







论文:https://arxiv.org/pdf/2010.04159.pdf
源码:https://github.com/fundamentalvision/Deformable-DETR
摘要:
问题:DETR 缺陷:收敛速度慢;小物体检测性能低
解决方案:可变形注意力模块:仅关注参考点周围的一小部分关键采样点;支持多尺度融合,无需依赖FPN等金字塔网络
引言
DETR 缺陷:收敛速度慢;小目标检测性能低
原因:Transformer注意力模块的局限性:初始化时注意力模块对所有像素的权重一致;decoder中注意力权重的计算是关于像素个数的平方计算。
可变形DETR:结合了可变形卷积的系数空间采样和Transformer的关系建模能力。
提出了多尺度可变形注意力模块,该模块仅关注参考点周围少量采样位置,复杂度线性增长;支持多尺度特征聚合,无需依赖FPN等金字塔网络。
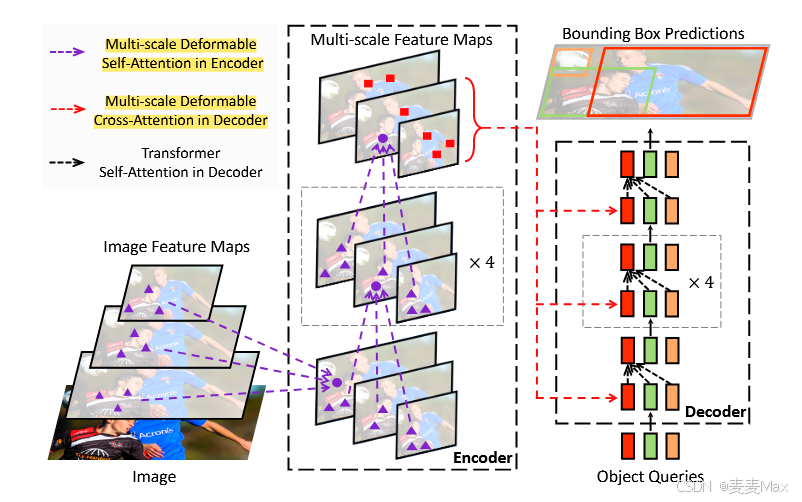
注意:这张图里的encoder是多尺度可变形自注意力模块,decoder是多尺度可变形交叉注意力模块
首先是从骨干网络提取多尺度特征图(Image部分),然后到encoder使用多尺度变形自注意力进一步提取特征,再到decoder使用多尺度可变形交叉注意力模块进行目标查询分类。
目标检测的主要困难之一是有效地表示不同尺度的目标。之前大多数网络引用的是FPN。但是,我们提出的多尺度可变形注意力模块可以通过注意力机制自然地聚合多尺度特征图,而不需要这些特征金字塔网络的帮助。
相关工作
Transformer的一个主要问题是当键元素数量很大时,时间和内存复杂度很高,这在许多情况下限制了模型的可扩展性。
解决方案:
-
第一类:使用预定义的稀疏注意力模式,如局部窗口或固定间隔的键元素,但会丢失全局信息。
-
第二类:学习数据依赖的稀疏注意力,如基于局部敏感哈希(LSH)的注意力机制。
-
第三类:探索自注意力中的低秩特性,通过线性投影或核化近似来降低复杂度。
多尺度特征表示:
目标检测的主要困难之一是有效地表示不同尺度下的目标。
解决方案:
-
FPN:通过自上而下的路径结合多尺度特征。
-
PANet:在FPN的基础上增加自下而上的路径。
-
其他方法:通过全局注意力操作、U形模块或神经架构搜索自动设计跨尺度连接。
提出多尺度可变形注意力模块可以通过注意力机制自然地聚合多尺度特征图,而不需要这些特征金字塔网络的帮助
重新审视 Transformer 与 DETR
1、多头注意力机制
给定一个查询元素(例如输出句子中的目标词)和一组键元素(例如输入句子中的源词),多头注意力模块根据查询-键对的兼容性自适应地聚合键内容。

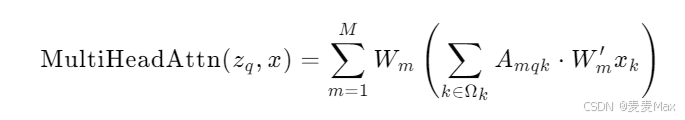
Transformer的两个问题:训练时间长;计算和内存复杂度高

2、DETR
基于 Transformer 编码器-解码器架构,结合了基于二分图匹配的匈牙利损失,以确保每个真实边界框的唯一预测。
DETR 通过结合 CNN 和 Transformer 编码器-解码器架构,消除了许多手工设计的组件需求,但仍然存在检测小物体性能较低和训练收敛慢的问题。这些问题主要归因于 Transformer 注意力在处理图像特征图作为键元素时的缺陷。
Method
4.1、端到端目标检测的可变形Transformer
受启发于可变形卷积,只关注参考点周围的少量关键采样点,不考虑特征图的空间大小。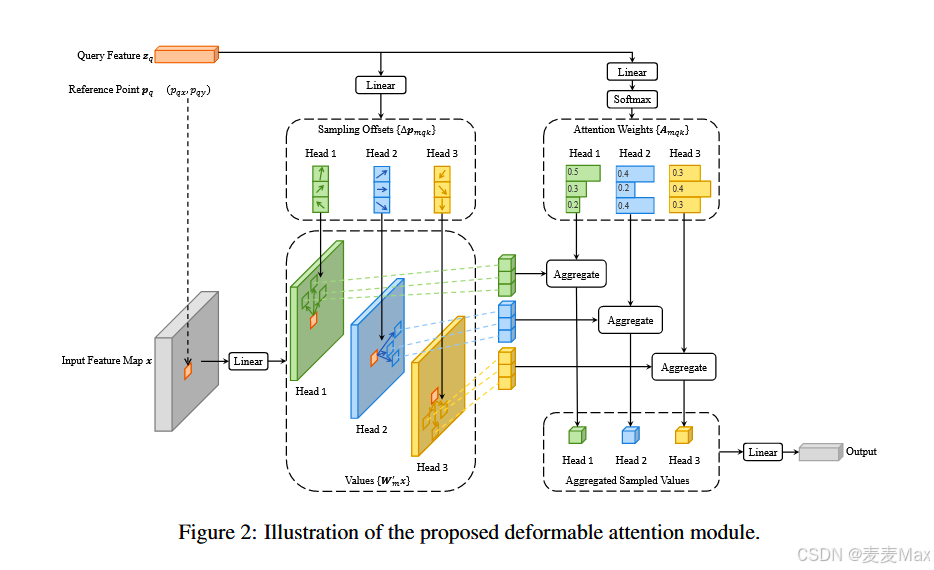
1、Input Feature Map x:
输入特征图,从卷积提取的多尺度特征图,x∈RC*H*W,C通道数,H、W是特征图的高和宽。经过一个线性投影到多头注意力层。
2、Query Feature zq:查询特征
这是来自解码器的对象查询特征,用于从特征图中提取相关信息。
参考点(Reference Point)这是二维坐标,用于确定在特征图中的采样位置
3、Sampling Offsets ΔPmqk 采样偏移
通过查询特征zp的线性投影生成采样偏移ΔPmqk,这些偏移量用于确定在特征图中的具体采样位置。采样偏移在多头注意力中生成。
4、多头注意力
输入的特征图x经过独立的线性层投影到不同的子空间,生成各头对应的值Wm,x(特征内容)
5、注意力权重
每个注意力头通过查询特征zq生成一组Amqk,这些权重用于加权采样值,以突出重要特征。
每个采样点Pq+ΔPmqk从输入特征图x提取一个特征Wm,x(Pq+ΔPmqk),Wm是可学习的权重矩阵。然后注意力权重Amqk表示查询特征zq对采样点Pq+ΔPmqk的关注程度。Aggregate聚合就表示为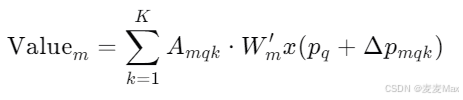
可变形注意力特征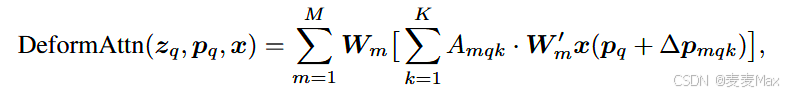
上式x为特征图,维度CxHxW,q为查询元素,zq 为其内容特征,pq 为2D参考点。m为注意力头,k为索引采样键,K为总采样键数。
ΔPmqk 和Amqk分别表示第m各注意力头中第k个采样点的采样偏移和注意力权重。Amqk 是一个标量,范围在0~1之间然后归一化为ΣKk=1Amqk=1;ΔPmqk为2D实数。
W,m和Wm是可学习的权重矩阵。Wm用于对每个注意力头的输出进行线性变换;W,m用于对输入特征图 x 进行线性变换。
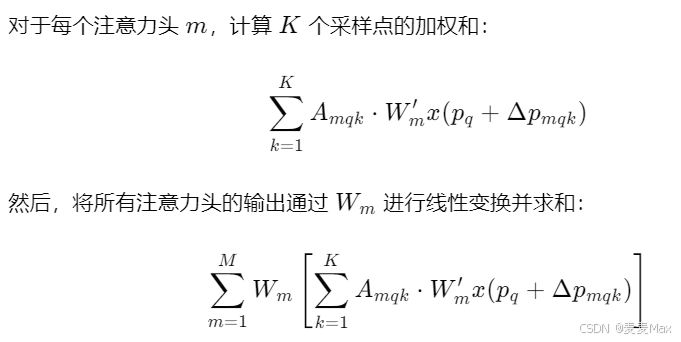
多尺度可变注意力模块。
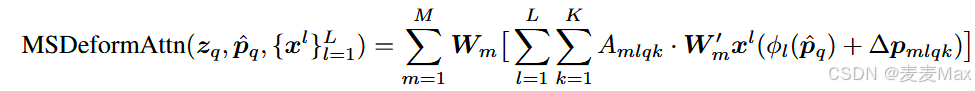

可变形Transformer编码器
提出的多尺度可变形注意力模块替换了 DETR 中处理特征图的 Transformer 注意力模块。
没有使用FPN的自上而下的结构,因为多尺度可变形注意力本身可以在多尺度特征图之间交换信息。
可变形Transformer解码器
解码器中有交叉注意力和自注意力模块。这两种注意力模块的查询元素都是对象查询。在交叉注意力模块中,对象查询从特征图中提取特征,其中键元素是编码器输出的特征图。在自注意力模块中,对象查询相互交互,其中键元素是对象查询。
由于多尺度可变形注意力模块在参考点周围提取图像特征,我们让检测头预测相对于参考点的边界框,以进一步降低优化难度。
4.2 可变形 DETR 的额外改进和变体
两阶段可变形DETR
探索了可变形 DETR 的一个变体,用于生成区域提议作为第一阶段。生成的区域提议将作为对象查询输入到解码器中进行进一步细化,形成两阶段可变形 DETR。
在第一阶段,为了实现高召回率的提议,多尺度特征图中的每个像素都作为对象查询。移除了解码器,形成了一个用于区域提议生成的仅编码器的可变形 DETR。每个像素都被分配为一个对象查询,直接预测一个边界框。选择得分最高的边界框作为区域提议。
参考:

















 1972
1972

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









