







前言:
基于mmdet,对deformable-detr这篇论文的源码简要分析,对论文原理的一些理解在:deformable-detr论文解析-优快云博客
源码解析:
整体模型结构如下图: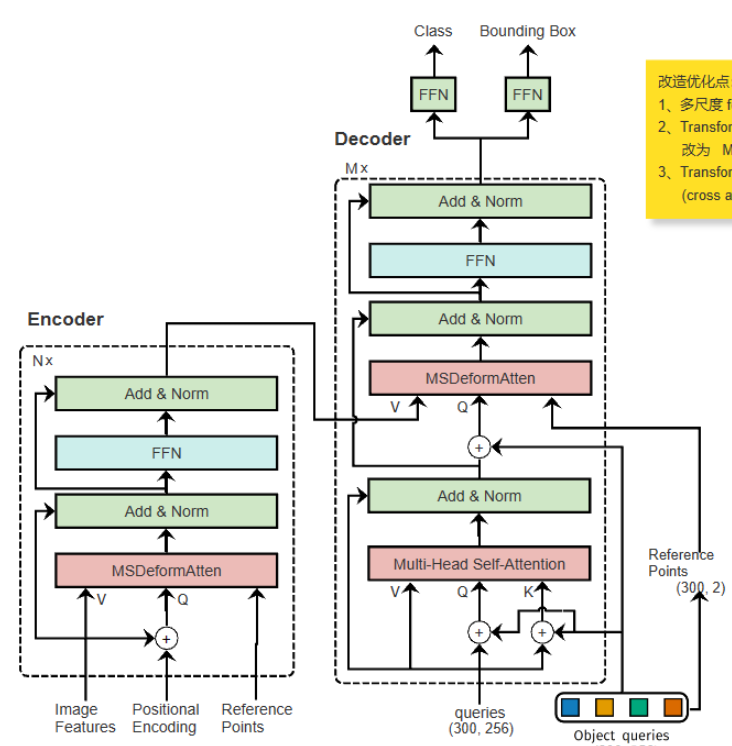
准备Encoder编码层的全部输入:
多尺度特征输入:
在Deformable DETR在backbone(ResNet50)部分会提取4层不同尺度的特征。如下图,前三层分别来自ResNet50的Layer2-4,下采样率分别为8、16、32,再分别接一个1x1卷+GroupNorm,将特征统一降维到256。第三层来自Layer4,经过一个3x3卷积 + GroupNorm,得到下采样率为64、将维到256的特征。
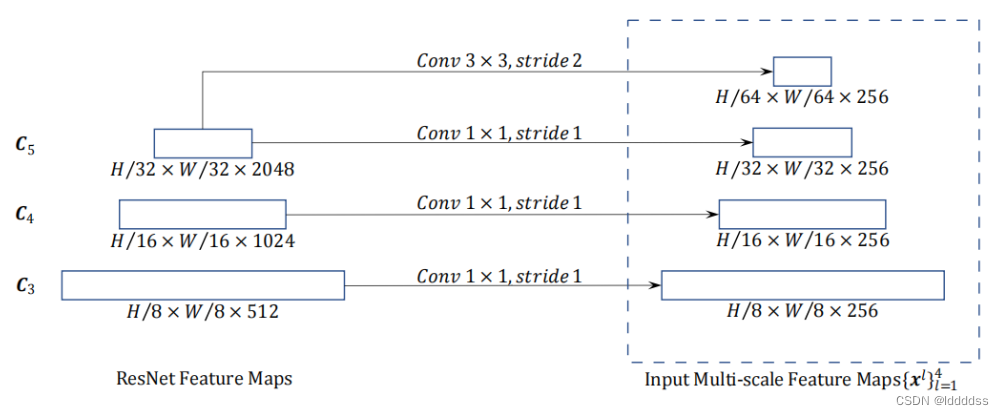
backbone(ResNet50):
通过ResNet得到三个不同层级的特征list
def forward(self, x):
"""Forward function."""
if self.deep_stem: # torch.Size([1, 3, 480, 546])
x = self.stem(x)
else:
x = self.conv1(x)
x = self.norm1(x)
x = self.relu(x)
x = self.maxpool(x)
outs = []
for i, layer_name in enumerate(self.res_layers):
res_layer = getattr(self, layer_name)
x = res_layer(x) # # 原图片mask下采样8、16、32倍
if i in self.out_indices: # 通过out_indices索引决定哪几个stage 1 2 3
outs.append(x)
# 3个不同尺度的输出特征 list
# 0 torch.Size([1, 512, 60, 69])
# 1 torch.Size([1, 1024, 30, 35])
# 2 torch.Size([1, 2048, 15, 18])
return tuple(outs)
neck层:
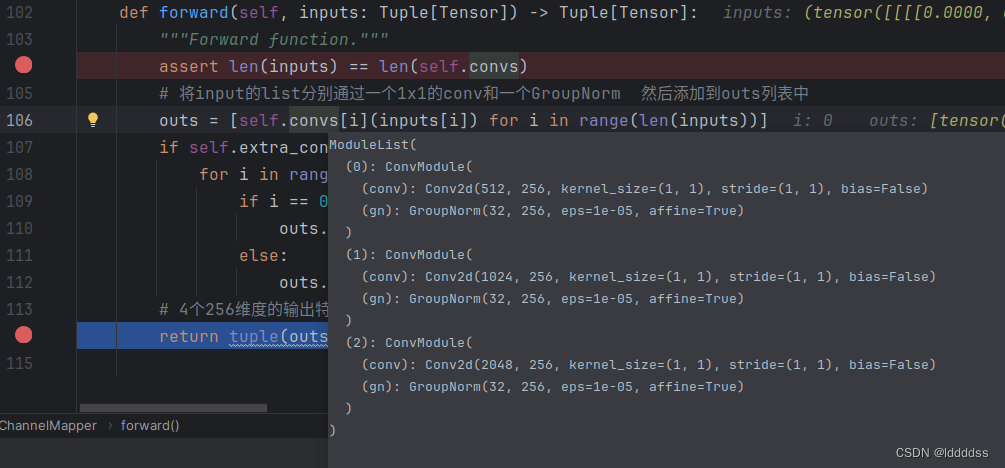
添加第四个特征层,同时将四个特征图统一调整到256维。
def forward(self, inputs: Tuple[Tensor]) -> Tuple[Tensor]:
"""Forward function."""
assert len(inputs) == len(self.convs)
# 将input的list分别通过一个1x1的conv和一个GroupNorm 然后添加到outs列表中
outs = [self.convs[i](inputs[i]) for i in range(len(inputs))]
if self.extra_convs:
for i in range(len(self.extra_convs)): # len:1
if i == 0: # 在input的最后一层添加一个3x3的conv和一个GroupNorm 添加到outs列表中
outs.append(self.extra_convs[0](inputs[-1]))
else:
outs.append(self.extra_convs[i](outs[-1]))
# 4个256维度的输出特征 list
return tuple(outs) 将input的list分别通过一个1x1的conv和一个GroupNorm 然后添加到outs列表中,将三个特征图的输出维度统一调整到256
将最后一层通过一个3x3的conv和一个gn,同时将其输出维度调整到256,得到第四个输出
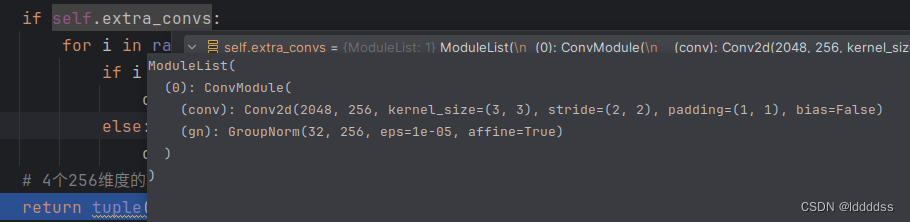
最终输出outs: 注意:neck层没有做特征融合,只是将特征图的维度统一到256并在三个层级之下再加一层
注意:neck层没有做特征融合,只是将特征图的维度统一到256并在三个层级之下再加一层
pre_transformer:
根据注释可以得到,head层的传播路径为:

在mmdet/models/detectors/deformable_detr.py下的pre_transformer下打上断点:
def pre_transformer(
self,
mlvl_feats: Tuple[Tensor],
batch_data_samples: OptSampleList = None) -> Tuple[Dict]:
"""Process image features before feeding them to the transformer.
The forward procedure of the transformer is defined as:
'pre_transformer' -> 'encoder' -> 'pre_decoder' -> 'decoder'
More details can be found at `TransformerDetector.forward_transformer`
in `mmdet/detector/base_detr.py`.
Args:
mlvl_feats (tuple[Tensor]): Multi-level features that may have
different resolutions, output from neck. Each feature has
shape (bs, dim, h_lvl, w_lvl), where 'lvl' means 'layer'.
batch_data_samples (list[:obj:`DetDataSample`], optional): The
batch data samples. It usually includes information such
as `gt_instance` or `gt_panoptic_seg` or `gt_sem_seg`.
Defaults to None.
Returns:
tuple[dict]: The first dict contains the inputs of encoder and the
second dict contains the inputs of decoder.
- encoder_inputs_dict (dict): The keyword args dictionary of
`self.forward_encoder()`, which includes 'feat', 'feat_mask',
and 'feat_pos'.
- decoder_inputs_dict (dict): The keyword args dictionary of
`self.forward_decoder()`, which includes 'memory_mask'.
"""
batch_size = mlvl_feats[0].size(0) # 获取batch_size 1
# construct binary masks for the transformer.
assert batch_data_samples is not None
batch_input_shape = batch_data_samples[0].batch_input_shape # 获取batch_input_shape tuple(480,538)
input_img_h, input_img_w = batch_input_shape # 得到输入图像的h与w
img_shape_list = [sample.img_shape for sample in batch_data_samples] # 提取一个batch的img_shape,存入list列表中[(480,538)]
same_shape_flag = all([
s[0] == input_img_h and s[1] == input_img_w for s in img_shape_list
]) # 检查输入图像的形状是否一致(是否被padding) True
# support torch2onnx without feeding masks
# 得到每个特征对应的位置编码,通过遍历得到每个层级对应的level+sin/cos position embeds
# if判断主要是要求得到的位置编码都是图片真实有效的位置,而不是被padding填充的无效位置
if torch.onnx.is_in_onnx_export() or same_shape_flag:
mlvl_masks = [] # 储存每个特征对应的mask
mlvl_pos_embeds = [] # 储存每个特征对应的位置编码
for feat in mlvl_feats: # 遍历得到每一个层级的位置编码
mlvl_masks.append(None)
mlvl_pos_embeds.append(
self.positional_encoding(None, input=feat)) # 传入特征图feat,使用sin cos建立位置编码
else:
# 目的是当输入图像shape与img_shape不一致时,即经过padding
masks = mlvl_feats[0].new_ones(
(batch_size, input_img_h, input_img_w)) # 创建一个与batch_input_shape一致的全为1masks模板
for img_id in range(batch_size):
img_h, img_w = img_shape_list[img_id]
masks[img_id, :img_h, :img_w] = 0 # 将img_shape大小范围的masks设置为0(有效区域)
# NOTE following the official DETR repo, non-zero
# values representing ignored positions, while
# zero values means valid positions.
mlvl_masks = []
mlvl_pos_embeds = []
for feat in mlvl_feats:
mlvl_masks.append(
F.interpolate(masks[None], size=feat.shape[-2:]).to(
torch.bool).squeeze(0)) # 通过将mask张量插值到每个特征层上(使用F.interpolate()函数),获取每个特征层对应的、与之匹配的mask
mlvl_pos_embeds.append(
self.positional_encoding(mlvl_masks[-1]))
feat_flatten = []
lvl_pos_embed_flatten = []
mask_flatten = []
spatial_shapes = []
for lvl, (feat, mask, pos_embed) in enumerate(
zip(mlvl_feats, mlvl_masks, mlvl_pos_embeds)): # 遍历每一层的特征、mask、pos_embeds
batch_size, c, h, w = feat.shape
spatial_shape = torch._shape_as_tensor(feat)[2:].to(feat.device) # 获取特征图的形状张量
# [bs, c, h_lvl, w_lvl] -> [bs, h_lvl*w_lvl, c]
feat = feat.view(batch_size, c, -1).permute(0, 2, 1)
pos_embed = pos_embed.view(batch_size, c, -1).permute(0, 2, 1)
lvl_pos_embed = pos_embed + self.level_embed[lvl].view(1, 1, -1) # 执行位置编码加上级别嵌入向量
# [bs, h_lvl, w_lvl] -> [bs, h_lvl*w_lvl]
if mask is not None:
mask = mask.flatten(1)
feat_flatten.append(feat) # 四个特征图拼接在一起
lvl_pos_embed_flatten.append(lvl_pos_embed) # 四个层位置编码拼接在一起
mask_flatten.append(mask)
spatial_shapes.append(spatial_shape) # 四个特征图尺寸list
# (bs, num_feat_points, dim)
feat_flatten = torch.cat(feat_flatten, 1) # 将整个batch特征拼接在一起
lvl_pos_embed_flatten = torch.cat(lvl_pos_embed_flatten, 1) # pos_embd拼接在一起
# (bs, num_feat_points), where num_feat_points = sum_lvl(h_lvl*w_lvl)
if mask_flatten[0] is not None:
mask_flatten = torch.cat(mask_flatten, 1)
else:
mask_flatten = None
# (num_level, 2)
spatial_shapes = torch.cat(spatial_shapes).view(-1, 2)
level_start_index = torch.cat((
spatial_shapes.new_zeros((1, )), # (num_level)
spatial_shapes.prod(1).cumsum(0)[:-1])) # 计算每个特征图在拼接后的位置编码中的起始索引
if mlvl_masks[0] is not None: # valid_ratios:被padding的特征图与特征图之间的比值 由于batch为1 valid_ratios为1
valid_ratios = torch.stack( # (bs, num_level, 2)
[self.get_valid_ratio(m) for m in mlvl_masks], 1)
else:
valid_ratios = mlvl_feats[0].new_ones(batch_size, len(mlvl_feats),
2)
encoder_inputs_dict = dict(
feat=feat_flatten, # (1,5427,256) 四个特征展平拼接在一起
feat_mask=mask_flatten, # None,batch为1 因此不需要padding
feat_pos=lvl_pos_embed_flatten, # (1,5427,256) 四个不同的pos_embds展平拼接在一起
spatial_shapes=spatial_shapes, # (4,2) 四个层特征图的尺寸list
level_start_index=level_start_index, # 每个层级位置编码的起始索引
valid_ratios=valid_ratios) # 特征图有效位置与被padding的尺寸的比值
decoder_inputs_dict = dict(
memory_mask=mask_flatten,
spatial_shapes=spatial_shapes,
level_start_index=level_start_index,
valid_ratios=valid_ratios)
return encoder_inputs_dict, decoder_inputs_dictpre_transformer的主要目的是返回encoder_inputs_dict, decoder_inputs_dict两个dict,里面存储着包括:
feat:被展平拼接的特征
feat_pos:被展平拼接在一起的位置编码(给每层特征图的pos_embds都添加一个leves,并且每个level层级位置编码都是可学习的,确保不同特征图的位置编码都是独一无二的)
feat_mask:以一个batch将图片进行输入时,需要将不同尺寸图片统一尺寸,一般是将图片以左上角对齐,在图片右方与下方进行padding填充,但是被填充的位置并不需要进行训练,设置mask将图片有效位置与padding无效位置进行区分,只对有效位置进行训练,降低计算量
spatial_shapes:特阵图尺寸信息
level_start_index:每个层级位置编码的起始索引,由于将四个特征图都拉长拼接在一起保证计算的方便性,因此需要设置一个index确保能够区分拼接的特征分别属于哪一个特征图。
valid_ratios:输入特征图与被padding的特征图之间的长宽比
reference_points:
在mmdet/models/layers/transformer/deformable_detr_layers.py中DeformableDetrTransformerEncoder类forward与get_encoder_reference_points函数下打上断点
def get_encoder_reference_points(
spatial_shapes: Tensor, valid_ratios: Tensor,
device: Union[torch.device, str]) -> Tensor:
"""Get the reference points used in encoder.
Args:
spatial_shapes (Tensor): Spatial shapes of features in all levels,
has shape (num_levels, 2), last dimension represents (h, w).
valid_ratios (Tensor): The ratios of the valid width and the valid
height relative to the width and the height of features in all
levels, has shape (bs, num_levels, 2).
device (obj:`device` or str): The device acquired by the
`reference_points`.
Returns:
Tensor: Reference points used in decoder, has shape (bs, length,
num_levels, 2).
"""
reference_points_list = []
for lvl, (H, W) in enumerate(spatial_shapes): # 对四个层级取坐标
ref_y, ref_x = torch.meshgrid( # 生成绝对坐标
torch.linspace(
0.5, H - 0.5, H, dtype=torch.float32, device=device), # (75,26) 从0.5-(H-0.5)生成H个数,并使用linspace生成二维网格
torch.linspace(
0.5, W - 0.5, W, dtype=torch.float32, device=device), indexing = 'ij') # (75,26)
ref_y = ref_y.reshape(-1)[None] / ( # 归一化得到y相对坐标
valid_ratios[:, None, lvl, 1] * H)
ref_x = ref_x.reshape(-1)[None] / ( # 归一化得到x相对坐标
valid_ratios[:, None, lvl, 0] * W)
ref = torch.stack((ref_x, ref_y), -1) # 相对坐标
reference_points_list.append(ref) # 四个层级特征图的相对坐标 list:4
reference_points = torch.cat(reference_points_list, 1) # 四个层级坐标拼接在一起
# [bs, sum(hw), num_level, 2]
reference_points = reference_points[:, :, None] * valid_ratios[:, None] # bs=1时,相当于将reference_points复制4次 bs!= 1时,两者相乘表征采样点在真实特征图上的位置
return reference_points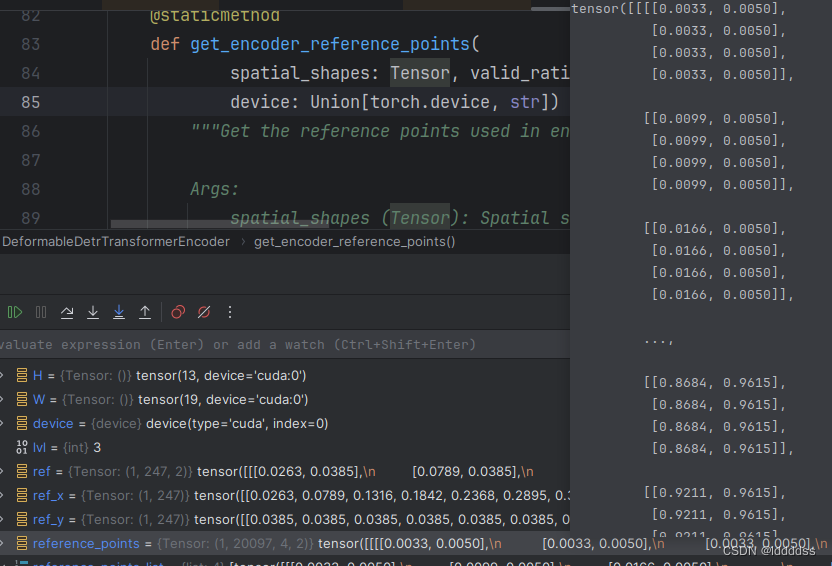
reference_points的作用是给四个特征图的位置提供相对位置坐标,可变型atten需要reference_points与offset,由于四个特征图大小不同,因此不能使用绝对位置坐标,使用归一化操作将绝对位置坐标转化为相对位置坐标,四个特征图的每个位置的相对坐标都是相同的
四个特征图展平拼接的序列的每一个位置的特征都需要提取四个特征图对应的位置的特征,但是不同特征图的大小不一样,而且很大可能序列坐标对应与四个特征图的相对坐标是小数,如何能够准确的找到四个特征图的同一个位置的特征?对特征图的上相对坐标周围的四个点作双线性插值得到每个点坐标。
Encoder:
reference_points = self.get_encoder_reference_points(
spatial_shapes, valid_ratios, device=query.device)
for layer in self.layers:
query = layer(
query=query, # 展平拼接的特征序列
query_pos=query_pos, # 位置编码(sin/cos位置编码+level)
key_padding_mask=key_padding_mask,
spatial_shapes=spatial_shapes,
level_start_index=level_start_index,
valid_ratios=valid_ratios,
reference_points=reference_points, # 相对坐标
**kwargs)
return query将最后得到的reference_points和其他参数传进layers中:
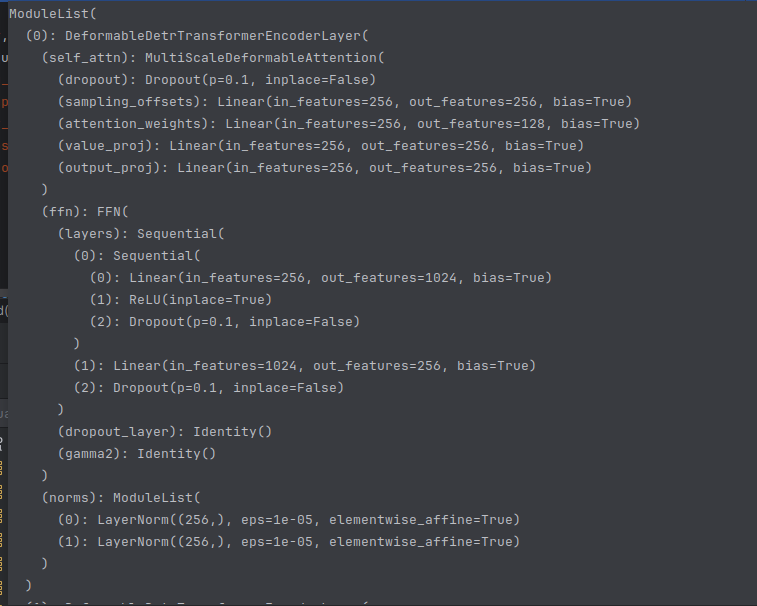
上图就是完整的一个encoderlayer流程,在该网络中,一共重复6个layer。
MSDeformAttn:
在MSDeformAttn中,主要通过四个linear层,生成offsets,attention_weights,value,output。
在multi_scale_deform_attn.py下MultiScaleDeformableAttention(BaseModule)类forward下打上断点:
def forward(self,
query: torch.Tensor,
key: Optional[torch.Tensor] = None,
value: Optional[torch.Tensor] = None,
identity: Optional[torch.Tensor] = None,
query_pos: Optional[torch.Tensor] = None,
key_padding_mask: Optional[torch.Tensor] = None,
reference_points: Optional[torch.Tensor] = None,
spatial_shapes: Optional[torch.Tensor] = None,
level_start_index: Optional[torch.Tensor] = None,
**kwargs) -> torch.Tensor:
"""Forward Function of MultiScaleDeformAttention.
Args:
query (torch.Tensor): Query of Transformer with shape
(num_query, bs, embed_dims).
key (torch.Tensor): The key tensor with shape
`(num_key, bs, embed_dims)`.
value (torch.Tensor): The value tensor with shape
`(num_key, bs, embed_dims)`.
identity (torch.Tensor): The tensor used for addition, with the
same shape as `query`. Default None. If None,
`query` will be used.
query_pos (torch.Tensor): The positional encoding for `query`.
Default: None.
key_padding_mask (torch.Tensor): ByteTensor for `query`, with
shape [bs, num_key].
reference_points (torch.Tensor): The normalized reference
points with shape (bs, num_query, num_levels, 2),
all elements is range in [0, 1], top-left (0,0),
bottom-right (1, 1), including padding area.
or (N, Length_{query}, num_levels, 4), add
additional two dimensions is (w, h) to
form reference boxes.
spatial_shapes (torch.Tensor): Spatial shape of features in
different levels. With shape (num_levels, 2),
last dimension represents (h, w).
level_start_index (torch.Tensor): The start index of each level.
A tensor has shape ``(num_levels, )`` and can be represented
as [0, h_0*w_0, h_0*w_0+h_1*w_1, ...].
Returns:
torch.Tensor: forwarded results with shape
[num_query, bs, embed_dims].
"""
if value is None:
value = query # 将q赋给v v = q = feat
if identity is None:
identity = query
if query_pos is not None:
query = query + query_pos # q = feat + pos
if not self.batch_first:
# change to (bs, num_query ,embed_dims)
query = query.permute(1, 0, 2)
value = value.permute(1, 0, 2)
bs, num_query, _ = query.shape
bs, num_value, _ = value.shape
assert (spatial_shapes[:, 0] * spatial_shapes[:, 1]).sum() == num_value
value = self.value_proj(value) # 将v通过一个linear
if key_padding_mask is not None:
value = value.masked_fill(key_padding_mask[..., None], 0.0) # 区分padding的位置
value = value.view(bs, num_value, self.num_heads, -1)
sampling_offsets = self.sampling_offsets(query).view(
bs, num_query, self.num_heads, self.num_levels, self.num_points, 2) # q通过一个linear得到offsets (bs,num_query,num_heam(8),num_level(4),num_points(4),2)
attention_weights = self.attention_weights(query).view(
bs, num_query, self.num_heads, self.num_levels * self.num_points) # q通过一个linear得到atten_weight (bs,num_query,num_heam(8),num_level(4)*num_points(4))
attention_weights = attention_weights.softmax(-1) # 转换为概率分布
attention_weights = attention_weights.view(bs, num_query,
self.num_heads,
self.num_levels,
self.num_points)
if reference_points.shape[-1] == 2:
offset_normalizer = torch.stack(
[spatial_shapes[..., 1], spatial_shapes[..., 0]], -1)
# [bs, Len_q, 1, n_point, 1, 2] + [bs, Len_q, n_head, n_level, n_point, 2] / [1, 1, 1, n_point, 1, 2]
# -> [bs, Len_q, 1, n_levels, n_points, 2]
# 参考点 + 偏移量/特征层宽高 = 采样点
sampling_locations = reference_points[:, :, None, :, None, :] \
+ sampling_offsets \
/ offset_normalizer[None, None, None, :, None, :] # /表示按元素相除
elif reference_points.shape[-1] == 4:
sampling_locations = reference_points[:, :, None, :, None, :2] \
+ sampling_offsets / self.num_points \
* reference_points[:, :, None, :, None, 2:] \
* 0.5
else:
raise ValueError(
f'Last dim of reference_points must be'
f' 2 or 4, but get {reference_points.shape[-1]} instead.')
# 调用CUDA实现的MSDeformAttnFunction函数 需要编译
if ((IS_CUDA_AVAILABLE and value.is_cuda)
or (IS_MLU_AVAILABLE and value.is_mlu)):
output = MultiScaleDeformableAttnFunction.apply(
value, spatial_shapes, level_start_index, sampling_locations,
attention_weights, self.im2col_step)
else:
output = multi_scale_deformable_attn_pytorch(
value, spatial_shapes, sampling_locations, attention_weights)
output = self.output_proj(output)
if not self.batch_first:
# (num_query, bs ,embed_dims)
output = output.permute(1, 0, 2)
return self.dropout(output) + identity这里的MSDeformAttn是调用的CUDA实现的,具体过程是:v=特征序列,连接两个全连接层预测offset与atten权重,将四个层级的offset作用到特征点然后乘以atten权重再相加得到最终输出(更新后的特征序列),在multi_scale_deform_attn.py的ms_deform_attn_core_pytorch函数有pytorch实现版本:
def multi_scale_deformable_attn_pytorch(
value: torch.Tensor, value_spatial_shapes: torch.Tensor,
sampling_locations: torch.Tensor,
bs, _, num_heads, embed_dims = value.shape
_, num_queries, num_heads, num_levels, num_points, _ =\
sampling_locations.shape
# 把value分割到各个特征层上得到对应的 list value
value_list = value.split([H_ * W_ for H_, W_ in value_spatial_shapes],
dim=1)
# 采样点坐标从[0,1] -> [-1, 1] F.grid_sample要求采样坐标归一化到[-1, 1]
sampling_grids = 2 * sampling_locations - 1
sampling_value_list = []
for level, (H_, W_) in enumerate(value_spatial_shapes):
# bs, H_*W_, num_heads, embed_dims ->
# bs, H_*W_, num_heads*embed_dims ->
# bs, num_heads*embed_dims, H_*W_ ->
# bs*num_heads, embed_dims, H_, W_
value_l_ = value_list[level].flatten(2).transpose(1, 2).reshape( # 得到每个特征层的value list
bs * num_heads, embed_dims, H_, W_)
# bs, num_queries, num_heads, num_points, 2 ->
# bs, num_heads, num_queries, num_points, 2 ->
# bs*num_heads, num_queries, num_points, 2
sampling_grid_l_ = sampling_grids[:, :, :, # 得到每个特征层的采样点 list
level].transpose(1, 2).flatten(0, 1)
# bs*num_heads, embed_dims, num_queries, num_points
# 采样算法 根据每个特征层采样点到每个特征层的value进行采样 非采样点用0填充
sampling_value_l_ = F.grid_sample(
value_l_,
sampling_grid_l_,
mode='bilinear',
padding_mode='zeros',
align_corners=False)
sampling_value_list.append(sampling_value_l_)
# (bs, num_queries, num_heads, num_levels, num_points) ->
# (bs, num_heads, num_queries, num_levels, num_points) ->
# (bs, num_heads, 1, num_queries, num_levels*num_points)
attention_weights = attention_weights.transpose(1, 2).reshape(
bs * num_heads, 1, num_queries, num_levels * num_points)
# 注意力权重 和 采样后的value 进行 weighted sum
output = (torch.stack(sampling_value_list, dim=-2).flatten(-2) *
attention_weights).sum(-1).view(bs, num_heads * embed_dims,
num_queries)
return output.transpose(1, 2).contiguous()Decoder:
pre_decoder:
def pre_decoder(self, memory: Tensor, memory_mask: Tensor,
spatial_shapes: Tensor) -> Tuple[Dict, Dict]:
batch_size, _, c = memory.shape
if self.as_two_stage:
"""
...
"""
else:
enc_outputs_class, enc_outputs_coord = None, None
# 初始化 (300,512) 预测300个框
query_embed = self.query_embedding.weight
query_pos, query = torch.split(query_embed, c, dim=1) # 初始化得到query_pos, query
query_pos = query_pos.unsqueeze(0).expand(batch_size, -1, -1)
query = query.unsqueeze(0).expand(batch_size, -1, -1)
reference_points = self.reference_points_fc(query_pos).sigmoid() # 与encoder不同 直接通过一个linear得到 reference_points 只有一个300的序列
decoder_inputs_dict = dict(
query=query,
query_pos=query_pos,
memory=memory,
reference_points=reference_points)
head_inputs_dict = dict(
enc_outputs_class=enc_outputs_class,
enc_outputs_coord=enc_outputs_coord) if self.training else dict()
return decoder_inputs_dict, head_inputs_dict由于我没有使用two_stage,因此没有对这部分进行分析,感兴趣的可以自己去看看源码
注意:
输入到encoder与decoder的reference_points的不同,在encoder中,只需要对一个序列进行坐标位置设置,因此不需要像encoder中的一样需要针对多个level生成reference_points。
Decoder:
将encoder与pre_decoder的输出传进decoderlayer中:
inter_states, inter_references = self.decoder(
query=query,
value=memory,
query_pos=query_pos,
key_padding_mask=memory_mask, # for cross_attn
reference_points=reference_points,
spatial_shapes=spatial_shapes,
level_start_index=level_start_index,
valid_ratios=valid_ratios,
reg_branches=self.bbox_head.reg_branches
if self.with_box_refine else None)
references = [reference_points, *inter_references]
decoder_outputs_dict = dict(
hidden_states=inter_states, references=references)
return decoder_outputs_dict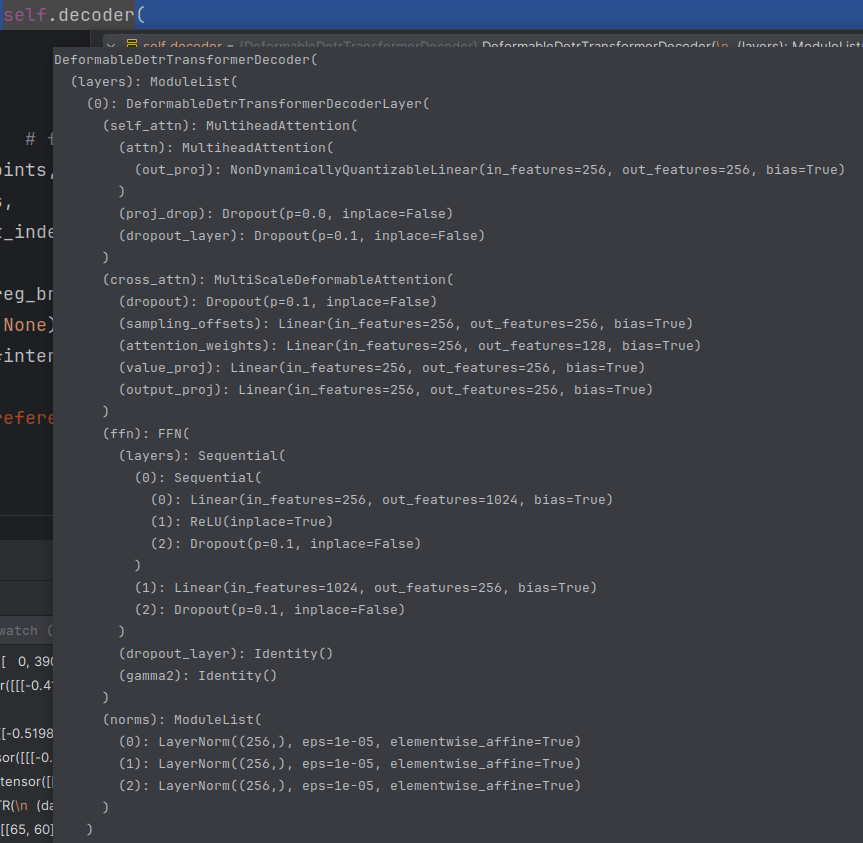
上图就是完整的一个decoderlayer流程,在该网络中,一共重复6个layer。
分类与回归输出:
6个decoder输出特征图 -> 共享分类头(1个全连接层),得到分类结果[6, bs, 300, 91];
6个decoder输出特征图 -> 共享回归头(3个全连接层),得到回归中心点xy的偏移量和wh->[bs, 300, 4],xy的偏移量 + 参考点xy反归一化 -> 最终xy坐标,再对xywh归一化得到最终的回归结果[6, bs, 300, 4];
总结:
one-stage全部流程
提前在DeformableDETR中生成6个共享分类头和6个共享回归头。backbone输出3个不同尺度的特征,然后接上3个1x1conv和1个3x3conv,最后得到4个不同尺度的特征图;
生成Encoder相对4个特征图固定的参考点xy坐标+4个不同尺度的特征图,输入encoder,得到增强版的特征图memory:[bs, H/8 * W/8 + H/16 * W/16 + H/32 * W/32 + H/64 * W/64, 256];
先随机初始化query_embed,再拆分为query(tgt)和query pos(query_embed),再用query pos(query_embed)接一个全连接层+sigmoid,得到Decoder归一化后的参考点中心坐标reference_points:[bs, 300, 2];
将query、query pos、reference_points、memory送入decoder中,输出解码后的6个decoder输出特征图hs[6, bs, 300, 256],以及6层decoder参考点归一化中心坐标inter_references[6, bs, 300, 2](全部相同 都等于reference_points);
6个decoder输出特征图 -> 共享分类头(1个全连接层),得到分类结果[6, bs, 300, 91];
6个decoder输出特征图 -> 共享回归头(3个全连接层),得到回归中心点xy的偏移量和wh->[bs, 300, 4],xy的偏移量 + 参考点xy反归一化 -> 最终xy坐标,再对xywh归一化得到最终的回归结果[6, bs, 300, 4];https://blog.youkuaiyun.com/qq_38253797/article/details/127668593
Reference:
b站:https://www.bilibili.com/video/BV1hp4y1V7Zm?p=43&vd_source=7a257917004c3f675f8f696b8a88a3a7
优快云:mmdetection项目debug:deformable-detr_mmdetection debug-优快云博客

















 3509
3509

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









