




 本文总结了多模态大模型如GroundingDINO、CLIP和EVA-CLIP的研究,涵盖了深度学习基础知识,包括批量归一化、卷积模型计算、多分类损失函数等。还介绍了视频分类技术,如EarlyFusion、LateFusion和3DCNN,以及如何处理长视频序列的方法,如Self-Attention的应用。
本文总结了多模态大模型如GroundingDINO、CLIP和EVA-CLIP的研究,涵盖了深度学习基础知识,包括批量归一化、卷积模型计算、多分类损失函数等。还介绍了视频分类技术,如EarlyFusion、LateFusion和3DCNN,以及如何处理长视频序列的方法,如Self-Attention的应用。
🐧大模型系列篇章
💖 多模态大模型 🔎 GroundingDINO 论文总结
💖 端到端目标检测 🔎 从DETR 到 GroundingDINO 🔥
💖 多模态大模型 👉 CLIP论文总结
💖 多模态大模型 👉 EVA-CLIP
💚 生成模型 👉 从 VAE 到 Diffusion Model (上)
💚 生成模型 👉 从 VAE 到 Diffusion Model (下)🔥
💧 天气大模型
🐧深度学习基础知识篇
💖 深度学习基础知识干货 🔎 Batch Normalization 批量归一化
💖 深度学习基础知识干货 🔎 卷积模型的Memory, Params, Flop是如何计算的?
💖 深度学习基础知识干货 🔎 Cross-Entropy Loss 多分类损失函数
💖 深度学习基础知识干货 🔎 Videos 动作检测
💖 深度学习基础知识干货 🔎 目标检测(Object Detection): 你需要知道的一些概念
💖 深度学习基础知识干货 🔎 微调(fine-tuning)和泛化(generalization)
💖 深度学习基础知识干货 🔎 Group Convolution / Depthwise Convolution 轻量模型的必有的卷积
💖 深度学习基础知识干货 🔎 Gradient checkpointing
💖 深度学习基础知识干货 🔎 Softmax中温度(temperature)参数
💖 深度学习基础知识干货 🔎 什么是few-shot learning
| 欢迎订阅专栏,第一时间掌握最新科技 大模型系列篇章 专栏链接 深度学习基础知识 专栏链接 |
文章目录
Video Classification
Early Fusion, Late Fusion, 3D CNN,
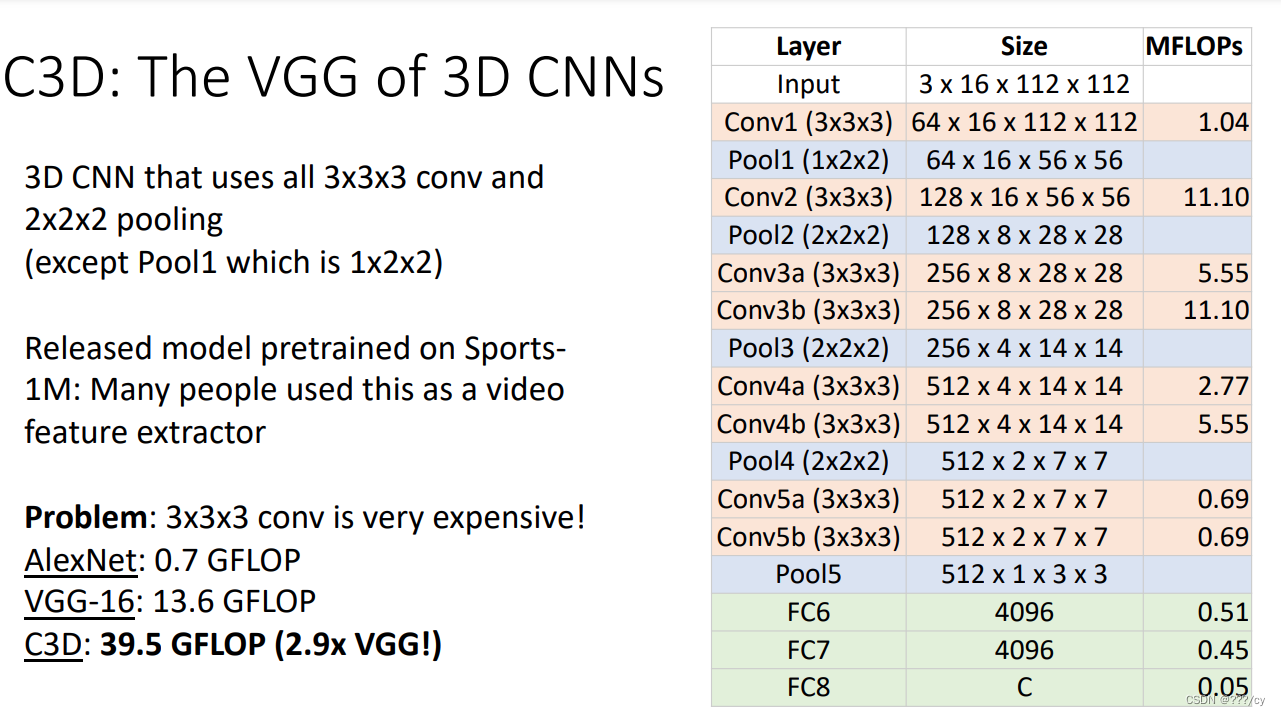
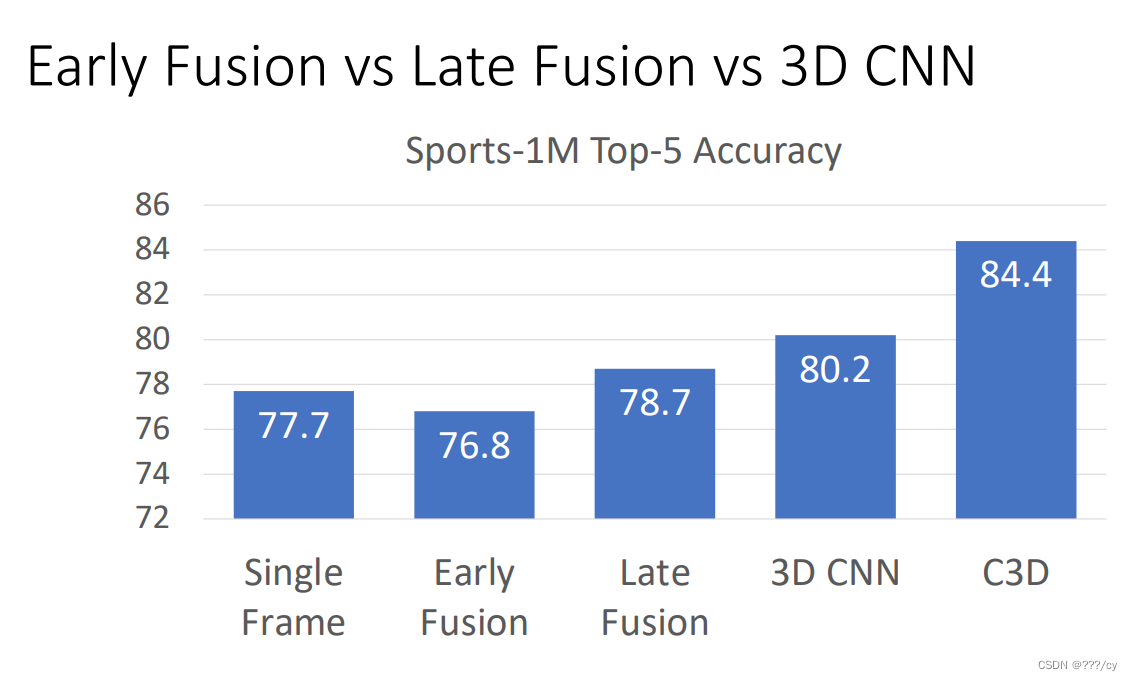
Recognizing Actions from Motion 从动作中识别行为
- Measuring Motion: Optical Flow
- Separating Motion and Appearance: Two-Stream Networks: Images(空间信息), Flow(时间信息)
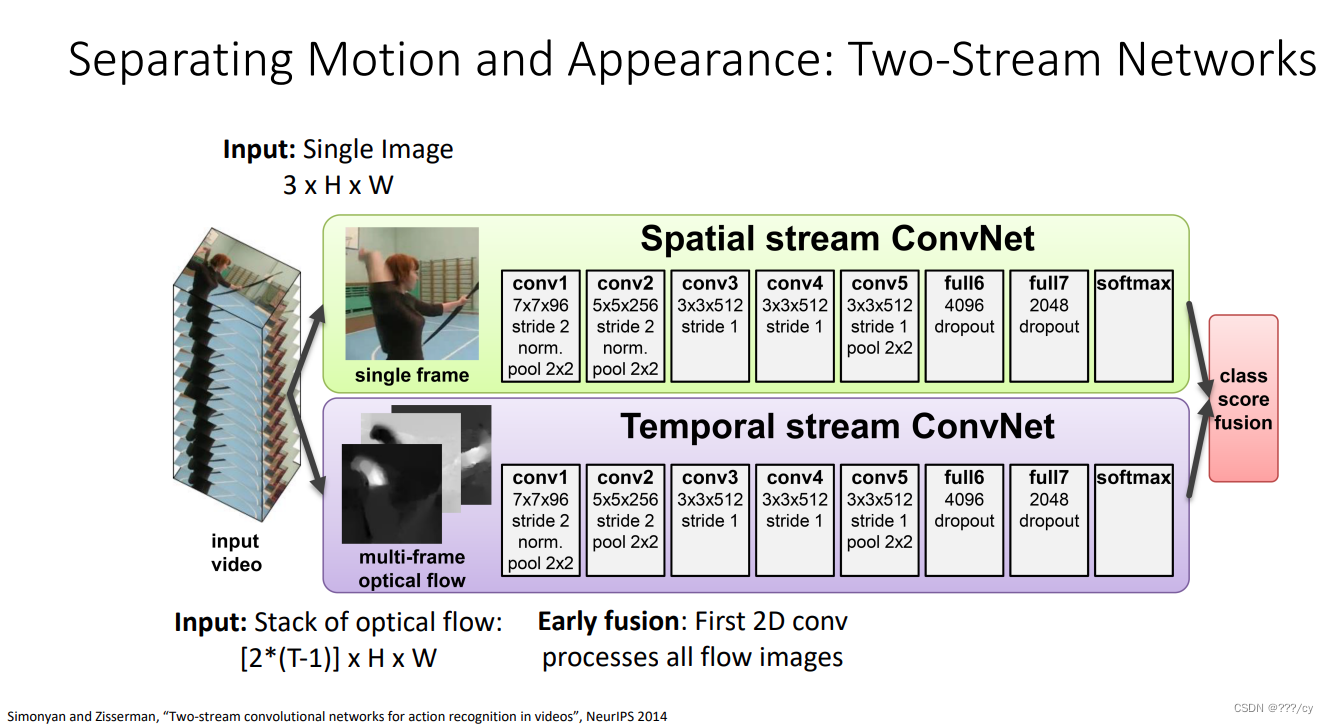

目前介绍的都是只能处理2s~5s的视频的模型。
如果想处理长视频怎么办?
我们之前学过RNN,但是RNN应用在长序列里面会非常的慢,不能并行(parallelized)。Self-Attention是可以并行计算的
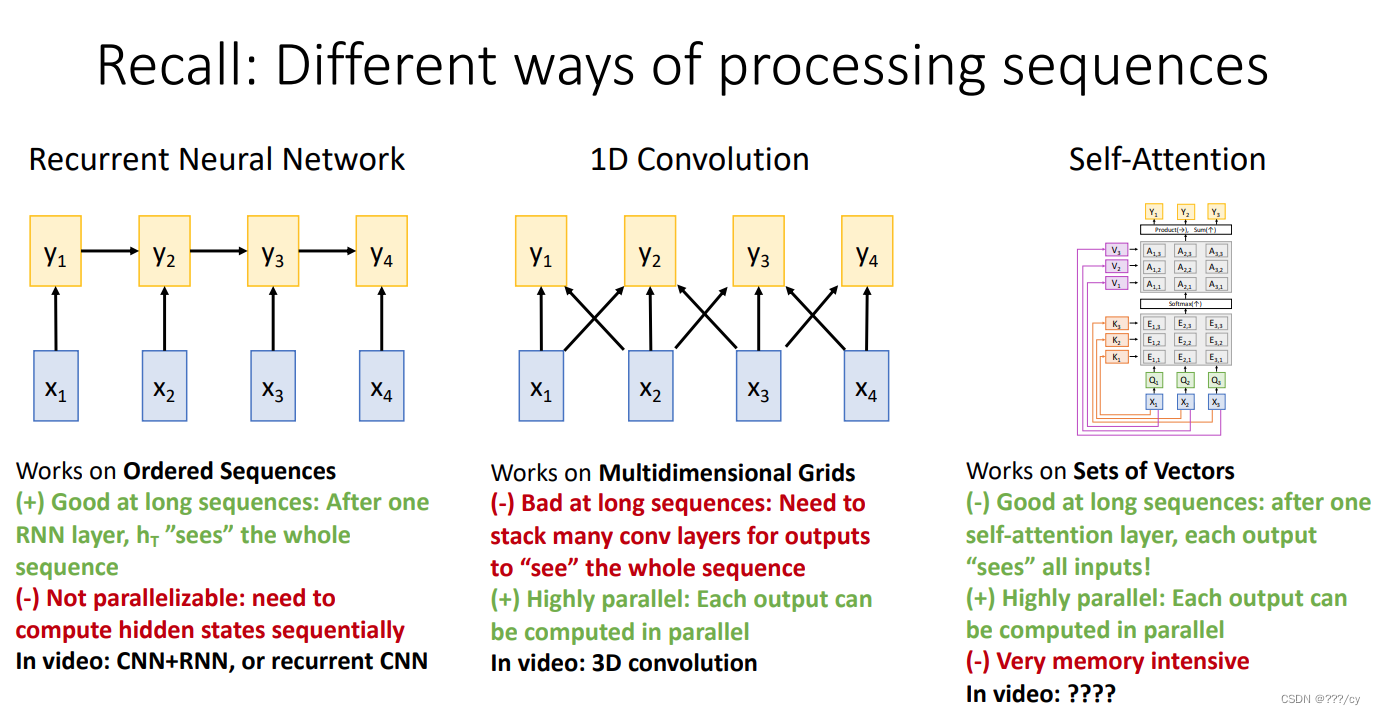
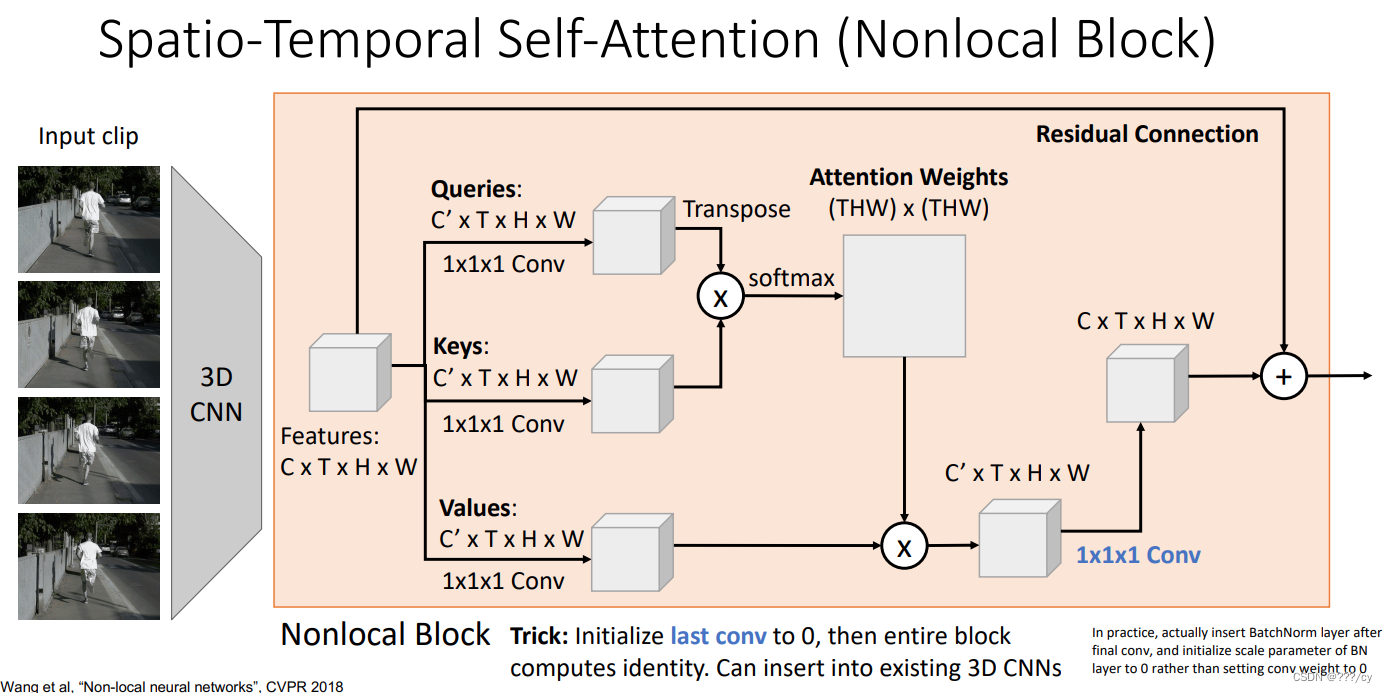

接下来介绍新技术
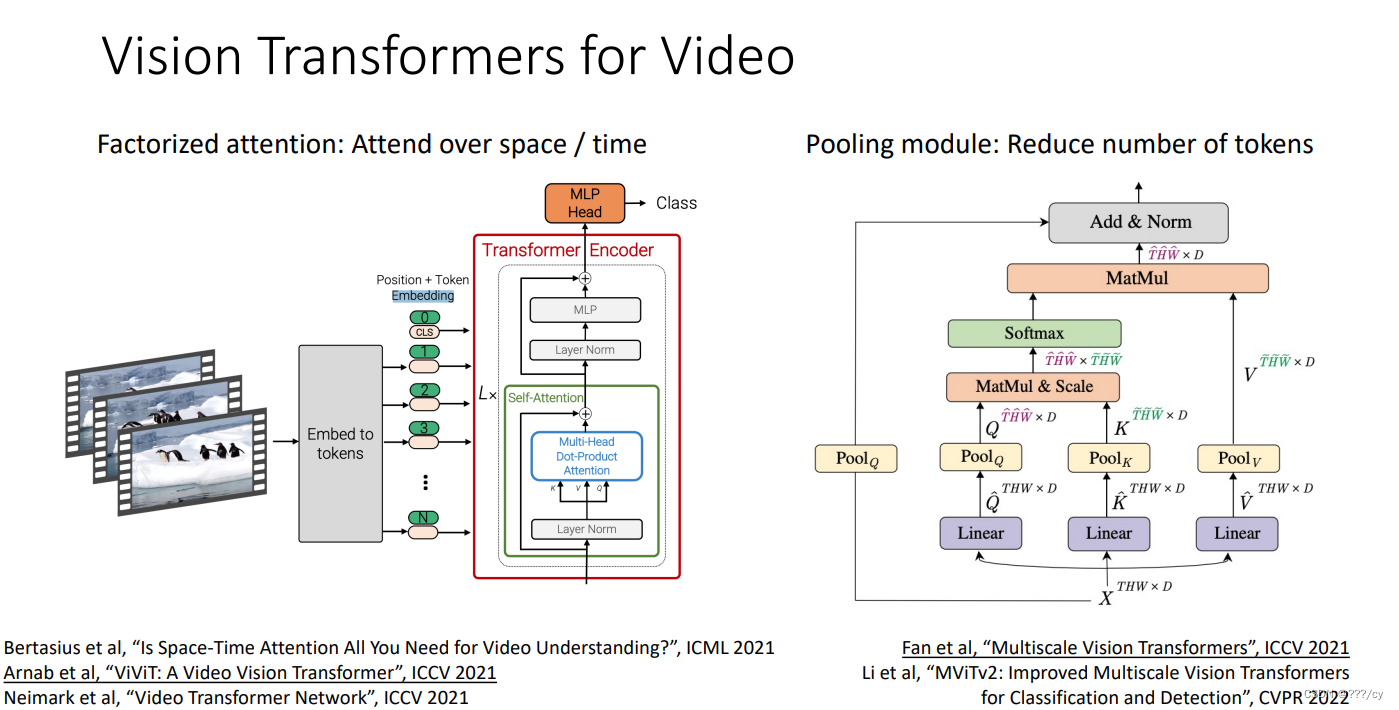
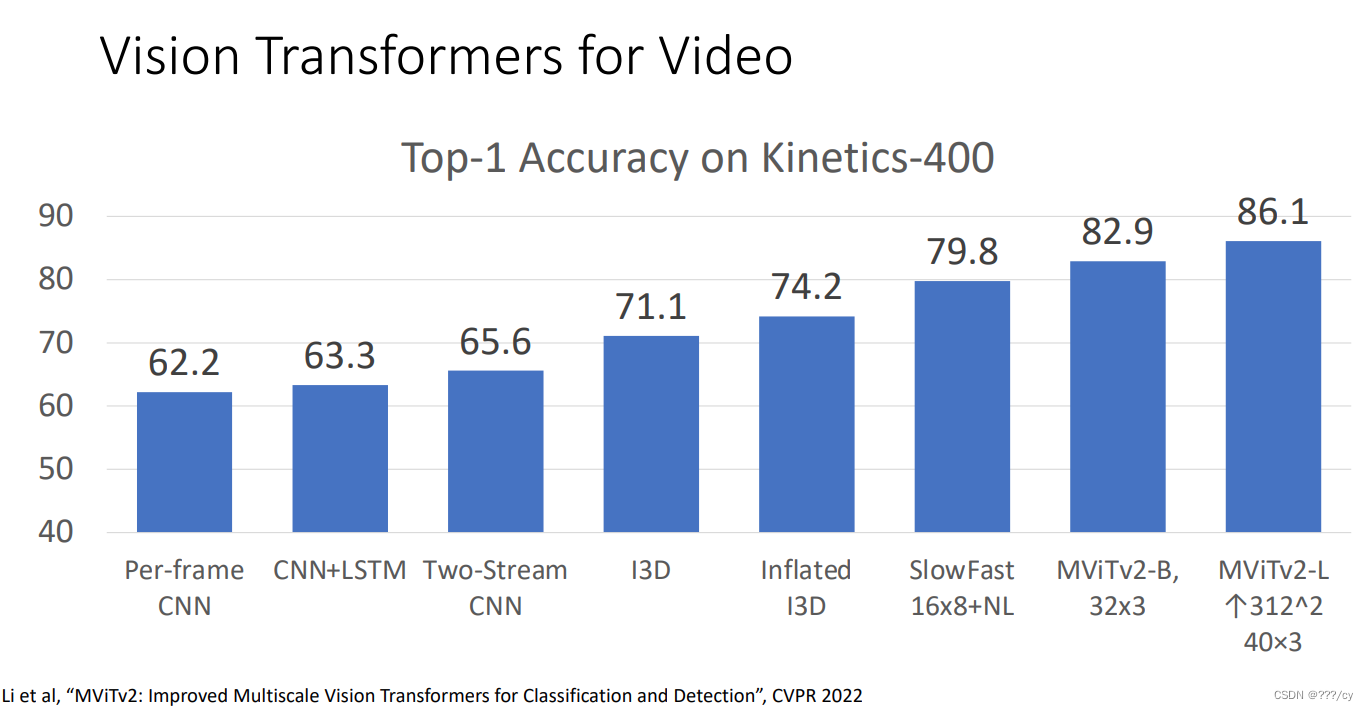
回顾一下:非常多的video工作


















 1127
1127

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









