




目录
属性
核心属性
- int corePoolSize:核心线程数量
- int maximumPoolSzie:最大线程数量
- long keepAliveTime:非核心线程的最大空闲等待时间
- boolean allowCoreThreadTimeOut:核心线程也使用最大空闲等待时间;默认 false
- BlockingQueue<Runnable> workQueue:任务队列
- ThreadFactory threadFactory:线程工厂;所有线程都使用此工厂创建
- RejectedExecutionHandler handler:拒绝策略;线程数达到上限,任务队列已满,对新提交的任务采取的策略
阻塞队列
有界:
- ArrayBlockingQueue:由数组组成的有界阻塞队列;按插入顺序排序;默认不公平访问。
- LinkedBlockingQueue:由链表组成的有界阻塞队列;按插入顺序排序。
- SynchronousQueue:不存储元素的阻塞队列;每个插入操作,必须等到另一个线程调用移除操作,否则一直阻塞。
无界:
- PriorityQueue:支持优先级排序的无界阻塞队列;不保证同优先级元素排序,可自行重写比较器。
- DelayQueue:使用优先级队列实现的无界阻塞队列,可实现任务定时执行;缓存系统设计(保存缓存有效期)
- LinkedTransferQueue:由链表组成的无界阻塞队列。
- LinkedBlockingDeque:由链表组成的无界双向阻塞队列。
饱和策略
- AbortPolicy:直接抛出异常。
- CallerRunsPolicy:直接用调用者线程执行任务。
- DiscardOldestPolicy:丢弃队列中最早元素,并尝试插入,失败则不断重试。
- DiscardPolicy:不处理,直接丢弃。
状态属性
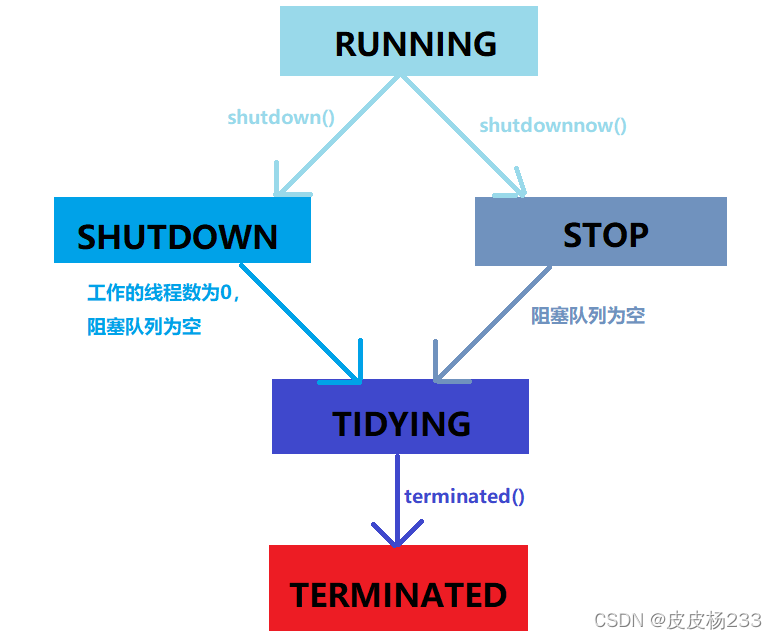
状态分类
- RUNNING:能接受新的任务,并且能处理阻塞队列中的任务。
- SHUTDOWN:不再接受新的任务,但是能处理阻塞队列中的任务。
- STOP:不再接受新的任务,也不再处理阻塞队列中的任务。
- TIDYING:所有任务都已终止。
- TERMINATED:默认是什么都不做,只是一个标识。
状态转换
新增任务
处理流程
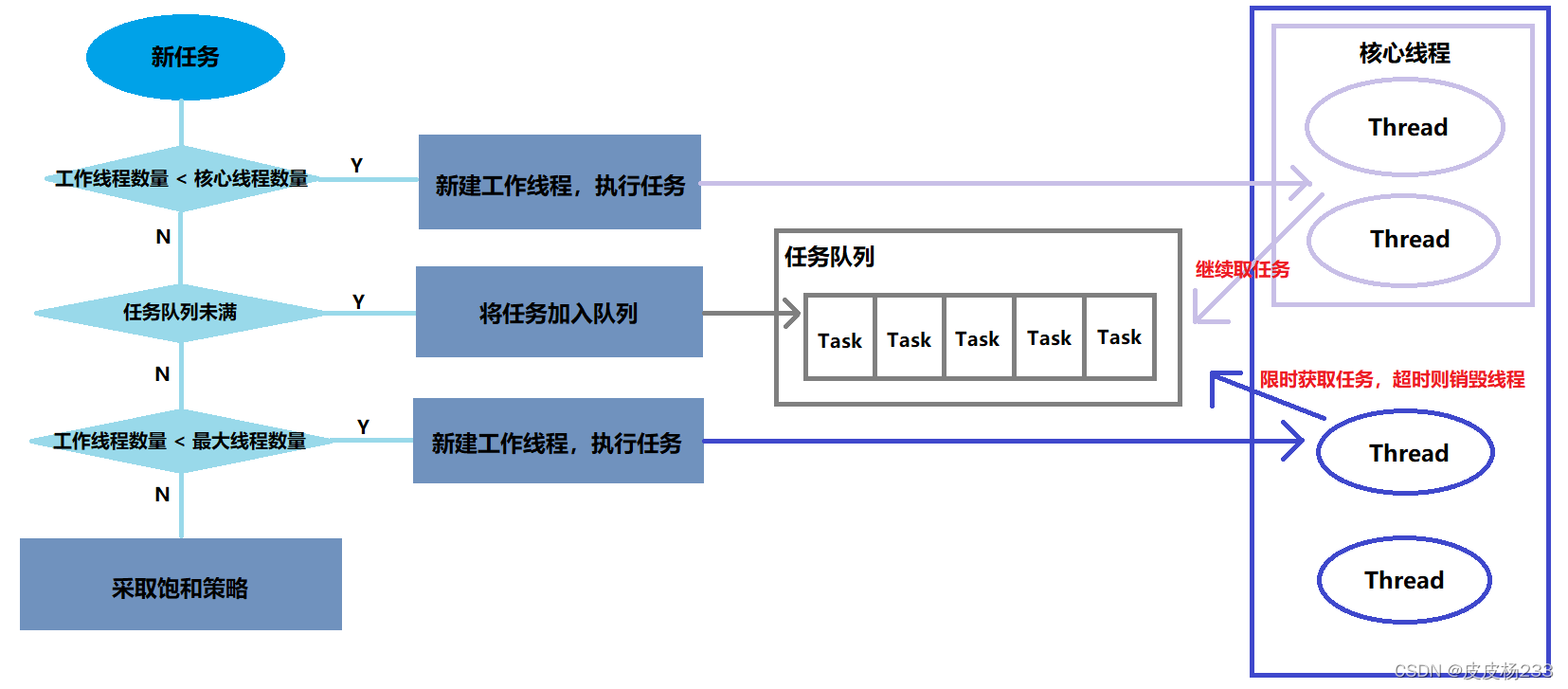
对于核心线程
- 并没有真正意义上的核心线程,只是一个数量的概念。
- 对外而言存在核心线程,底层其实没有实现,所有线程都是同等的。
- 当前线程获取任务时,工作线程数量 <= 核心线程数量,则它就是核心线程;否则它不是核心线程。
// 线程获取任务 private Runnable getTask() { // 当前线程上次获取任务是否超时 boolean timedOut = false; for (;;) { int c = ctl.get(); int rs = runStateOf(c); // 线程池已不再接受新任务,并且不再处理队列中任务或者队列为空 if (rs >= SHUTDOWN && (rs >= STOP || workQueue.isEmpty())) { // 当前线程可以销毁 decrementWorkerCount(); return null; } // 获取当前工作线程数量 int wc = workerCountOf(c); // 核心线程允许超时销毁 || 当前线程数 > 核心线程数 boolean timed = allowCoreThreadTimeOut || wc > corePoolSize; // 当前线程是否满足销毁条件:1.工作线程数量 2.核心线程是否可销毁 // ⭐⭐⭐没有对线程进行特殊判断(是否为核心线程) // ⭐⭐⭐对外而言存在核心线程,底层其实所有线程都同等。 if ((wc > maximumPoolSize || (timed && timedOut)) && (wc > 1 || workQueue.isEmpty())) { if (compareAndDecrementWorkerCount(c)) return null; continue; } // 从阻塞队列获取新任务 try { // 是否需要超时获取 Runnable r = timed ? workQueue.poll(keepAliveTime, TimeUnit.NANOSECONDS) : workQueue.take(); if (r != null) return r; timedOut = true; } catch (InterruptedException retry) { timedOut = false; } } }
进阶
合理配置线程池
任务的性质
- CPU 密集型任务:需要消耗大量 CPU 资源的任务,解压、解密、计算;大部分线程都需要使用 CPU 资源,线程设置过多,会频繁出现上下文切换,影响性能;CPU + 1。
- IO 密集型任务: MySQL、文件读写、网络传输;线程等待 IO 时,不需要 CPU 计算,可以让出 CPU,假如线程设置过少,CPU 资源不能得到充分利用;CPU * 2。
- 混合型任务:假如两任务执行时间相差不大,将任务拆分成 CPU 密集型、IO 密集型,吞吐量高于直接串行;假如执行时间相差太大,则直接串行。
线程数 = CPU 核心数 * (1 + IO 耗时 / CPU 耗时)
任务的优先级
使用优先级队列处理。
任务的执行时间
- 可使用优先队列。
- 平均工作时间(使用 CPU)占比越高,线程数则越少。
- 平均等待时间(IO 等)占比越高,线程数则越多,充分利用 CPU 资源。
任务的依赖性
是否依赖其他系统资源,如数据库连接;提交 SQL 后需要等待,此时不需要 CPU 计算,应该设置大线程数,充分利用 CPU 资源。
建议使用有界队列
有界队列能增加系统的稳定性和预警能力,可以根据需求设大一些,但是不建议使用无界。
无界队列,可能导致内存被撑满,使得整个系统不可用。
线程池分类
FixThreadPool
public static ExecutorService newFixedThreadPool(int nThreads) { return new ThreadPoolExecutor(nThreads, nThreads, 0L, TimeUnit.MILLISECONDS, new LinkedBlockingQueue<Runnable>()); } // 无界 public LinkedBlockingQueue() { this(Integer.MAX_VALUE); }队列无界:核心线程饱和后,任务添加至队列等待。
- “最大线程数”与“非核心线程最大空闲时间” 无效。
- 任务永远不会被拒绝。
- 多个任务并行执行。
应用场景:只有核心线程,并且都不会销毁,将一直占用资源;适合数量固定且耗时较长的任务,让线程保持忙碌状态。
SingleThreadExecutor
public static ExecutorService newSingleThreadExecutor() { return new FinalizableDelegatedExecutorService (new ThreadPoolExecutor(1, 1, 0L, TimeUnit.MILLISECONDS, new LinkedBlockingQueue<Runnable>())); } // 无界 public LinkedBlockingQueue() { this(Integer.MAX_VALUE); }队列无界:唯一核心线程创建后,任务添加至队列等待。
- “最大线程数”与“非核心线程最大空闲时间” 无效。
- 任务永远不会被拒绝。
- 单个线程,所有任务串行执行。
应用场景:多任务顺序执行。
CachedThreadPool
public static ExecutorService newCachedThreadPool() { return new ThreadPoolExecutor(0, Integer.MAX_VALUE, 60L, TimeUnit.SECONDS, new SynchronousQueue<Runnable>()); } // 空队列 public SynchronousQueue() { this(false); }空队列:添加新任务,需要其他空闲线程取走,否则创建非核心线程,60s 最大空闲时间。
- 任务提交速度 > 线程处理任务速度,会不断创建新线程;可能耗尽内存和 CPU 资源。
应用场景:全是非核心线程,60s 自动销毁,不会占用系统资源;适合任务量大但耗时短的任务。
ScheduledThreadPool
public static ExecutorService newWorkStealingPool(int parallelism) { return new ForkJoinPool (parallelism, ForkJoinPool.defaultForkJoinWorkerThreadFactory, null, true); } public ScheduledThreadPoolExecutor(int corePoolSize) { super(corePoolSize, Integer.MAX_VALUE, 0, NANOSECONDS, new DelayedWorkQueue()); } // 实现任务周期性执行 scheduleAtFixedRate scheduleWithFixedDelay队列无界:核心线程饱和后,任务添加至队列等待。
- 任务执行完,修改下次执行时间,重新放入队尾。
应用场景:定时任务,具体固定周期的重复任务。
WorkStealingPool
// 1.8 加入,为 Fork/Join 的扩展 // parallelism 表示并行度 public static ExecutorService newWorkStealingPool(int parallelism) { return new ForkJoinPool (parallelism, ForkJoinPool.defaultForkJoinWorkerThreadFactory, null, true); }Fork/Join:将“大任务“拆分成多个“小任务”,并分发到多个线程;所有任务执行完,再进行合并。
- 工作窃取算法:每个线程都对应一个任务队列,互不干扰;线程获取自己队列中任务为 FIFO;任务都完成后,会去其他线程任务队列中获取任务,为了减少冲突,从队尾取 LIFO。
- 将任务拆分,并行执行,提高效率;但是会消耗更多的系统资源。
- 不指定 parallelism 则默认为 CPU 核数。
应用场景:适合很耗时的任务。

















 1089
1089

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









