.encode("utf-32")))
输出结果有点长,大家耐心点看完,或者自己run一下
Unicode: [25105, 29233, 32, 129303, 32, 72, 117, 103, 103, 105, 110, 103]
UTF-8: [230, 136, 145, 231, 136, 177, 32, 240, 159, 164, 151, 32, 72, 117, 103, 103, 105, 110, 103]
UTF-16: [255, 254, 17, 98, 49, 114, 32, 0, 62, 216, 23, 221, 32, 0, 72, 0, 117, 0, 103, 0, 103, 0, 105, 0, 110, 0, 103, 0]
UTF-32: [255, 254, 0, 0, 17, 98, 0, 0, 49, 114, 0, 0, 32, 0, 0, 0, 23, 249, 1, 0, 32, 0, 0, 0, 72, 0, 0, 0, 117, 0, 0, 0, 103, 0, 0, 0, 103, 0, 0, 0, 105, 0, 0, 0, 110, 0, 0, 0, 103, 0, 0, 0]
5.2 WordPiece
WordPiece和BPE很类似,这里大家就自己看PPT吧,实在写得有点累。
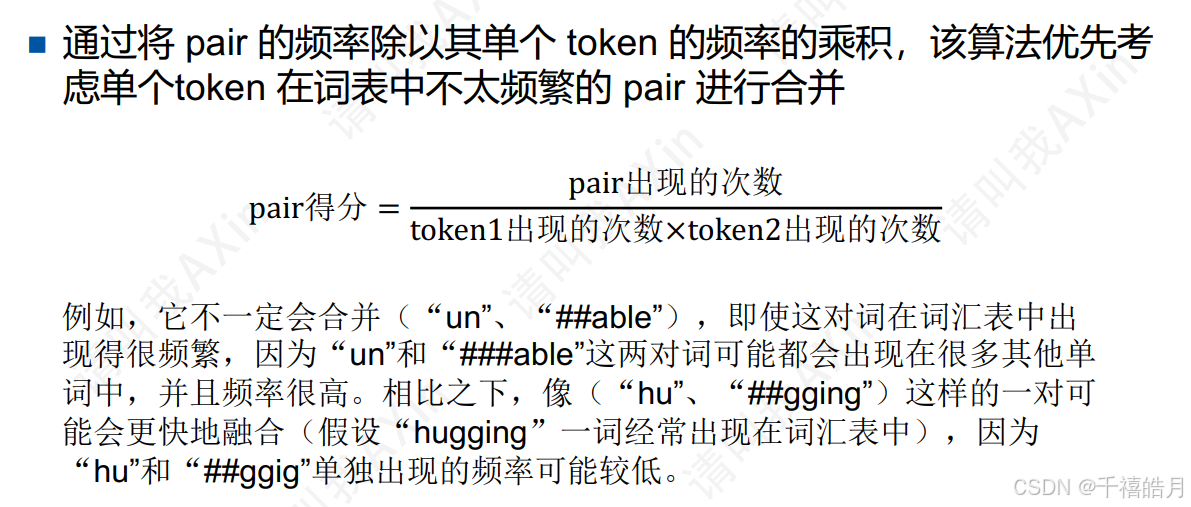

5.3 Unigram
这里面最复杂的就是这个Unigram了。与BPE和WordPiece不同,Unigram是初始化一个很大的词表,然后不断地进行删减。我们通过一个例子进行讲解。假设我们有如下统计完词频后的语料:
("hug",10),("pug",12),("lug",5),("bug",4) ,("dug",5)
我们按照所有的子词划分方式列出,构建基本词表:
["h","u","g","l","p","b","d","ug","pu","hu","lu","du","bu"]
对所有词进行词频统计,总计为180
[("h",10),("u",36),("g",36),("l",5),("p",12),("b",4),("d",5),("ug",36),("pu",12),("hu",10),("lu",5),("du",5),("bu",4)]
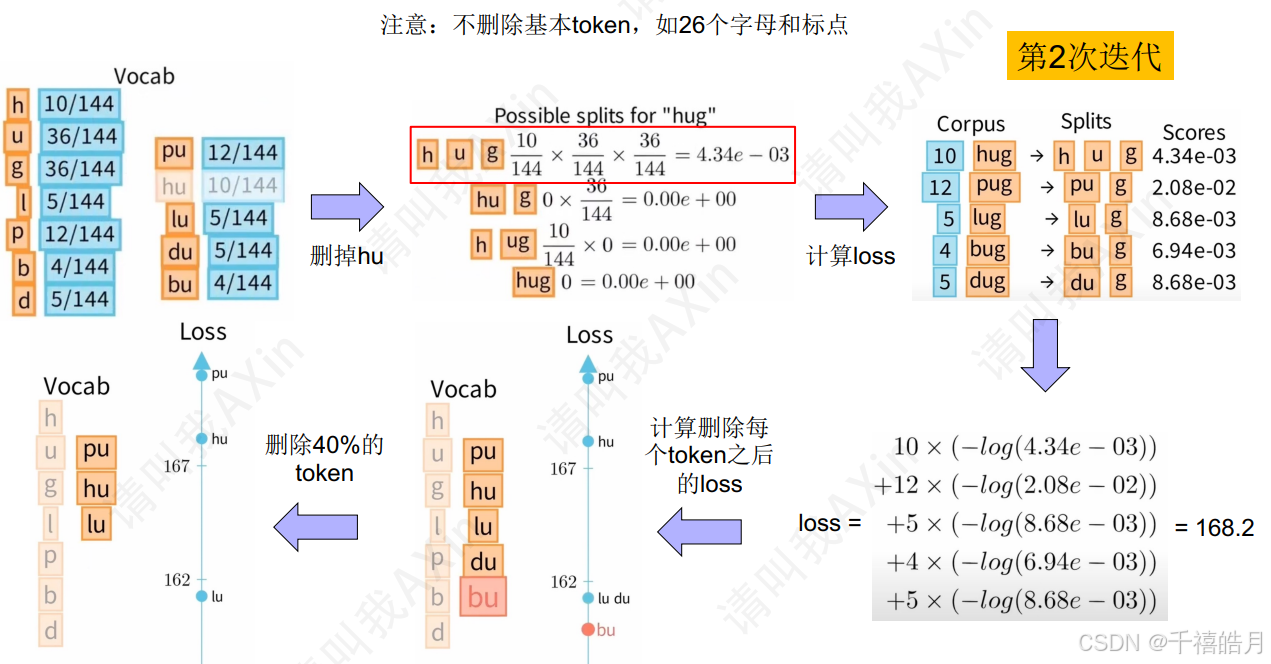
对于语料中的每个词,我们算出每种划分的概率,以hug为例,它有4种划分方式:

在这四种划分中("hu","g"),("h","ug")这两种概率最大且相等,我们可以任选一种,比如选("hu","g") 。对于其他词我们也依次类推,就得到了每个词划分的概率

此时,我们可以算出unigram loss

接下来就是对词表进行删减:

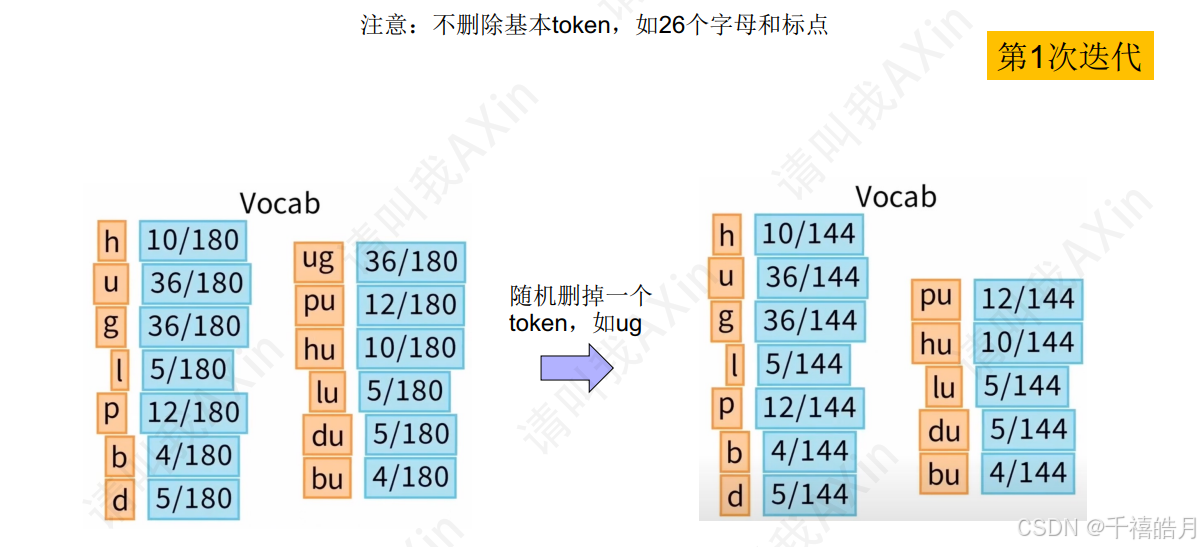
这里不加赘述了,这是最原始的方案,这个方案在实际的使用中非常低效,因此在实际的使用中,采用的是维特比
(Viterbi)算法
5.4 SentencePiece
BPE、WordPiece、Unigram 的缺点:
①假设输入文本使用空格来分隔单词,但并非所有语言都使用空格来分隔单词(如中文、韩文、日文、阿拉伯语)
②可以使用特定语言的pre-tokenizer 分词,但不太通用
为解决这个问题,SentencePiece将输入视为输入字节流,包括空格 然后搭配BBPE和Unigram来使用
小结
写到这里不得不感慨一下,写文章实属不易,在写文章的过程中会遇到一些自己不懂的知识点,然后去查资料,学会,嚼碎,然后再用自己理解的方式表述出来,不过在这个过程中也是一种对于知识的内化的过程。这篇文章前前后后花了一个星期的时间,也借鉴了许多大佬的文章和视频,在此表示感谢,如果你觉得对你有帮助的话,麻烦点个赞这是我持续创作的动力,谢谢。
参考文献
简介NLP中的Tokenization(基于Word,Subword 和 Character)
https://zhuanlan.zhihu.com/p/620603105
https://blog.youkuaiyun.com/zhaohongfei_358/article/details/123379481
LLM大语言模型之Tokenization分词方法



















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











