







一、本文介绍
🔥本文给大家介绍使用CVIM模块改进YOLOv13网络模型,能够通过高效的跨视图特征交互,显著提升目标检测的精度和鲁棒性。CVIM通过融合来自不同视角的互补信息,增强了YOLOv13对目标的识别和定位能力,尤其在复杂场景、遮挡和多视角条件下表现出色。
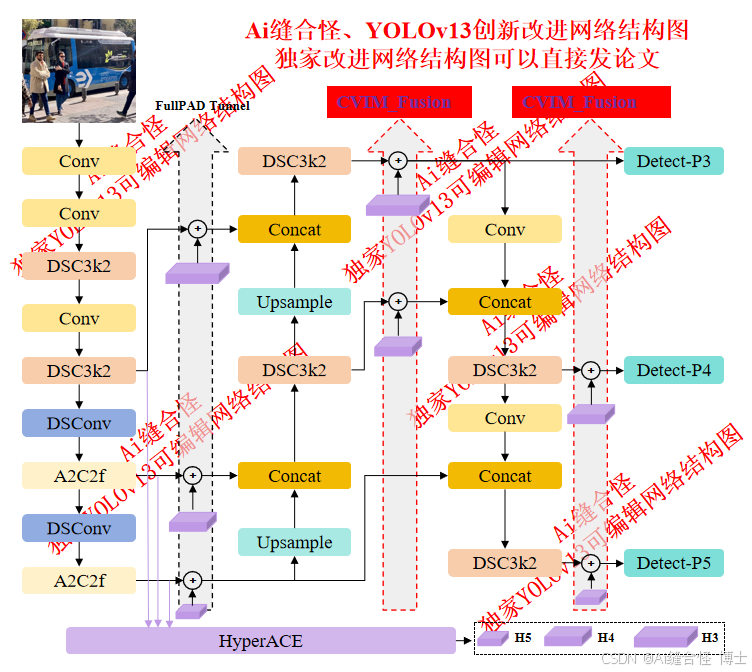
展示部分YOLOv13改进后的网络结构图、供小伙伴自己绘图参考:
🚀 创新改进结构图: yolov13n_CVIM.yaml
专栏改进目录:YOLOv13改进包含各种卷积、主干网络、各种注意力机制、检测头、损失函数、Neck改进、小目标检测、二次创新模块、HyperACE二次创新、独家创新等几百种创新点改进。
全新YOLOv13创新改进专栏链接:全新YOLOv13创新改进高效涨点+永久更新中(至少500+改进)+高效跑实验发论文
本文目录
1.首先在ultralytics/nn/newsAddmodules创建一个.py文件
2.在ultralytics/nn/newsAddmodules/__init__.py中引用
二、CVIM跨视图特征交互模块介绍

摘要:立体图像超分辨率技术通过利用左右视图图像的视差效应产生的互补信息,重建出更高品质的图像。当前众多方法的核心在于通过级联特征提取模块和跨视图特征交互模块来利用立体图像信息。然而,这种设计会显著增加网络参数量并产生结构冗余。为促进立体图像超分辨率技术在下游任务中的应用,我们提出了一种高效的轻量化立体图像超分辨率多级特征融合网络(MFFSSR)。具体而言,MFFSSR采用混合注意力特征提取模块(HAFEB)来提取多层级视图内特征。通过通道分离策略,HAFEB能高效与嵌入式跨视图交互模块协同工作。这种结构设计既能有效挖掘视图内部特征,又能提升跨视图信息共享效率,从而更精准地还原图像细节与纹理。大量实验验证了MFFSSR的有效性,我们以更少参数量实现了更优性能。

 订阅专栏 解锁全文
订阅专栏 解锁全文


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









