






- JVM高级
- 并发编程
- 框架源码
- 设计模式
- 分布式架构
- 微服务
- 数据库
- 工具
- JavaWeb
- Java高级
- 面试问什么?
- 根据你的岗位来的、
- 根据你的薪资来的
- 面试题不建议背,一定要需要理解
1:Java是什么类型的语言?
https://blog.youkuaiyun.com/qq_45905724/article/details/127094137#2Java_29
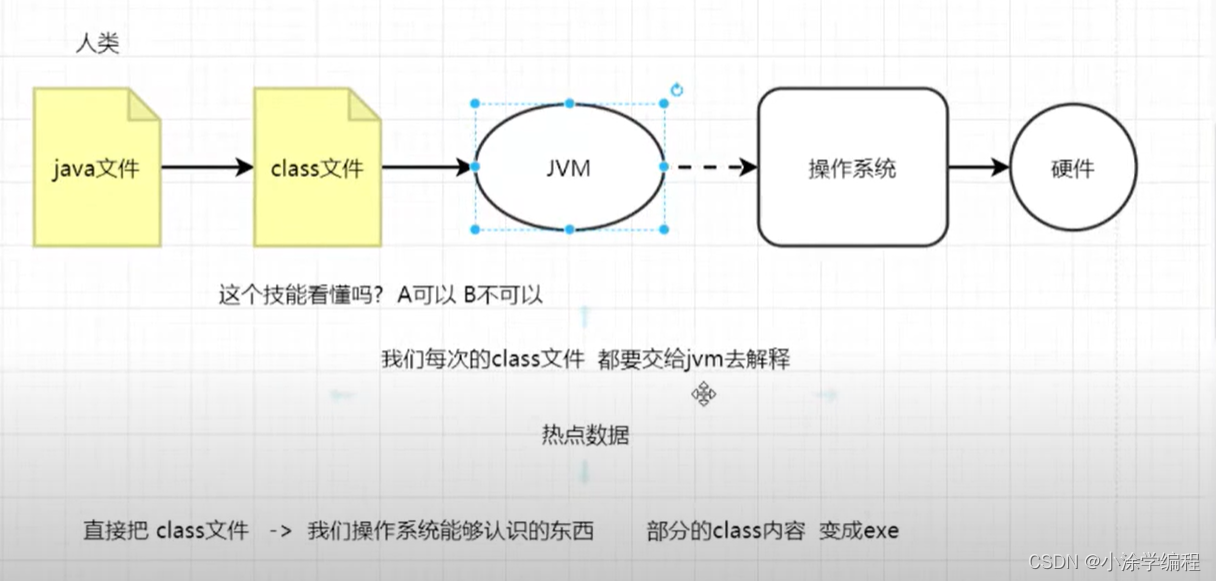
java是半编译半解释性语言。
从上图链接可以看出来Java执行到底是编译执行还是解释执行?
Java是一种编译型语言,所有的Java代码都需要经过javac编译为.class文件。但Java也是一种解释型语言,因为Java代码编译后的.class文件不能直接运行在操作系统上,还需要经过JVM解释为二进制代码。Java的执行过程可以分为以下几个步骤2:
- 编写Java源代码:开发人员使用Java语言编写程序的源代码。
- 编译:通过Java编译器将源代码编译成字节码文件(.class文件)。
- 类加载:Java虚拟机(JVM)通过类加载器将字节码文件加载到内存中。
- 解释执行:JVM将字节码文件解释成机器码,并在虚拟机上执行。
其实解释和编译是可以混合的,像一些常用的代码且用到的次数比较多,他会把代码的即时编译做成本地编译,下次在执行这种重复的代码的时候就不需要去通过字节码的解释器去进行解释操作,它会直接通过即时编辑器直接编译交给执行引擎进行执行。
2:简单说说Java中对象如何拷贝?
浅拷贝(Shallow Copy)和深拷贝(Deep Copy)是针对对象的状态而言。
浅拷贝创建一个新对象,并复制原始对象的所有非静态字段到新对象中。如果字段是值类型(如int, double, boolean等),则直接复制值。如果字段是引用类型,则复制引用,但不复制引用的对象本身。这意味着原始对象和拷贝后的对象将共享同一个引用对象的状态。
class Person { String name; Dog dog; // Dog是一个类,假设它也有自己的字段 // 构造函数、getter和setter省略 } class Dog { String breed; // 构造函数、getter和setter省略 } public class ShallowCopyExample { public static void main(String[] args) { Person person1 = new Person(); person1.name = "Alice"; person1.dog = new Dog(); person1.dog.breed = "Labrador"; // 浅拷贝 Person person2 = new Person(); person2.name = person1.name; // 复制值 person2.dog = person1.dog; // 复制引用,不复制Dog对象 // 现在person1和person2的dog字段引用同一个Dog对象 person2.dog.breed = "Bulldog"; // 修改person2的dog引用的Dog对象 // 这将影响person1的dog字段,因为它们引用同一个对象 System.out.println(person1.dog.breed); // 输出 "Bulldog" } }在这个例子中,
person2是person1的浅拷贝。当我们改变person2.dog的breed属性时,由于person1.dog和person2.dog引用的是同一个Dog对象,因此person1.dog的breed属性也会被改变。
浅拷贝:
浅拷贝只复制对象本身和对象中的基本数据类型字段,而不复制对象中的引用类型字段。在浅拷贝中,新对象和原始对象中的引用类型字段将引用相同的对象。
使用clone()方法进行浅拷贝:
class Person implements Cloneable {
private String name;
private int age;
@Override
protected Object clone() throws CloneNotSupportedException {
return super.clone();
}
}
// 使用clone()方法进行浅拷贝
Person original = new Person();
Person copy = (Person) original.clone();
深拷贝:
深拷贝会复制对象本身以及对象中的所有引用类型字段,创建一个全新的对象,新对象中的引用类型字段引用的是新的对象,而不是原始对象中引用的对象。
import java.io.*;
class Person implements Serializable {
private String name;
private int age;
public Person deepCopy() throws IOException, ClassNotFoundException {
ByteArrayOutputStream bos = new ByteArrayOutputStream();
ObjectOutputStream oos = new ObjectOutputStream(bos);
oos.writeObject(this);
ByteArrayInputStream bis = new ByteArrayInputStream(bos.toByteArray());
ObjectInputStream ois = new ObjectInputStream(bis);
return (Person) ois.readObject();
}
}
// 使用序列化和反序列化进行深拷贝
Person original = new Person();
Person copy = original.deepCopy();
3:Int 与 Integer 区别
- Integer是int的包装类,int则是java的一种基本数据类型
- Integer变量必须实例化后才能使用,而int变量不需要
- Integer实际是对象的引用,当new一个Integer时,实际上是生成一个指针指向此对象;而int则是直接存储数据值
- Integer的默认值是null,int的默认值是0
包装类Integer和基本数据类型int比较时,java会自动拆包装
java在编译Integer i = 100;时,会翻译成为Integer i = Integer.valueOf(100);,而java API中对Integer类型的valueOf的定义如下:
public static Integer valueof(int i){ assert IntegerCache.high >= 127; if (i > Integercache. low & i < Integercache.high){ return IntegerCache.cache[i +(-IntegerCache.low)]; } return new Integer(i); }java对于-128到127之间的数,会进行缓存,Integer i=127时,会将127进行缓存,下次再写Integerj=127时,就会直接从缓存中取




4:什么是Object有哪些常用的方法,怎么创建对象?
什么是Object有哪些常用的方法?
toString(): 返回对象的字符串表示形式。equals(Object obj): 比较对象是否相等。hashCode(): 返回对象的哈希码值。getClass(): 返回对象的运行时类。clone(): 创建并返回对象的一个副本。finalize(): 在对象被垃圾回收器回收之前调用。notify(): 唤醒在对象上等待的单个线程。notifyAll(): 唤醒在对象上等待的所有线程。wait(): 导致当前线程等待,直到其他线程调用notify()或notifyAll()方法唤醒。wait(long timeout): 导致当前线程等待指定的毫秒数。wait(long timeout, int nanos): 导致当前线程等待指定的毫秒数加上额外的纳秒数。怎么创建对象?
创建对象的本质就是在内存空间的堆区申请一块存储区域,用于存放该对象独有特征信息。
- 使用new关键字
ClassName objectName = new ClassName();
- Class的newInstance
public class MyClass { private String message; public MyClass() { this.message = "Hello, World!"; } public void displayMessage() { System.out.println(message); } } public class Main { public static void main(String[] args) throws Exception { Class<?> myClass = MyClass.class; MyClass obj = (MyClass) myClass.newInstance(); obj.displayMessage(); } }
- Constructor newInstance
import java.lang.reflect.Constructor; public class MyClass { private String message; public MyClass(String message) { this.message = message; } public void displayMessage() { System.out.println(message); } public static void main(String[] args) throws Exception { Class<?> myClass = MyClass.class; // 获取带一个String参数的构造函数 Constructor<?> constructor = myClass.getConstructor(String.class); // 传递参数并创建对象 MyClass obj = (MyClass) constructor.newInstance("Hello, Constructor.newInstance!"); // 调用对象的方法 obj.displayMessage(); } }
- clone方法
class Person implements Cloneable { private String name; private int age; public Person(String name, int age) { this.name = name; this.age = age; } @Override public Object clone() throws CloneNotSupportedException { return super.clone(); } public void displayInfo() { System.out.println("Name: " + name + ", Age: " + age); } public static void main(String[] args) { Person original = new Person("Alice", 30); try { // 使用clone()方法创建对象的副本 Person copy = (Person) original.clone(); copy.displayInfo(); } catch (CloneNotSupportedException e) { e.printStackTrace(); } } }
- 使用反序列化
创建一个可序列化的类: import java.io.Serializable; public class Person implements Serializable { private String name; private int age; public Person(String name, int age) { this.name = name; this.age = age; } public void displayInfo() { System.out.println("Name: " + name + ", Age: " + age); } } 将对象序列化到文件: import java.io.*; public class SerializationExample { public static void main(String[] args) { Person person = new Person("Alice", 30); try (ObjectOutputStream out = new ObjectOutputStream(new FileOutputStream("person.ser"))) { out.writeObject(person); } catch (IOException e) { e.printStackTrace(); } } } 从文件中反序列化对象: import java.io.*; public class DeserializationExample { public static void main(String[] args) { try (ObjectInputStream in = new ObjectInputStream(new FileInputStream("person.ser"))) { Person person = (Person) in.readObject(); person.displayInfo(); } catch (IOException | ClassNotFoundException e) { e.printStackTrace(); } } }为什么我们唤醒线程的方法是在Object里面;不是应该在线程Thread里面吗?
object里面存的锁信息
5. 重载、重写
- 重写(override)又名覆盖:
- 不能存在同一个类中,在继承或实现关系的类中;
- 名相同,参数列表相同,方法返回值相同,
- 子类方法的访问修饰符要大于父类的。
- 子类的检查异常类型要小于父类的检查异常。
- 重载(overload)
- 可以在一个类中也可以在继承关系的类中;
- 名相同;
- 参数列表不同(个数,顺序,类型) 和方法的返回值类型无关。
6. 多态面向接口编程?聊聊你的认知
1.制订标准 :实现这个接口
2.提高可扩展性
让你设计一个接口,你会考虑到那个点?
设计原则:
-
单一职责原则(SRP): 一个接口应该只有一个引起变化的原因,即一个接口应该只负责一个功能。
-
开闭原则(OCP): 接口应该对扩展开放,对修改关闭,可以通过扩展接口来添加新功能,而不是修改现有接口。
-
里氏替换原则(LSP): 任何时候都可以用子类型替换掉父类型。子类一定是增加父类的能力而不是减少父类的能力,因为子类比父类的能力更多。子类对象应该能够替换掉父类对象并且不影响程序的行为,接口设计应该保证实现类能够完全替代接口。
-
依赖倒置原则(DIP): 高层模块不应该依赖于低层模块,二者都应该依赖于抽象,接口设计应该便于依赖注入和解耦。
-
接口隔离原则(ISP): 接口应该小而专,避免定义臃肿的接口,应该根据功能需求拆分接口,避免接口臃肿和冗余。
7. String StringBuffer StringBuilder 的区别
- String. StringBuffer. StringBuilder都是final类,都不允许被继承;
- String长度是不可变的, StringBuffer、 StringBuilder长度是可变的;
- StringBuffer是线程安全的,StringBuilder不是线程安全的,但它们两个中的所有方法都是相同的,StringBuffer在StringBuilder的方法之上添加了synchronized修饰,保证线程安全。
- StringBuilder比StringBuffer拥有更好的性能。
- 如果一个String类型的字符串,在编译时就可以确定是一个字符串常量,则编译完成之后,会进行常量折叠,字符串会自动拼接成一个常量。此时String的速度比StringBuffer和StringBuilder的性能好的多。
8. String不可变原因
- 提高效率:比如一个字符串 Stirng s1=“abc”,“abc”被放到常量池里面去了,我再String s2 = "abc"并不会复制字符串“abc",只会多个引用指向原来那个常量,这样就提高了效率,而这一前提是 string不可变,如果可变,那么多个引用指向同一个字符串常量,我就可以通过一个引用改变字符串,然后其他引用就被影响了
- 安全: String常被用来表示url,文件路径,如果 String可变,或存在安全隐患
- String不可变,那么他的hashcode就一样,不用每次重新计算了
每次使用
+符号拼接字符串时,Java都会创建一个新的String对象,这会导致大量的内存分配和垃圾收集,从而降低性能。为了避免这种情况,Java编译器会优化这些操作,使用StringBuilder(或StringBuffer)来执行实际的字符串拼接,然后在最后生成一个最终的String对象。举个例子,当你执行以下代码:
String s = "Hello" + " " + "World";
实际上,编译器会将其转换为类似于以下的形式:
String s = new StringBuilder().append("Hello").append(" ").append("World").toString();
9. String 中的 hashcode 以及 toString
String有重写Object的hashcode和toString吗?如果重写equals不重写hashcode会出现什么问题?
String重写了Object类的hashcode和toString方法。
/**
* Returns a hash code for this string. The hash code for a
* {@code String} object is computed as
* <blockquote><pre>
* s[0]*31^(n-1) + s[1]*31^(n-2) + ... + s[n-1]
* </pre></blockquote>
* using {@code int} arithmetic, where {@code s[i]} is the
* <i>i</i>th character of the string, {@code n} is the length of
* the string, and {@code ^} indicates exponentiation.
* (The hash value of the empty string is zero.)
*
* @return a hash code value for this object.
*/
public int hashCode() {
int h = hash;
if (h == 0 && value.length > 0) {
char val[] = value;
for (int i = 0; i < value.length; i++) {
h = 31 * h + val[i];
}
hash = h;
}
return h;
}
/**
* This object (which is already a string!) is itself returned.
*
* @return the string itself.
*/
public String toString() {
return this;
}当equals方法被重写时,通常有必要重写hashCode方法,以维护hashCode方法的常规协定,该协定声明相对等的两个对象必须有相同的hashCode。
- object1.euqal(object2)时为true,object1.hashCode() == object2.hashCode()为true
- object1.hashCode()== object2.hashCode()为false时,object1.euqal(object2)必定为false
- object1.hashCode()== object2.hashCode()为true时,但object1.euqal(object2)不一定定为true
重写equals不重写hashcode会出现什么问题 ?
在存储散列集合时(如Set类),如果原对象.equals(新对象),但没有对hashCode重写,即两个对象拥有不同的hashCode,则在集合中将会存储两个值相同的对象,从而导致混淆。因此在重写equals方法时,必须重写hashCode方法。
10. java反射
反射机制是在运行状态中,对于任意一个类,都能够知道这个类的所有属性和方法;
对于任意一个对象,都能够调用它的任意一个方法和属性;
这种动态获取的信息以及动态调用对象的方法的功能称为java语言的反射机制。
获取 Class对象方法:
- class.getClass(),
- Class.forname,
- CalssLoader.loadClass
Class.forName 与 classloader.loadClass区别
初始化不同:
- Class.forName()会对类初始化,而 loadClass()只会装载或链接。
- foranme在类加载的时候回执行静态代码块(初始化了), loadclass只有在调用newlnstance方法的时候才会执行静态代码块
类加载器不同:
- Class.forName(String)方法(只有一个参数),使用调用者的类加载器来加载,也就是用加载了调用forName方法的代码的那个类加载器
- ClassLoader.loadClass()方法是一个实例方法(非静态方法),调用时需要自己指定类加载器
11. 接口和抽象类的区别?
接口(Interface):
-
定义: 接口是一种抽象类型,只包含方法的声明,没有方法的实现。接口中的方法默认是
public abstract,字段默认是public static final。 -
多继承: 类可以实现多个接口,从而实现多继承的效果。
-
功能限制: 接口只能包含方法声明、常量和默认方法(Java 8及以后版本还支持静态方法、私有方法),不能包含成员变量和构造方法。
-
实现灵活: 接口提供了一种规范,实现接口的类必须实现接口中定义的所有方法,从而保证了代码的一致性。
-
解耦性强: 接口可以降低类之间的耦合度,提高代码的灵活性和可维护性。
抽象类(Abstract Class):
-
定义: 抽象类是一种类,可以包含抽象方法(方法声明但没有实现)和具体方法(有实现的方法)。
-
单继承: 类只能继承一个抽象类,Java不支持多重继承。
-
功能丰富: 抽象类可以包含成员变量、构造方法、普通方法以及抽象方法。
-
代码重用: 抽象类可以提供一些通用的方法实现,子类可以重写这些方法,实现代码的重用。
-
设计层次: 抽象类适合用于定义类的层次结构,提供一些通用行为,子类可以根据需要进行扩展或重写。
-
什么是内部类说说你对他的理解以及实战场景
成员内部类、局部内部类、匿名内部类
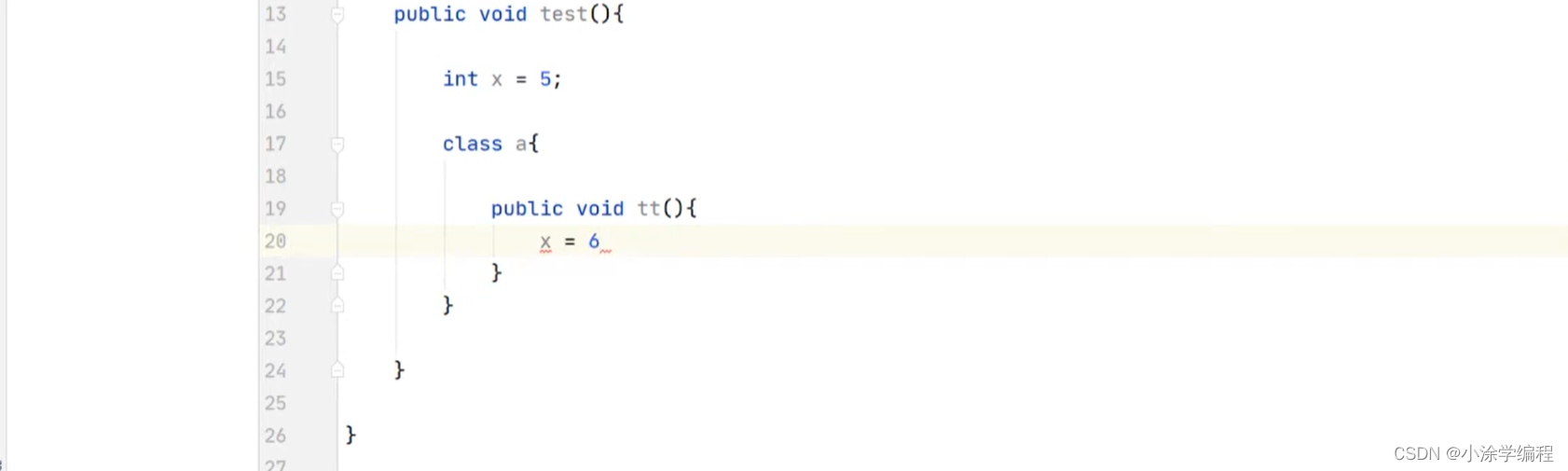
下面代码为什么不行,局部内部类只能使用final 变量
12 .说说static和final在Java中的意义
static关键字:
-
静态变量(static variable): 使用
static关键字声明的变量是静态变量,它们属于类而不是实例,所有实例共享同一个静态变量的值。 -
静态方法(static method): 使用
static关键字声明的方法是静态方法,可以直接通过类名调用,无需实例化对象。 -
静态代码块(static block): 静态代码块在类加载时执行,用于初始化静态变量或执行一些静态操作。
-
静态内部类(static inner class): 使用
static关键字声明的内部类是静态内部类,可以直接通过外部类名访问,不需要依赖外部类的实例。 -
静态导入(static import): 通过静态导入可以直接使用类的静态成员,而不需要使用类名限定。
final关键字:
-
常量(constant): 使用
final关键字声明的变量是常量,一旦赋值后不可修改,常量通常用大写字母命名。 -
不可继承: 使用
final关键字修饰的类不能被继承,避免子类修改其行为。 -
不可重写: 使用
final关键字修饰的方法不能被子类重写,确保方法行为不会被改变。 -
不可更改引用: 使用
final关键字修饰的引用变量不能再指向其他对象,但对象本身的内容可以改变。
static不能修饰局部变量,构造函数,this关键字,super关键字
static的代码块与字段谁先加载?
在Java中,静态代码块(static block)会在静态字段(static fields)之前加载。当一个类被加载时,静态代码块会在静态字段初始化之前执行。这确保了静态代码块中的操作在静态字段被访问之前得到执行。
子类里面有static ,是先加载父类还是子类?
在Java中,当子类中包含静态成员(静态字段或静态方法)时,无论子类中是否有静态成员,父类的静态成员都会在子类的静态成员之前被加载和初始化。这意味着在类加载的过程中,父类的静态成员会首先被加载,然后才是子类的静态成员。
13:Java中的基本数据类型占多少学节不同的操作系统一样吗?
在Java中,基本数据类型的大小是规定好的,不会因为不同的操作系统而有所变化。这是因为Java的基本数据类型的大小是由Java虚拟机(JVM)规范确定的,而不是取决于具体的操作系统。
14:int和lnteger有什么关联?为什么需要Integer?装箱拆箱
泛型支持:泛型只能接受对象,不能接受基本数据类型
集合类操作:集合类(如List、Map)只能存储对象,不支持基本数据类型
对象操作:使用对象的方法或在方法参数中传递对象等一些一些特定的操作需要将基本数据类型转换为对象
空值表示:基本数据类型不能表示空值
为什么需要8种包装类型?因为java是面对对象的语言
List<对象>
15:什么是序列化,反序列化说说运用场景
dubbo rpc远程调用 A应用的实例对象传递到B应用的实例对象
16.数组有length()方法吗?
在Java中,数组是一种特殊的数据结构,它是一个固定大小的有序集合。数组在Java中是通过length属性而不是方法来获取其长度。因此,数组没有length()方法,而是有一个length属性用于获取数组的长度。
17 .Java网络编程的三种模型
BIO同步并阻塞,服务器实现模式为一个连接一个线程,即客户端有连接请求时服务器端就需要启动一个线程进行处理,如果这个连接不做任何事情会造成不必要的线程开销,当然可以通过线程池机制改善。()
NIO同步非阻塞,服务器实现模式为一个请求一个线程,即客户端发送的连接请求都会注册到多路复用器上,多路复用器轮询到连接有/0请求时才启动一个线程进行处理。
AlO异步非阻塞,服务器实现模式为一个有效请求一个线程,客户端的I/O请求都是由OS先完成了再通知服务器应用去启动线程进行处理
- BIO是同步阻塞IO,使用BIO读取数据时,线程会阻塞住,且需要线程主动去查询是否有数据可读,并且需要处理完一个Socket之后才能处理下一个Socket;
- NIO是同步非阻塞IO,使用NIO读取数据时,线程不会阻塞,但需要线程主动的去查询是否有IO事件;
- AIO也叫做NIO2.0,是异步非阻塞IO,使用AIO读取数据时,线程不会阻塞,并且当有数据可读时会通知到线程,不需要线程主动去查
15:集合原理系列
ArrayList
Linkedlist Queue Deque
Hashset Treeset
HashMap TreeMap HashTable
ArrayList
LinkedList Queue Deque
HashSet TreeSet
16:Enumeration接口和lterator接口的区别有哪些?
17:异常
也是一种代码分支的实现方式?
18:什么是事务?为什么需要事务?如何实现事务?事务隔离级别
事务(Transaction):
在数据库管理系统中,事务是一组操作(或一系列操作),被视为一个不可分割的工作单元,要么全部执行成功,要么全部执行失败。事务具有四个特性,通常表示为ACID:
-
原子性(Atomicity): 事务是一个原子操作,要么全部执行成功,要么全部执行失败。
-
一致性(Consistency): 事务执行前后,数据库的状态必须保持一致。
-
隔离性(Isolation): 多个事务并发执行时,事务之间应该相互隔离,避免相互影响。
-
持久性(Durability): 一旦事务提交,其结果应该是持久的,即使系统故障也不会丢失。
为什么需要事务?
-
数据完整性: 通过事务可以保证数据的完整性,避免数据不一致的情况。
-
并发控制: 事务可以确保多个并发操作不会导致数据混乱或丢失。
-
错误回滚: 如果事务执行失败,可以回滚到事务开始前的状态,避免数据损坏。
如何实现事务?
在关系型数据库中,事务可以通过以下方式实现:
-
使用SQL语句: 数据库提供了事务相关的SQL语句,如
BEGIN TRANSACTION、COMMIT、ROLLBACK等来控制事务的开始、提交和回滚。 -
使用编程语言支持: 在编程中通过数据库连接对象开启事务、提交事务或回滚事务。
-
使用ORM框架: ORM(Object-Relational Mapping)框架通常提供了事务管理的功能,简化了事务控制的操作。
事务隔离级别(Transaction Isolation Levels):
在数据库中,事务隔离级别定义了事务之间的隔离程度,主要包括以下四种隔离级别:
-
READ UNCOMMITTED(读取未提交数据): 允许一个事务读取另一个事务未提交的数据,最低的隔离级别,可能导致脏读、不可重复读和幻读。
-
READ COMMITTED(读取已提交数据): 一个事务只能读取另一个事务已提交的数据,可以避免脏读,但仍可能出现不可重复读和幻读。
-
REPEATABLE READ(可重复读): 保证在同一事务中多次读取相同数据时,数据保持一致,可以避免脏读和不可重复读,但仍可能出现幻读。
-
SERIALIZABLE(串行化): 最高的隔离级别,确保事务串行执行,避免脏读、不可重复读和幻读,但可能降低并发性能。
类型有几种jdbc事务,jta事务,容器事务
19:java修饰符以及个字的作用范围
4中 public protect 缺省 private
1:什么是linux?如何安装使用linux
2:说说你常用的1inux查看文件和文件夹命令
3:常用查看文件的命令有哪些?
4:如何递归删除文件夹和所有文件?
5:如何拷贝,移动一个文件?
6:如何查找一个文件?
7:你还是使用过哪些常用的1inux命令?
8:grep是什么命令?man是什么命令?
9:chmod是什么命令?
10:VI、VIM是什么?
1:什么是servlet,jsp?
2:web.xml在web项目中有什么作用?
3:说说servlet的原理
4:jsp里面的内置对象
5:什么是cookie?有什么作用?
6:什么是session?有什么作用?
7:禁用客户端cookie,如何实现session?
8:dopostdoget的区别?还有哪些请求类型?
9:Forward和Redirect的区别?
10:HTTP响应的结构是怎么样的
1:什么是框架?如何使用框架?
2:SSM,SSH,JPA,mybatisplus,及其实现原理?
3:简单说一下Spring的IOC,以及DI
4:简单说一下SpringAOP
5:什么是ORM
6:简要描述一下SSM如何进行整合
7:@RequestMapping及其系列注解
8:springmvc如何处理ajax请求?
9:Mybatis优缺点分析
10:#)和$的区别是什么?
11:实体类属性和数据表字段不一样如何处理?
12:为什么说Mybatis是半自动ORM映射工具?它与全自动的区别在哪里?
13:什么是一对一,一对多,多对多?mybatis中如何实现?
nginx
1:什么是nginx?
Nginx(发音为"engine-x")是一个高性能的开源Web服务器软件,也可以用作反向代理服务器、负载均衡器、HTTP缓存以及作为邮件代理服务器
2:什么是负戟均衡?
负载均衡(Load Balancing)是一种技术,用于在多个服务器之间分配工作负载,以确保每台服务器都能有效地处理请求并避免出现单点故障
3:什么是动静分离?
动静分离(Dynamic-Static Separation)是一种常见的Web服务器优化策略,旨在提高网站的性能和效率。该策略将动态内容和静态内容分开存放和处理,以便更有效地处理不同类型的内容请求。
4:什么是反向代理?
反向代理(Reverse Proxy)是一种代理服务器的部署方式,它代表服务器处理客户端的请求,并将这些请求转发给内部服务器
5:nginx如何配置动静分离,反向代理?
要配置Nginx实现动静分离和反向代理,你可以按照以下步骤进行操作:
配置动静分离:
- 准备静态资源: 将静态资源(如HTML文件、图片、CSS、JavaScript等)放置在指定的目录下,例如
/var/www/static/。 - 配置Nginx: 修改Nginx的配置文件(通常是
nginx.conf或在/etc/nginx/sites-available/目录下的配置文件)。 - 配置静态资源服务: 在Nginx配置文件中添加一个静态资源服务的配置块,指定静态资源的根目录和访问规则。例如:
-
server { listen 80; server_name your_domain.com; location /static/ { alias /var/www/static/; } # Other server configurations } - 重启Nginx: 保存配置文件并重启Nginx服务,使配置生效。
配置反向代理:
- 准备后端服务器: 确保后端服务器已经准备好,并可以响应客户端请求。
- 配置Nginx: 在Nginx配置文件中添加一个反向代理的配置块,指定代理的目标服务器。例如:
-
server { listen 80; server_name your_domain.com; location / { proxy_pass http://backend_server_ip:backend_port; proxy_set_header Host $host; proxy_set_header X-Real-IP $remote_addr; } # Other server configurations } - 重启Nginx: 保存配置文件并重启Nginx服务,使配置生效。
在Nginx中成功配置动静分离和反向代理,实现静态资源与动态内容的分离以及将客户端请求代理到后端服务器。
6:如何搭建伪集群?
假设你想搭建一个简单的Web服务器伪集群,可以按照以下步骤进行:
- 创建三个虚拟机/容器,分别代表三台Web服务器节点。
- 在每个节点上安装Nginx作为Web服务器。
- 在一个节点上配置Nginx作为负载均衡器,将请求分发给其他两个节点。
- 测试集群的负载均衡功能,访问负载均衡器的IP地址,观察请求是否被均衡分发到不同节点。
7:如何搭建集群?
假设你想搭建一个基于Kubernetes的容器集群,可以按照以下步骤进行:
- 准备多台服务器,至少需要一台Master节点和多个Worker节点。
- 在每台服务器上安装Docker和Kubernetes组件。
- 配置Kubernetes集群,包括初始化Master节点、加入Worker节点等操作。
- 部署容器化的应用程序到集群中,通过Kubernetes进行管理和调度。
- 测试集群的负载均衡、自动伸缩等功能,确保集群正常运行。
8:简要说一下nginx每个配置项的作用.
-
worker_processes: 指定Nginx工作进程的数量,通常设置为服务器的CPU核心数,用于处理客户端请求。 -
events: 定义Nginx如何处理事件,如连接数、超时等设置。 -
http: 定义HTTP协议相关的配置项,包括HTTP服务器、代理、缓存等设置。 -
server: 定义一个虚拟主机(server block),包括监听端口、域名、SSL配置等。 -
location: 在server块内部定义请求匹配规则和处理方式,可以用于处理不同URL路径的请求。 -
root: 指定Nginx服务器的根目录,用于存放网站的静态文件。 -
proxy_pass: 用于配置反向代理,将请求代理到指定的后端服务器。 -
try_files: 定义Nginx在尝试不同文件或路径后返回响应的顺序。 -
index: 指定默认的索引文件,当访问目录时,Nginx会尝试返回指定的文件。 -
error_page: 定义错误页面的处理方式,可以指定不同HTTP状态码对应的错误页面。 -
proxy_set_header: 设置传递给后端服务器的HTTP请求头信息。 -
ssl_certificate和ssl_certificate_key: 配置SSL证书和私钥,用于启用HTTPS协议。 -
gzip: 开启或关闭Gzip压缩,用于压缩传输的数据减少带宽占用。 -
include: 引入其他配置文件,可以将一些通用配置单独放在一个文件中,提高配置文件的可读性和维护性。
1:nginx_http节点有什么作用?
nginx_http节点用于定义全局的HTTP配置
2:nginx_http_upstream节点有什么用?
nginx_http_upstream节点用于定义后端服务器的集群,用于负载均衡。
3:nginx_http_server节点有什么作用?
nginx_http_server节点用于定义虚拟主机,处理特定域名或IP的请求
4: nginx_http_server_location节点有什么作用?
nginx_http_server_location节点用于定义server块内部的请求匹配规则和处理方式。
5:如何配置nginx伪集群,简要写一下nginx.conf的配置
worker_processes 2; # 设置Nginx工作进程数为2
events {
worker_connections 1024;
}
http {
upstream backend { # 包含了三个后端服务器的地址
server backend1.example.com;
server backend2.example.com;
server backend3.example.com;
}
server { #监听80端口
listen 80;
server_name your_domain.com;
location / {
proxy_pass http://backend;
proxy_set_header Host $host;
proxy_set_header X-Real-IP $remote_addr;
}
}
}
9:如何配置轮询策略,ip_hash策略,权重策略,备份?
配置轮询(Round Robin)策略:
upstream backend {
server backend1.example.com;
server backend2.example.com;
server backend3.example.com;
}
配置IP哈希(IP Hash)策略:
upstream backend {
ip_hash;
server backend1.example.com;
server backend2.example.com;
server backend3.example.com;
}
配置权重(Weighted)策略:
upstream backend {
server backend1.example.com weight=3;
server backend2.example.com weight=2;
server backend3.example.com weight=1;
}
配置备份服务器:
upstream backend {
server backend1.example.com;
server backend2.example.com backup;
}

















 70万+
70万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









