







今天学习了用Xpath去获得数据的一个小例子
import requests
from lxml import etree
url = "https://hengyang.zbj.com/search/f/?kw=saas"
resp = requests.get(url)
#print(resp.text)
html = etree.HTML(resp.text)
#html.xpath("/html/body/div[6]/div/div/div[2]/div[5]/div[1]/div[1]") #这是第一个框的div,但若要所有的要做改变
divs = html.xpath("/html/body/div[6]/div/div/div[2]/div[5]/div[1]/div") #拿到所有服务商的div
for div in divs:
price = div.xpath("./div/div/a[1]/div[2]/div[1]/span[1]/text()")[0].stripe("¥")#找位置 数字代表是第几个div或span
title = "saas".join(div.xpath("./div/div/a[1]/div[2]/div[2]/p/text()"))
companyname = div.xpath("./div/div/a[2]/div[1]/p/text()")[0] #放列表里
address = div.xpath("./div/div/a[2]/div[1]/div/span/text()")[0]
print(price)
在找xpath时,页面检查找到xpath复制即可,下图所示很清晰就能找到
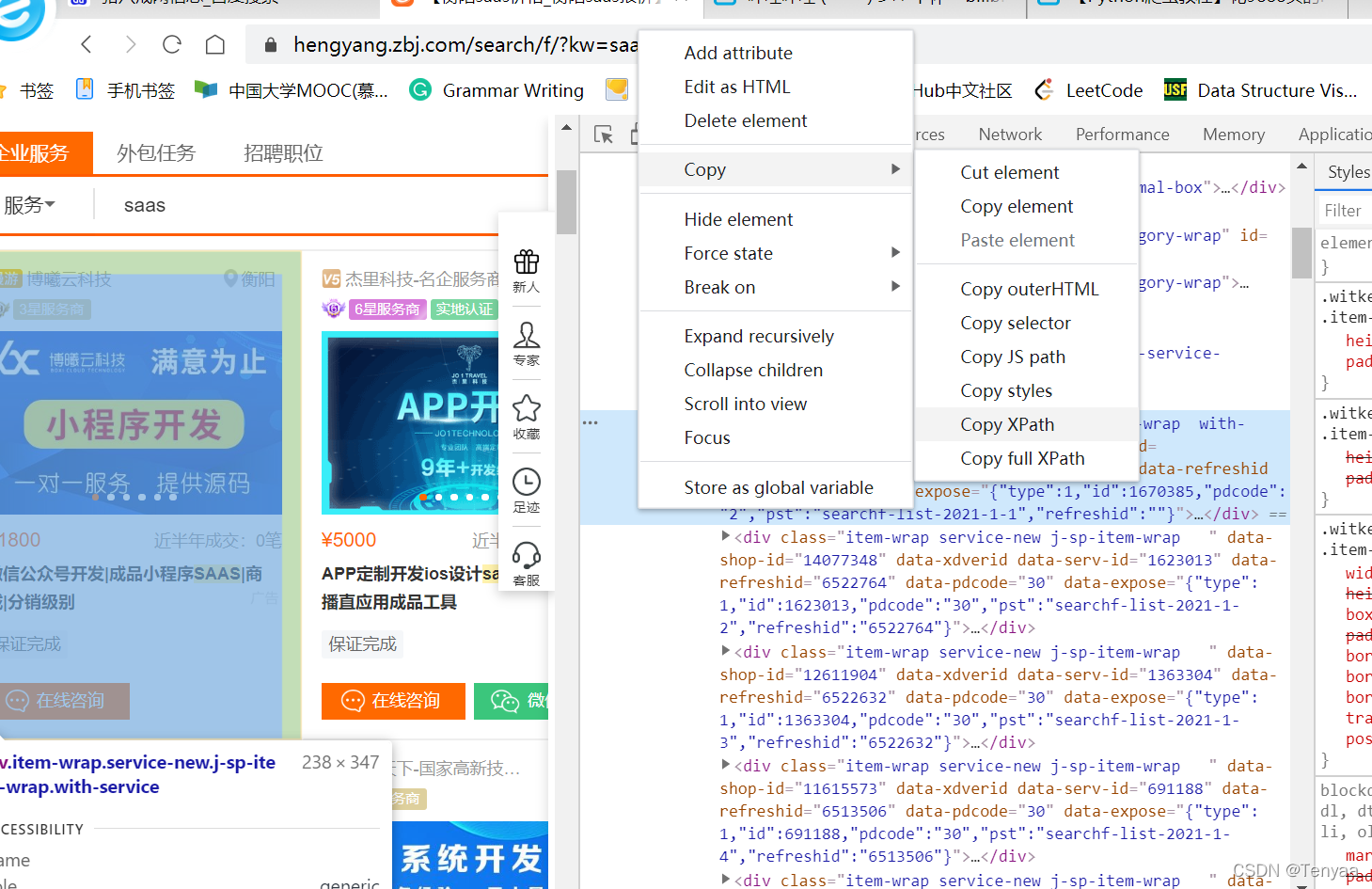
接着就是在找具体位置的时候,以下图为例:
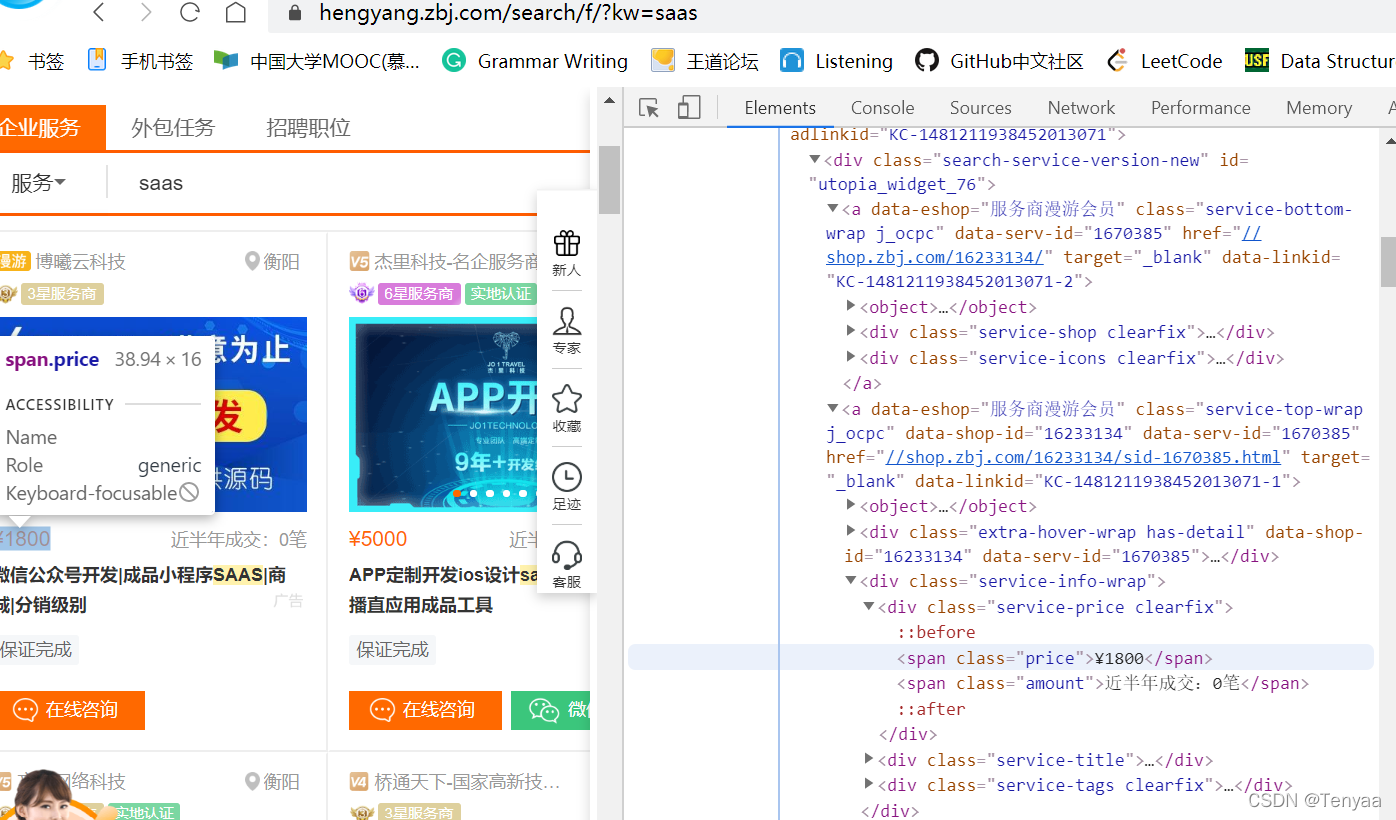
点击一行时页面就会在价格那里有很明显的对应显示。如果我们要的数据就是价格,就一层层找位置写入xpath中即可(具体见代码)


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









