







今天学习了用异步的方式获取小说内容(案例是百度小说中的西游记为例),同步虽然不是不可以,但是很慢不如异步效率高
首先查看网页源代码中,找不到章节相关信息,所以老规矩f12后打开全部章节可以看到有相关章节信息出现,headers里有存了章节信息的url,即为代码中的url1
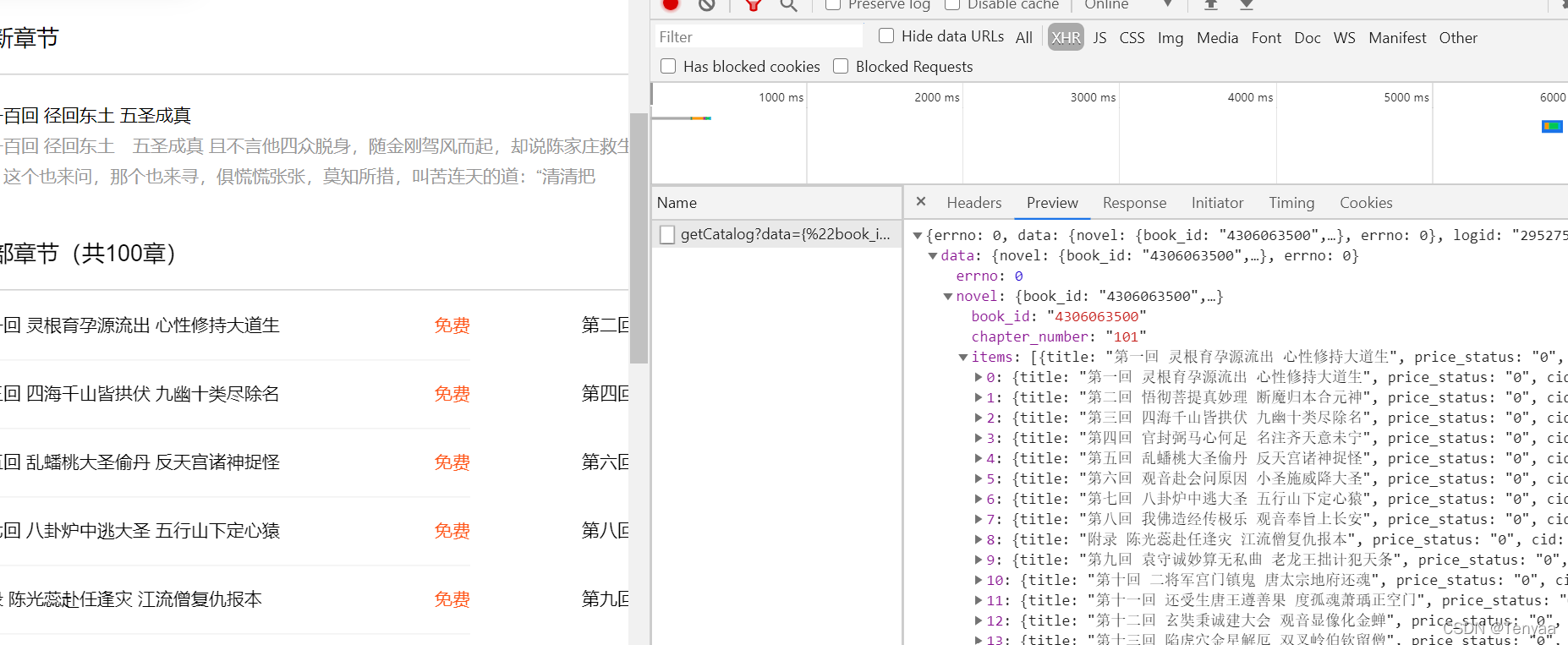
接着要具体到每一章中的文字内容,点开第一章,旁边会多吃几条信息,一个个找找到有文本content的那个信息,打开对应的headers,即为代码中的url2
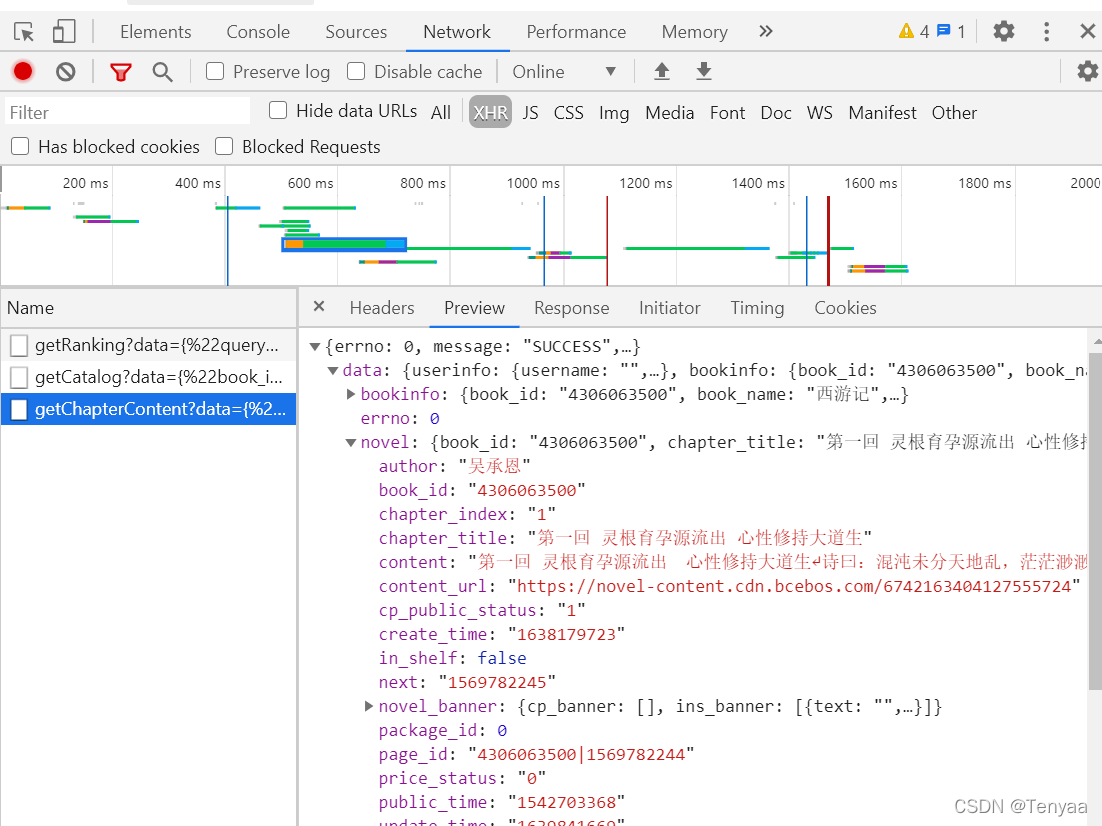
代码中text中的内容就是下图,其实就是一个字典
代码如下:
import requests
import asyncio
import aiohttp
import aiofiles
import json
'''
思路:
同步操作拿到每一章的章名和cid
再异步下载每一章节的内容
#url = 'http://dushu.baidu.com/api/pc/getCatalog?data={%22book_id%22:%224306063500%22'}
url1 = 'http://dushu.baidu.com/api/pc/getCatalog?data={"book_id":"4306063500"}' #去掉%22加上引号
#可以得到所有章节的内容(章节名,cid)
url2 = 'http://dushu.baidu.com/api/pc/getChapterContent?data={"book_id":"4306063500","cid":"4306063500|1569782244","need_bookinfo":1}'
#可以得到每一章节内部的具体内容(通过不同的cid对应不同章节)
'''
async def aiodownload(cid,b_id,title):
data = {
"book_id":b_id,
"cid":f"{b_id}| {cid}",
"need_bookinfo":1
}
data = json.dumps(data)
url = f'http://dushu.baidu.com/api/pc/getChapterContent?data={data}'
async with aiohttp.ClientSession() as session:
async with session.get(url) as resp:
dic = await resp.json()
#dic['data']['novel']['content']#其实就是找到content的“路径”
async with aiofiles.open(title,mode="w",encoding="utf-8") as f:
await f.write(dic['data']['novel']['content'])
async def getCatalog(url):
resp = requests.get(url)
#print(resp.text) #要拿到text中的cid,用json来提取cid
dic = resp.json()
tasks = []
for item in dic['data']['novel']['items']:
title = item['title']
cid = item['cid']
#准备异步任务
tasks.append(aiodownload(cid,b_id,title))
await asyncio.wait(tasks)
if __name__ == '__main__':
b_id = "4306063500"
url = 'http://dushu.baidu.com/api/pc/getCatalog?data={"book_id":"' + b_id + '"}'
asyncio.run(getCatalog(url))
ps:
运行的时候最好建个文件夹,100多章的全显示出来会卡死
如果有的包没有,直接在pycharm中点击terminal,在终端中输入pip install 包名 等待下载成功即可
over!


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









