







 该专栏为热销专栏榜 第4名
该专栏为热销专栏榜 第4名一、本文介绍
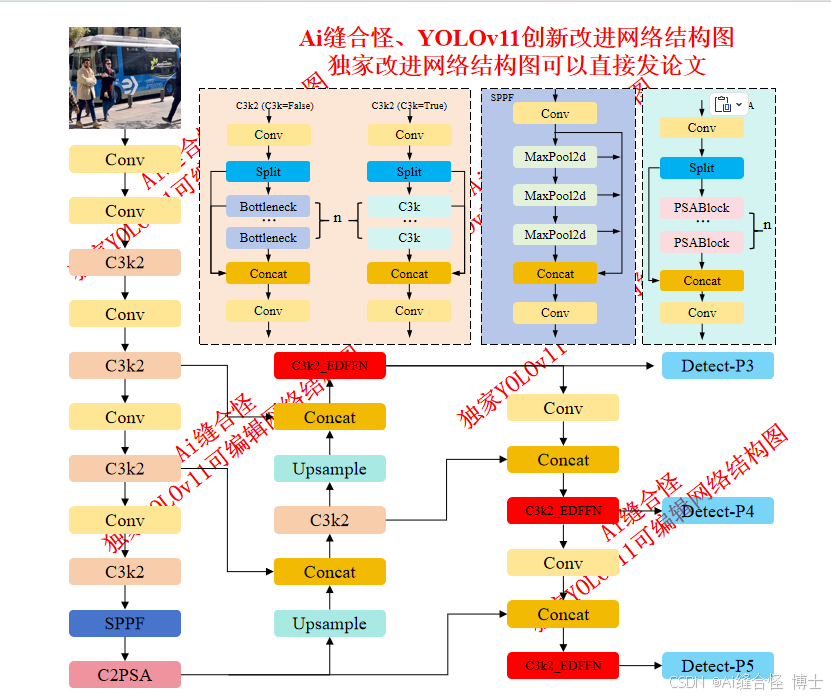
🔥本文给大家介绍将 EDFFN 模块 改进YOLOv11 网络模型,可显著提升模型的特征表达能力与检测精度。EDFFN 通过在频域执行判别性筛选(FFT→筛选矩阵W→IFFT),自适应强化高频纹理与边缘信息,同时抑制无关的低频背景,从而增强模型对小目标、复杂背景和模糊图像的分辨能力。与注意力机制相比,它计算量低、推理速度几乎不变,却能在空间与频率两域实现信息互补。可提升细节清晰度、降低误检、提高小目标检测,兼具高效性、鲁棒性与可移植性。
展示YOLOv11改进后的网络结构图、供小伙伴自己绘图参考:
🚀 创新改进结构图: yolov11n_C3k2_EDFFN.yaml
专栏改进目录:YOLOv11改进专栏包含卷积、主干网络、各种注意力机制、检测头、损失函数、Neck改进、小目标检测、二次创新模块、C2PSA/C3k2二次创新改进、全网独家创新等创新点改进
全新YOLOv11-发论文改进专栏链接:全新YOLOv11创新改进高效涨点+永久更新中(至少500+改进)+高效跑实验发论文
本文目录
1.首先在ultralytics/nn/newsAddmodules创建一个.py文件
2.在ultralytics/nn/newsAddmodules/__init__.py中引用
🚀 创新改进: yolov11n_C3k2_EDFFN.yaml
二、EDFFN高效鉴别频域模块介绍

摘要:卷积神经网络(CNN)和视觉Transformer(ViT)在图像恢复任务中都取得了优异的表现。相较于CNN,ViT通常能取得更好的恢复效果,因为它能够捕获长程依赖关系,并具有与输入相关的自适应特性。然而,Transformer模型的计算复杂度随着图像分辨率呈二次增长,这极大限制了其在高分辨率图像恢复任务中的应用价值。为此,本文提出了一种简单而高效的视觉状态空间模型(Efficient Visual State Space Model, EVSSM)用于图像去模糊。该方法利用状态空间模型(SSM)在视觉数据中的优势。与现有方法需要在多个固定方向上进行扫描以提取特征、从而显著增加计算开销不同,我们设计了一种高效的视觉扫描模块(efficient visual scan block),该模块在每个基于SSM的子模块之前引入几何变换(geometric transformation),从而在保持高效率的同时捕获有用的非局部信息。大量实验结果表明,所提出的EVSSM方法在基准数据集和真实模糊图像上的性能均优于现有的最新图像去模糊方法,在保持计算高效的同时实现

 订阅专栏 解锁全文
订阅专栏 解锁全文


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









