









1. 线性回归算法 Linear Regression
回归分析(Regression Analysis)是统计学的数据分析方法,目的在于了解两个或多个变量间是否相关、相关方向与强度,并建立数学模型以便观察特定变量来预测其它变量的变化情况。
线性回归算法(Linear Regression)的建模过程就是使用数据点来寻找最佳拟合线。
![]()
2. 支持向量机算法(Support Vector Machine,SVM)
支持向量机/网络算法(SVM)属于分类型算法。SVM模型将实例表示为空间中的点,将使用一条直线分隔数据点。需要注意的是,支持向量机需要对输入数据进行完全标记,仅直接适用于两类任务,应用将多类任务需要减少到几个二元问题。 尤其在二分类任务中效果显著。
支持向量机(SVM)通常需要对输入数据进行完全标记,这是因为它是一种监督学习算法,依赖标记信息来学习数据的特征和分类边界。
SVM 最初是被设计用于二类分类任务的,它通过寻找一个最优的超平面来将两类数据分开,并且使得两类数据之间的间隔最大化,在二分类任务中往往能取得显著的效果。
支持向量机(SVM)的 “一对一” 和 “一对多” 是将多分类问题转化为二分类问题的两种常见策略。


两种策略的比较
- 计算复杂度:OvO 需要训练的分类器数量较多,计算量较大,但在训练每个分类器时,使用的数据量相对较少;OvR 训练的分类器数量较少,计算量相对较小,但每个分类器训练时使用的数据量较大,因为要将除了一个类别之外的其他所有类别作为负类。
- 分类准确性:一般来说,OvO 的分类准确性相对较高,因为每个二分类器只需要区分两个类别,更容易找到准确的分类边界;而 OvR 可能会因为正负样本数量不均衡等问题,导致分类效果稍差。
- 内存需求:OvO 需要存储较多的分类器,因此对内存的需求较大;OvR 存储的分类器较少,内存需求相对较小。
原理:寻找最优超平面,最大化不同类别数据间的间隔。通过核函数(如高斯核)将数据映射到高维空间解决非线性问题。

3. 最近邻居/k-近邻算法 (K-Nearest Neighbors,KNN)
3.1 KNN算法解释:
KNN算法基于一个非常直观的思想 : 对于一个未知类别的数据点,可以通过查看它在特征空间中距离最近的K个邻居的类别或数值信息,来决定该数据点的类别或预测其值。
3.2算法的主要步骤如下:
1. 计算距离:
常用的距离度量方法有欧氏距离、曼哈顿距离等。对于一个待预测的数据点,计算它与训练集中所有数据点的距离。
2. 选择最近邻:
根据计算得到的距离,选取距离最小的K个数据点
优点:无需训练,简单直观,适合多分类问题

3.3 L1范数和L2范数:
曼哈顿距离(街区距离): 向量中各个元素绝对值之和,L1范数
欧氏距离(直线距离): 向量中各元素的平方和然后求平方根, L2范数
| 特性 | L1 范数 | L2 范数 |
|---|---|---|
| 解的稀疏性 | 会产生稀疏解(部分参数为零) | 解是密集的(参数趋近于零但不为零) |
| 正则化效果 | 更侧重于特征选择 | 更侧重于降低参数的量级 |
| 对异常值的敏感度 | 不敏感(具有鲁棒性) | 敏感(容易受到噪声的影响) |
| 优化难度 | 非光滑,求解难度较大 | 光滑,求解较为容易 |
| 典型应用场景 | Lasso 回归 | 岭回归 |
L1 范数的惩罚项会促使一些不重要的特征对应的参数变为零,从而达到特征选择的目的,减少模型的复杂度,提高模型的泛化能力。例如,在一个预测房价的模型中,可能有很多特征,如房间数量、面积、房龄等,使用 L1 范数正则化后,模型可能会发现一些对房价影响较小的特征,将其对应的参数置零,只保留对房价预测最重要的特征。
L2 范数的作用是减小参数的大小,降低模型的复杂度,但不会像 L1 范数那样直接将某些参数置零。例如,在一个图像识别模型中,使用 L2 范数正则化可以防止模型过拟合,使模型的参数更加稳定,不会出现某些参数过大的情况,但所有参数都会对模型的预测结果产生一定的影响,不会出现参数为零的情况。
如果希望进行特征选择,得到一个稀疏的模型,那么 L1 范数通常是一个较好的选择;如果只是希望防止过拟合,使模型的参数更加稳定,那么 L2 范数可能更合适。
| 对比项 | Lasso 回归 | 岭回归 |
|---|---|---|
| 正则化类型 | L1 范数(绝对值之和) | L2 范数(平方和) |
| 目标 | 特征选择(稀疏解) | 防止过拟合、缓解共线性 |
| 解的特性 | 部分参数为 0(稀疏性) | 参数较小但非零(平滑性) |
| 优化算法 | 近端梯度下降、LARS 等特殊算法 | 梯度下降、Normal Equation 等 |
| 参数解释性 | 可直接排除无关特征(参数为 0) | 参数均非零,需结合业务判断 |
-
Lasso 回归:
像 “严格的老师”,强制让不重要的特征系数变为 0,直接剔除冗余特征,适合需要精简模型的场景。 -
岭回归:
像 “温和的老师”,让所有特征系数都缩小,但保留所有特征,适合需要稳定模型且特征间存在相关性的场景。
3.4最常用的「K 折交叉验证」步骤(以 5 折为例)
- 分块:把数据随机分成 5 份(每份叫「折」Fold)。
(例:奶茶用户数据 1000 条 → 分 5 组,每组 200 条) - 循环训练:
- 第 1 轮:用第 2-5 组(800 条)训练模型,测第 1 组(200 条)→ 得准确率 85%
- 第 2 轮:用第 1,3-5 组训练,测第 2 组 → 得准确率 88%
- ……(重复 5 次,每轮换不同的组当测试集)
- 汇总结果:5 次准确率的平均分(如 86.6%),作为模型真实水平。
3.3.1 k 越小:听「最铁邻居」的,可能踩坑
- 例子:你选餐厅时,只问最近的 1 个邻居(k=1)。
→ 若邻居是素食者,ta推荐的素菜馆,可能不适合爱吃肉的你(过拟合,被局部噪声带偏)。 - 优点:捕捉细节(比如小众宝藏店)。
- 缺点:怕异常值(比如邻居那天心情不好乱推荐)。
- 适合:数据干净、想保留细节的场景(如手写数字识别)。
3.3.2 k 越大:听「全班意见」,可能平庸
- 例子:你问全班 50 个人(k=50),最终选了评分最高的连锁餐厅。
→ 虽然不踩雷,但可能错过你喜欢的特色小店(欠拟合,模糊了个体差异)。 - 优点:抗噪声(少数差评被稀释)。
- 缺点:忽略局部特征(比如你家楼下的隐藏好店)。
- 适合:数据噪声大、想平滑结果的场景(如用户偏好预测)。
4. 逻辑回归(Logistic Regression)
逻辑回归是一种用于处理分类问题的统计学习方法,它的训练数据集中既有特征变量(自变量),也有对应的类别标签(因变量)。模型通过学习这些数据来建立特征与类别之间的关系,从而能够根据新的特征数据预测其所属的类别。
原理:通过Sigmoid函数将线性组合映射到[0,1],输出概率值进行二分类,损失函数为交叉熵。参数估计使用最大似然法。
如何确定逻辑回归中的w和b呢?这里就要借用最大似然法
最大似然法:
最大似然法 =「数据侦探」 核心:根据结果反推最合理的「剧本」(参数)。
最大似然法是一种基于概率模型的参数估计方法,其核心思想是通过观测数据反推最可能生成这些数据的模型参数。
哪一个能最大可能的导致当前结果的发生【没洗碗,没回消息】


5. 决策树算法 Decision Tree
5.1决策树介绍:
决策树是通过一系列规则对数据进行分类的过程。它提供一种在什么条件下会得到什么值的类似规则的方法。
决策树分为分类树和回归树两种,分类树对离散变量做决策树,回归树对连续变量做决策树。
5.2划分选择:
不同的算法(ID3、C4.5、CART)在特征选择上使用不同的指标,但递归分割数据构建决策树的基本思想是一致的。
- 信息增益(ID3 算法):
信息熵:信息熵是用来衡量数据纯度的指标,它表示数据的不确定性程度。
信息增益:信息增益是指在划分数据集前后信息熵的减少量,它表示使用某个特征进行划分后,数据集的纯度提高了多少。
一般而言,信息增益越大,则意味着使用属性a来进行划分所获得的“纯度提升”越大,因此,我们可用信息增益来进行决策树的划分属性选择。
ID3 算法在构建决策树时,会选择信息增益最大的特征作为当前节点的分割特征。
增益率(C4.5 算法):
信息增益存在的问题:信息增益倾向于选择取值较多的特征,因为取值较多的特征会将数据集划分成更多的子集,从而使信息熵降低得更多。为了解决这个问题,C4.5 算法引入了增益率。
C4.5 算法在构建决策树时,会选择增益率最大的特征作为当前节点的分割特征。
- 基尼指数(CART 算法):
基尼指数:基尼指数也是用来衡量数据纯度的指标,它表示从数据集中随机抽取两个样本,其类别不一致的概率。
CART 算法在构建决策树时,会选择基尼指数最小的特征作为当前节点的分割特征。因为基尼指数越小,说明该特征对样本的分类效果越好,经过分割后得到的子节点数据纯度越高。
信息增益、增益率、基尼指数是决策树的 “灵魂指标”,其差异直接导致树结构和性能的分化。
信息增益、增益率、基尼指数是决策树的 “灵魂指标”,信息增益、增益率、基尼指数是决策树的特征选择方法,与线性回归、SVM、KNN 无关。信息增益等指标仅用于决策树的特征分裂,而线性回归、SVM、KNN 需通过其他方式(如系数、核函数、距离权重)间接关联特征重要性。若要比较它们在 “构建决策树时的性能”,实际是比较【不同决策树算法(ID3/C4.5/CART)】在相同数据集上的表现。
5.3决策树生成过程:
一棵决策树的生成过程主要分为以下3个部分:
- 特征选择: 是指从训练数据中众多的特征中选择一个特征作为当前节点的分裂标准,如何选择特征有着很多不同量化评估标准标准,从而衍生出不同的决策树算法。
- 决策树生成: 根据选择的特征评估标准,从上至下递归地生成子节点,直到数据集不可分则停止决策树停止生长。 树结构来说,递归结构是最容易理解的方式。
- 决策树剪枝: 决策树容易过拟合,一般来需要剪枝,缩小树结构规模、缓解过拟合。剪枝技术有预剪枝和后剪枝两种。
注意:对于那些各类别样本数量不一致的数据,在决策树当中信息增益的结果偏向于那些具有更多数值的特征。
5.4 剪枝处理
5.4.1 预剪枝
预剪枝是指在决策树生成过程中,对每个结点在划分前先进行估计,若当前结点的划分不能带来决策树泛化性能提升,则停止划分并将当前结点标记为叶结点;
5.4.2 后剪枝
后剪枝则是先从训练集生成一棵完整的决策树, 然后自底向上地对非叶结点进行考察,若将该结点对应的子树替换为叶结点能带来决策树泛化性能提升,则将该子树替换为叶结点。
6. k-平均算法 K-Means
6.1K-Means算法介绍

聚类:典型的无监督学习,它没有预先给定的类别标签,按照样本自身的特征,将相似度高的集中在一起。
k-平均算法(K-Means)是一种无监督学习算法,为聚类问题提供了一种解决方案。
K-Means 算法把 n 个点(可以是样本的一次观察或一个实例)划分到 k 个集群(cluster),使得每个点都属于离他最近的均值(即聚类中心,centroid)对应的集群。重复上述过程一直持续到重心不改变。
原理:通过迭代优化,将数据划分为K个簇,使簇内样本距离质心最近。目标是最小化簇内平方误差。

6.2K-means算法的缺点包括
- K必须是事先给定的
- 选择初始聚类中心
- 对于“噪声”和孤立点数据是敏感的
7. 随机森林算法 Random Forest

随机森林算法(Random Forest)的名称由 1995 年由贝尔实验室提出的random decision forests 而来,正如它的名字所说的那样,随机森林可以看作一个决策树的集合。
随机森林中每棵决策树估计一个分类,这个过程称为“投票(vote)”。理想情况下,我们根据每棵决策树的每个投票,选择最多投票的分类。
原理:集成多棵决策树,通过Bagging(有放回抽样)和随机特征选择降低方差,最终投票或平均结果。

8. 朴素贝叶斯算法 Naive Bayes
原理:
朴素贝叶斯的核心思想基于贝叶斯定理,通过计算后验概率来进行分类。其“朴素”之处在于假设特征之间是条件独立的,这一假设虽然在实际应用中并不总是成立,但在许多情况下,朴素贝叶斯依然能够取得令人满意的分类效果。这使得朴素贝叶斯成为许多实际应用中的首选模型,尤其是在处理高维数据和大规模数据集时,展现出其独特的优势。
贝叶斯学派(Bayesian)在概率模型的参数估计中,认为参数是未观察到的随机变量,并且可以为其假设一个先验分布(prior distribution)。然后,基于观测到的数据,通过贝叶斯定理计算参数的后验分布(posterior distribution)。这一过程体现了贝叶斯统计的核心思想: 将先验知识与观测数据结合,更新对参数的信念。
朴素贝叶斯是一种超级 “单纯” 的分类算法,核心思想就像 “看菜下饭”—— 通过统计 “特征组合” 出现的概率来判断类别。
朴素贝叶斯分类器,既然都分类了,那肯定是有监督学习。 它是利用贝叶斯定理的分类算法,假设属性条件独立,(x2,x2,``` xn),也就是自变量的多个特征之间相互独立。现在想要预测一个样本的类别yn,即类别c,给定x的条件下预测c,样本都给出了,p(x)也就没什么用了,只看上面即可。

例题西瓜甜不甜:





为什么叫 “朴素”?
因为它做了一个 “天真” 的假设:所有特征之间完全独立(比如西瓜的 “表皮” 和 “重量” 互不影响)。虽然现实中特征可能相关(比如重的西瓜可能更成熟,表皮更光滑),但这个假设让计算变得超级简单,而且在文本分类(如垃圾邮件过滤)等场景中效果惊人。
朴素贝叶斯就像一个 “统计小能手”,先数清楚每个类别里各个特征出现的次数,再假设特征之间互不干扰,最后用 “概率投票” 决定新样本的类别 —— 简单粗暴,但好用!
9. 降维算法 Dimensional Reduction
在机器学习和统计学领域,降维是指在限定条件下,降低随机变量个数,得到一组“不相关”主变量的过程,并可进一步细分为特征选择和特征提取两大方法。
一些数据集可能包含许多难以处理的变量。特别是资源丰富的情况下,系统中的数据将非常详细。在这种情况下,数据集可能包含数千个变量,其中大多数变量也可能是不必要的。在这种情况下,几乎不可能确定对我们的预测影响最大的变量。此时,我们需要使用降维算法,降维的过程中也可能需要用到其他算法,例如借用随机森林,决策树来识别最重要的变量。
原理:减少特征数量,保留主要信息。线性方法如PCA(主成分分析)通过方差最大化投影。
特点:
- 优点:降低计算成本,去除噪声,可视化高维数据
- 缺点:可能丢失部分信息(如PCA对非线性关系失效)
- 应用:图像压缩、数据预处理,用于特征工程阶段

10. 梯度增强算法 Gradient Boosting
梯度增强算法(Gradient Boosting)使用多个弱算法来创建更强大的精确算法。它与使用单个估计量不同,而是使用多个估计量创建一个更稳定和更健壮的算法。
原理:迭代训练弱学习器(通常为决策树),每轮拟合残差的负梯度,逐步减少损失函数(如MSE、交叉熵)。XGBoost、LightGBM为其优化版本。

GBDT(Gradient Boosting Decision Tree),全名叫梯度提升决策树,使用的是Boosting的思想。
10.1 Boosting思想
Boosting方法训练 基分类器 时采用串行的方式,各个 基分类器 之间有依赖。它的基本思路是将 基分类器 层层叠加,每一层在训练的时候,对前一层 基分类器 分错的样本,给予更高的权重。测试时,根据各层分类器的结果的加权得到最终结果。
10.2Bagging 与 Boosting 的核心区别?
| 对比维度 | Bagging | Boosting |
|---|---|---|
| 训练方式 | 并行训练多个基模型(基模型间无依赖) | 串行训练基模型(后一个模型依赖前一个模型的错误) |
| 样本选择 | 通过自助采样(Bootstrap)生成多个独立子集 | 每个基模型关注前一个模型误判的样本(调整样本权重或重新采样) |
| 基模型类型 | 通常为高方差、低偏差模型(如决策树) | 通常为低方差、高偏差模型(如弱分类器) |
| 误差处理 | 降低方差(通过平均 / 投票减少随机误差) | 降低偏差(通过逐步修正错误) |
| 并行性 | 支持并行训练(高效) | 只能顺序训练(耗时) |
| 结果聚合 | 多数投票(分类)或平均(回归) | 通过加权投票或累加残差(如 Gradient Boosting) |
| 过拟合风险 | 较低(因基模型独立且多样性高) | 较高(需控制迭代次数和学习率) |
| 典型算法 | 随机森林(Random Forest) | AdaBoost、梯度提升树(GBM)、XGB |
Bagging与Boosting的串行训练方式不同,Bagging方法在训练过程中,各基分类器之间无强依赖,可以进行并行训练。
10.3 GBDT原来是这么回事
GBDT的原理很简单,就是所有弱分类器的结果相加等于预测值,然后下一个弱分类器去拟合误差函数对预测值的残差(这个残差就是预测值与真实值之间的误差)。当然了,它里面的弱分类器的表现形式就是各棵树。
在 GBDT 里,当我们训练完足够多的决策树后,把每棵树的预测结果累加起来,再加上最初的基础预测值,就得到了一个非常接近真实值的预测结果。
面试常问:
- 「随机森林和 GBDT 的区别???」—— 前者是并行投票的「佛系树群」,后者是串行纠错的「卷王树群」
- 每个算法配一个简笔画小场景,比如 KNN 画 5 个小人围着新用户,SVM 画一条宽线隔开猫猫狗狗
11.逻辑回归
1.解释:
逻辑回归(Logistic Regression)主要解决二分类问题,用来表示某个事件发生的可能性。 逻辑回归这个算法的名称有一定的误导性。 虽然它的名称中有“回归”,当它在机器学习中不是回归算法,而是分类算法。因为采用了与回归类似的思想来解决分类问题,所以它的名称才会是逻辑回归。
在逻辑回归中,我们不是直接预测输出值,而是预测输出值属于某一特定类别的概率。例如,一封邮件是垃圾邮件的概率(是与不是),广告被点击的概率(点与不点)等。
简单来说:逻辑回归 = 线性回归 + Sigmoid函数(分类函数)。
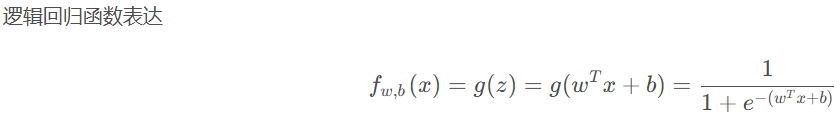
![]()

2.优点与缺点
优点:
- 简单而且容易实现。逻辑回归的模型相对简单,只需要对输入特征进行线性组合,然后通过Sigmoid函数进行分类预测。
- 计算效率高。逻辑回归的计算量相对较小,可以处理大规模的数据集。
- 可解释性强。逻辑回归的结果可以解释为某个事件发生的概率,比较直观易懂。
- 可以在线学习。逻辑回归可以通过梯度下降算法进行在线学习,适用于增量学习和实时预测。
缺点:
- 对特征的依赖性强。逻辑回归对特征之间的依赖性较为敏感,如果特征之间存在较强的相关性,会导致模型效果较差。
- 对异常值较为敏感。逻辑回归对异常值较为敏感,可能会影响模型的预测结果。
- 需要大量的特征工程。为了提高逻辑回归的性能,通常需要进行大量的特征工程,包括特征选择、特征变换等。
- 无法处理非线性问题。逻辑回归是一种线性模型,无法处理非线性问题,需要通过添加多项式特征或者引入核函数来解决非线性问题。
3.交叉数损失函数:
交叉熵损失函数在机器学习分类任务中是一个常用工具。 在机器学习的分类任务里,我们的目标是让模型的预测结果尽可能接近真实标签。交叉熵损失函数可以衡量模型预测的概率分布和真实标签的概率分布之间的差异程度。当差异越小,意味着模型的预测越准确,损失值也就越小;反之,差异越大,模型预测越不准确,损失值越大。多分类问题是其主要应用场景,比如图像分类、文本分类等。



4.sigmoid和softmax区别:
Sigmoid 函数将输入值转换为单个概率值, 而 Softmax 函数将输入值转换为一个概率分布。
输出范围
- Sigmoid 函数:其输出范围是(0, 1)。这意味着它可以将单个输入值转换为一个概率值,通常用于二分类问题中,比如判断一个样本属于正类还是负类。
- Softmax 函数:输出是一个概率分布,所有输出值的和为1。它常用于多分类问题,每个输出对应一个类别,其值表示样本属于该类别的概率。
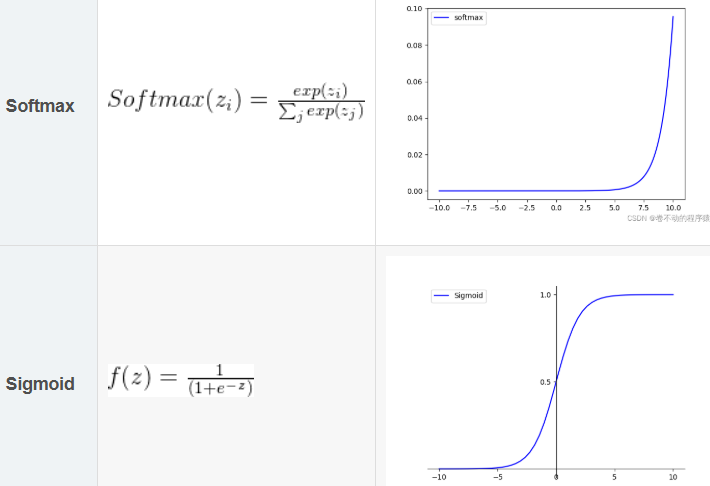
补充:
机器学习算法分类
机器学习算法大致可以分为三类:
- 监督学习算法 (Supervised Algorithms):
监督学习是指利用标记数据进行模型训练的学习方法,其训练数据集中包含输入特征以及对应的输出标签(目标值)。在训练过程中,模型通过学习输入特征与输出标签之间的映射关系,来对新的未知数据进行预测。
在监督学习训练过程中,可以由训练数据集学到或建立一个模式(函数 / learning model),并依此模式推测新的实例。该算法要求特定的输入/输出,首先需要决定使用哪种数据作为范例。例如,文字识别应用中一个手写的字符,或一行手写文字。主要算法包括神经网络、支持向量机、最近邻居法、朴素贝叶斯法、决策树等。
- 无监督学习算法 (Unsupervised Algorithms): 这类算法没有特定的目标输出,算法将数据集分为不同的组。
- 强化学习算法 (Reinforcement Algorithms): 强化学习普适性强,主要基于决策进行训练,算法根据输出结果(决策)的成功或错误来训练自己,通过大量经验训练优化后的算法将能够给出较好的预测。类似有机体在环境给予的奖励或惩罚的刺激下,逐步形成对刺激的预期,产生能获得最大利益的习惯性行为。
【一句话总结】
监督学习:跟着老师学(有标准答案)
无监督学习:自己找规律(无标准答案)
强化学习:边玩边学(用奖惩调参数)
基本的机器学习算法:
线性回归、支持向量机(SVM)、最近邻居(KNN)、逻辑回归、决策树、k平均、随机森林、朴素贝叶斯、降维、梯度增强。

神经网络算法实现+超参数:
像学习率这样的参数称为超参数。这是一种和神经网络的参数(权重和偏置)性质不同的参数。相对于神经网络的权重参数是通过训练数据和学习算法自动获得的,学习率这样的超参数则是人工设定的。一般来说,超参数需要尝试多个值,以便找到一种可以使学习顺利进行的设定。
神经网络的学习也要求梯度。这里所说的梯度是指损失函数关于权重参数的梯度。
误差: 我们把学习器的实际预测输出与样本的真实输出之间的差异称为“误 差 ”(error),学 习 器 在 训 练 集 上 的 误 差 称 为 “训 练 误 差 ”(training error)或 “经验误差”(empirical error),在新 样本上的误差称为 “泛 化 误 差 ”(generalization error)
前向传播:是指将输入数据从神经网络的输入层依次传递到输出层的过程。在这个过程中,数据通过各个隐藏层中的神经元进行处理,经过一系列的线性变换和非线性激活函数的作用,最终得到输出结果。
神经网络学习算法的实现:
前提神经网络存在合适的权重和偏置,调整权重和偏置以便拟合训练数据的过程称为“学习”。神经网络的学习分成下面4个步骤。
步骤1(mini-batch)
从训练数据中随机选出一部分数据,这部分数据称为mini-batch。我们的目标是减小mini-batch的损失函数的值。
步骤2(计算梯度)
为了减小mini-batch的损失函数的值,需要求出各个权重参数的梯度。梯度表示损失函数的值减小最多的方向。
步骤3(更新参数)
将权重参数 沿梯度方向 进行微小更新。
步骤4(重复)
重复步骤1、步骤2、步骤3。
神经网络的学习按照上面4个步骤进行。这个方法通过梯度下降法更新参数,不过因为这里使用的数据是随机选择的mini batch数据,所以又称为随机梯度下降法(stochastic gradient descent)。
epoch是什么?
epoch是一个单位。一个 epoch表示学习中所有训练数据均被使用过一次时的更新次数。比如,对于 10000笔训练数据,用大小为 100笔数据的mini-batch进行学习时,重复随机梯度下降法 100次,所有的训练数据就都被“看过”了A。此时,100次就是一个 epoch。
在上面的例子中,每经过一个epoch,就对所有的训练数据和测试数据计算识别精度,并记录结果。之所以要计算每一个epoch的识别精度,是因为如果在 for 语句的循环中一直计算识别精度,会花费太多时间。并且,也没有必要那么频繁地记录识别精度(只要从大方向上大致把握识别精度的推移就可以了)。因此,我们才会每经过一个epoch就记录一次训练数据的识别精度。


















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









