






项目:https://johanan528.github.io/depthlab_web
来源:香港大学,香港理工大学,蚂蚁集团,阿尔托大学,统一实验室
摘要
DepthLab是一个由图像扩散先验驱动的深度补全模型,具有两个优势: (1)它展示了对深度缺失区域的弹性,为连续区域和孤立点提供了可靠的重建,;(2)在填充缺失值时,它忠实地保持了与条件已知深度的尺度一致性。基于这些优点,我们的方法在各种下游任务中证明了其价值,包括三维场景重绘、文本到-三维场景生成、DUST3R稀疏视图重建和激光雷达深度重建 ,在数值性能和视觉质量上都超过了当前的解决方案。
一、引言
深度重绘(Depth Inpaint)是重建图像中缺失或遮挡的深度信息的任务,在许多领域都至关重要,包括3D视觉、机器人和增强现实。以往的Depth Inpaint可分为两种主要方法。第一种方法侧重于将全局稀疏的激光雷达深度数据 complet到密集的深度,通常在固定的数据集上进行训练和测试。然而,这些模型缺乏泛化,并且在不同的下游任务中的适用性有限。第二种方法使用单目深度估计器来推断单个图像的深度,将已绘制的区域与已知的深度对齐。这些方法经常遭受显著的几何不一致,特别是沿边缘,由于估计的不对准,现有的几何。最近的研究[41]将RGB图像整合到UNet输入中,作为训练深度绘制模型的指导,但其性能在复杂场景和绘制大的缺失区域时仍然不理想。
为此,DepthLab引入了双分支深度扩散扩散框架:提取RGB特征作为条件,将已知深度和需要不绘制的mask输入深度估计U-Net。训练过程中,对已知深度进行随机尺度归一化,以缓解已知区域内非全局极值引起的正则化溢出。与Marigold类似,模型只需要合成RGBD数据,只用几天GPU天进行训练。得益于扩散模型的强大先验,DepthLab在不同的场景中展示了强大的泛化能力。
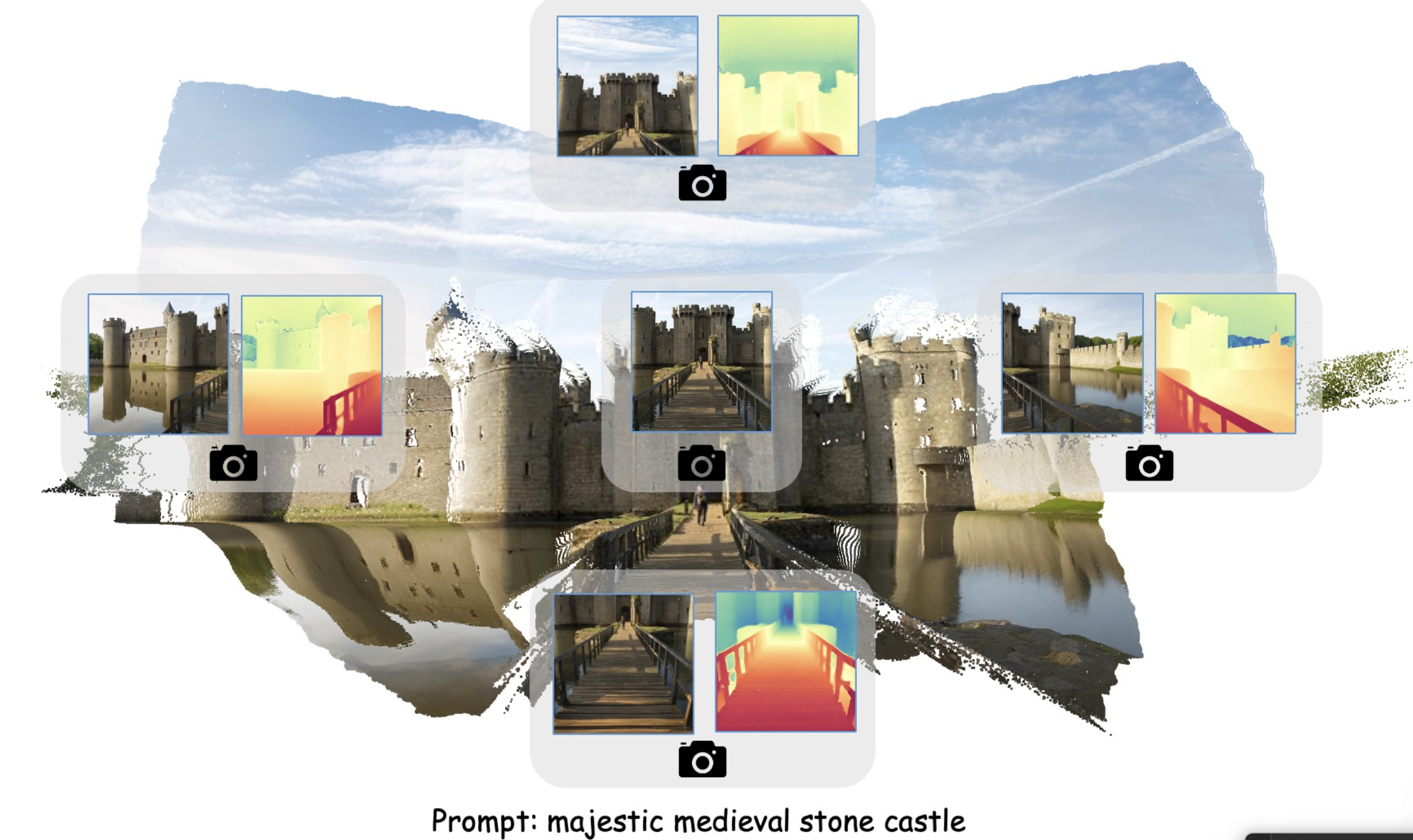
如图1,由于精确的depth inpainting,,DepthLab支持各种下游应用程序。(1)三维场景重绘:首先从带pose的参考视图中绘制mask区域的深度,然后将点反投影到三维空间进行最优初始化,显著提高了三维场景内画的质量和速度。(2)文本到场景的生成:通过消除对齐的需要,大大改进了从单个图像生成3D场景的过程。这一进展有效地减轻了以前由重绘深度和已知深度之间的几何不一致引起的边缘分离问题,从而显著提高了生成场景的一致性和质量。(3)使用DUST3R进行稀疏视图重建:InstantSplat利用来自DUST3R 的点云作为无sfm重建和新视图合成的初始化。通过在DUST3R深度图中添加噪声作为潜在输入,DepthLab在缺乏交叉视图对应的区域中细化深度,产生更精确、几何一致的深度图。这些改进的深度图进一步增强了InstantSplat的初始点云。(4)激光雷达深度补全:传感器深度补全是与深度估计相关的重要任务。与现有的在单一数据集上进行训练和测试的方法不同,如NYUv2。

二、方法
给定原始(不完整或扭曲)深度图 d ′ ∈ R 1 × H × W d'∈R^{1×H×W} d′∈R1×H×W,二进制mask m ∈ R 1 × H × W m∈R^{1×H×W} m∈R1×H×W指示inpaint区域,条件RGB图像 I ∈ R 3 × H × W I∈R^{3×H×W} I∈R3×H×W,目标是预测完整的深度图 d ∈ R H × W d∈R^{H×W} d∈RH×W。 这涉及到保留未mask区域的深度值,同时准确地估计mask区域的深度。这个过程自然地将估计深度与现有几何对齐。
DepthLab引入了一个基于双分支扩散的深度绘制框架,包括一个用于RGB特征提取的 Reference U-Net和一个以原始深度和inpaint mask作为输入的 Estimation U-Net。不同于常用的文本条件,我们利用交叉注意与CLIP图像编码器来捕获丰富的语义信息。通过对参考U-Net和估计U-Net之间的注意,逐层进行特征融合,可以实现更细粒度的视觉引导。这种设计使DepthLab能够取得显著的结果,即使是在大的inpaint区域或复杂的RGB图像,如图2。
1.网络设计
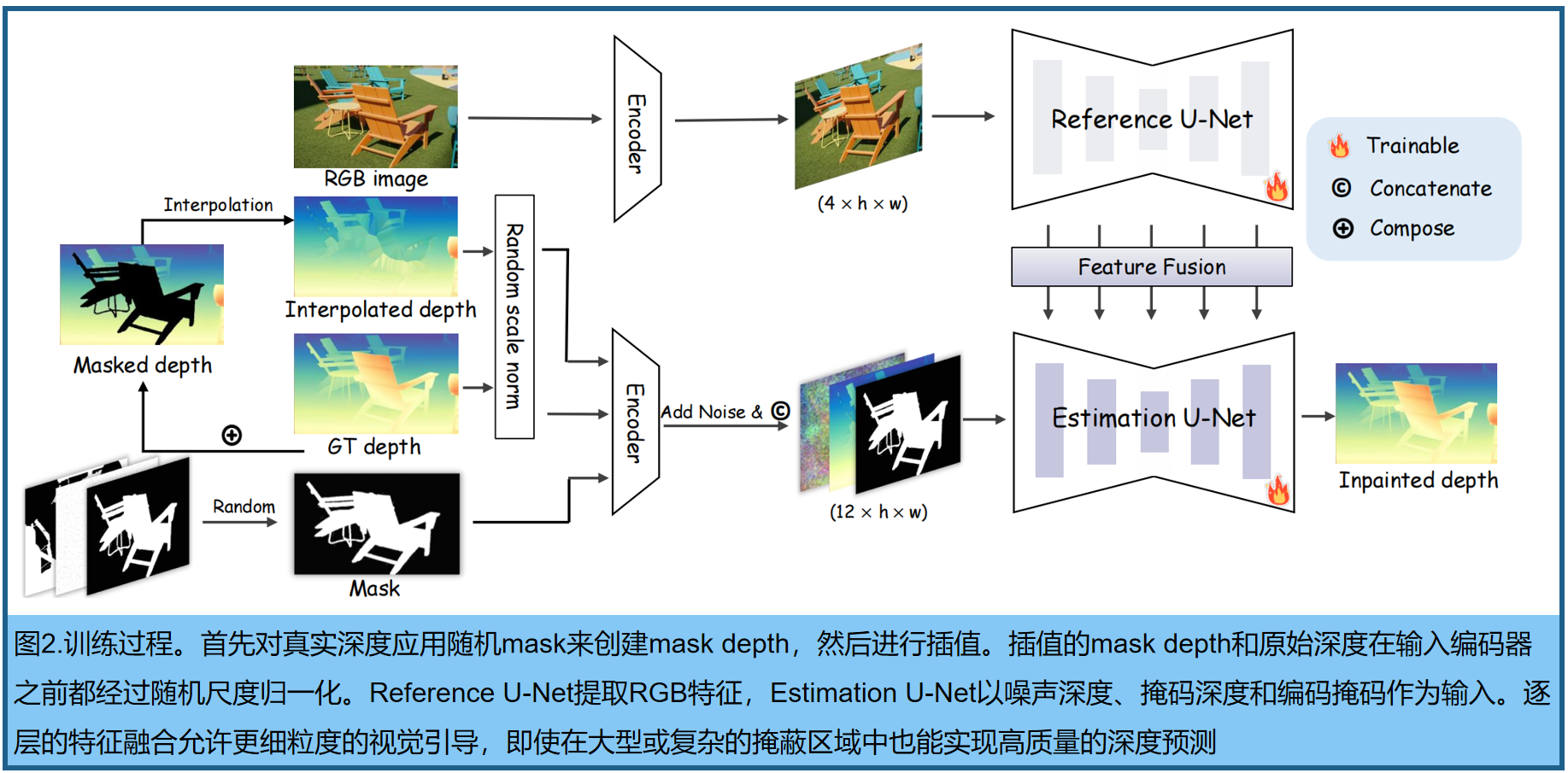
两个分支都使用Marigold 作为基础模型,从SD V2 [56]中微调。这种设计消除了从RGB到Depth 的域迁移过程的需要,提高了训练效率。
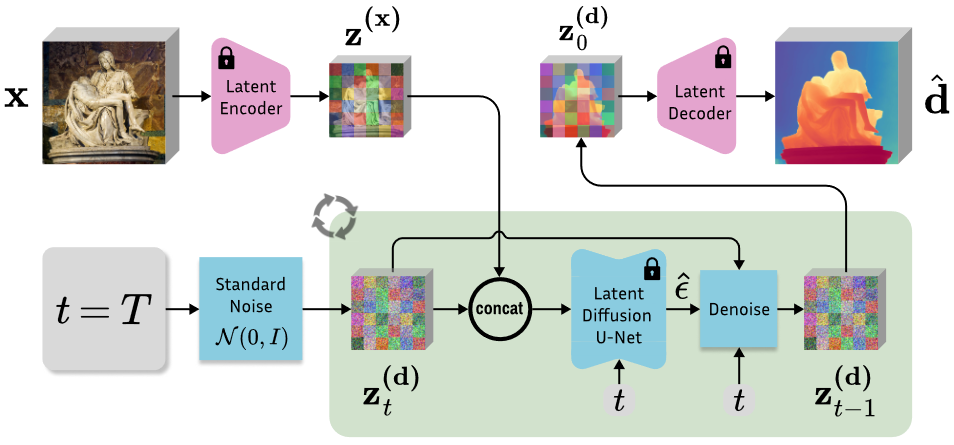
深度编码器和解码器。使用冻结的VAE编码器 E E E 将RGB图像及对应的深度图编码到潜在空间中。单通道depth map复制三个通道进行,以匹配 E E E的输入。由于VAE编码器是用于非稀疏输入的,在编码前应用最近邻插值来稠密化稀疏深度图。推理过程中,使用解码器 D D D 对t = 0 step的去噪深度latent z 0 ( d ) ∈ R 4 × h × w z_0^{(d)}∈R^{4×h×w} z0(d)∈R4×h×w进行解码,并将三个通道的平均值作为预测的深度图。与Magiod估计相对深度并使用最大平方优化来获得度量深度不同,我们的depth Inpaint目的是基于已知深度区域的值和尺度直接估计度量深度图。
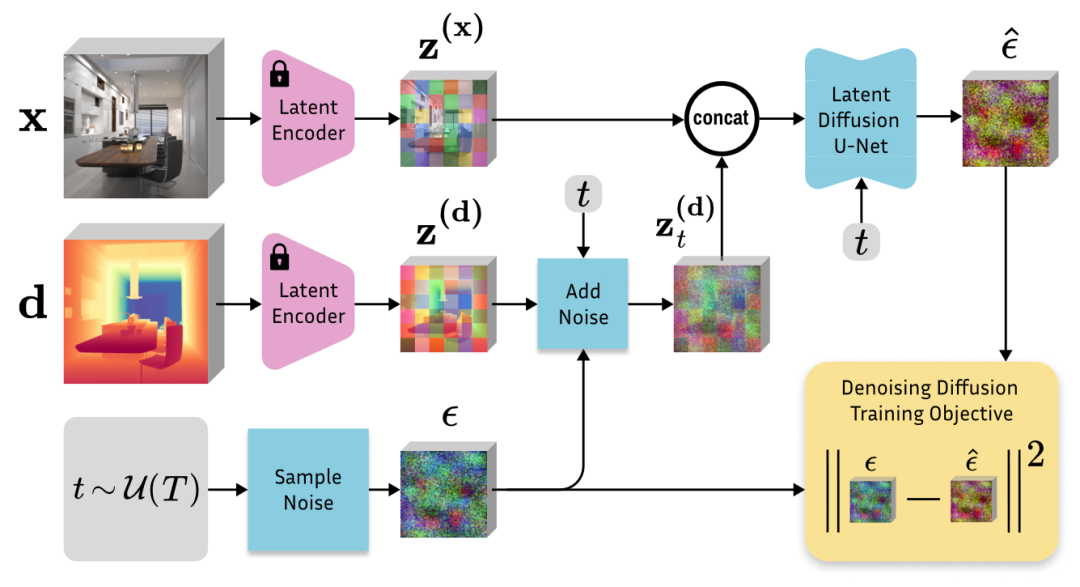
Estimation Denoising U-Net :输入由三部分组成: noisy depth latent z t ( d ) ∈ R 4 × h × w z_t^{(d)}∈ R^{4×h×w} zt(d)∈R4×h×w, masked depth latent z ( d ′ ) ∈ R 4 × h × w z^{(d')} ∈ R^{4×h×w} z(d′)∈R4×h×w, encoded mask m ′ ∈ R 4 × h × w m' ∈ R^{4×h×w} m′∈R4×h×w, 拼接再一起。latent depth 表示有4个通道,由VAE编码产生,(h,w)比原始输入维度下采样了8倍。为了更准确地保存mask信息,使用VAE编码mask m ∈ R 1 × H × W m∈R^{1×H×W} m∈R1×H×W获得 m ′ ∈ R 4 × h × w m'∈R^{4×h×w} m′∈R4×h×w,有效地保留稀疏和细粒度的信息。
训练中,将初始深度图 d d d 编码到潜在空间中,step t处添加噪声,得到noisy depth latent z t ( d ) z_t^{(d)} zt(d)。 masked depth latent z ( d ′ ) z^{(d')} z(d′) 是对真实深度图随机mask,然后在inpaint区域进行最近邻插值,并通过VAE进行编码。由于SD的VAE擅长于重建密集信息,因此该方法更好地保留了稀疏点和复杂边缘边界上的已知深度值
Reference U-Net 。Infusion 将单个参考图像输入编码器,随后将image latent 与noisy depth latent, masked depth latent,接起来,得到13个通道。然而,这种方法可能会失去区域深度信息或难以生成清晰的深度边缘,特别是在重绘大区域或使用复杂的参考图像时。最近的研究表明,一个额外的U-Net可以从参考图像中提取更细粒度的特征。受该启发,首先从Reference U-Net和Estimation Denoising U-Net中得到两个特征图, f 1 ∈ R c × h × w f_1∈R^{c×h×w} f1∈Rc×h×w和 f 2 ∈ R c × h × w f_2∈R^{c×h×w} f2∈Rc×h×w并拼接,得到 f 1 ∈ R c × h × 2 w f_1∈R^{c×h×2w} f1∈Rc×h×2w,执行自注意力操作,将输出的前半部分作为输出。由于Reference U-Net和Estimation Denoising U-Net具有相同的架构和初始权值——都是在Marigold 上预先训练的——估计去噪U-Net可以在同一特征空间内选择性地从参考U-Net中学习相关特征。
2.训练方案
深度归一化 。目标是在已知的区域内保持原始的深度信息,预测未知的未绘制区域的深度,并避免几何不一致。最终输出绝对深度图。计算已知深度区域的最小值和最大值( d m i n 和 d m a x d_{min}和d_{max} dmin和dmax),并将它们线性归一化到[−1,1]的范围。由于局部最小值和最大值不同于全局最小值和最大值,可能导致VAE解码过程中的溢出,因此在规范化过程中引入了一个在[0.2,1.0]范围内的随机压缩因子β:
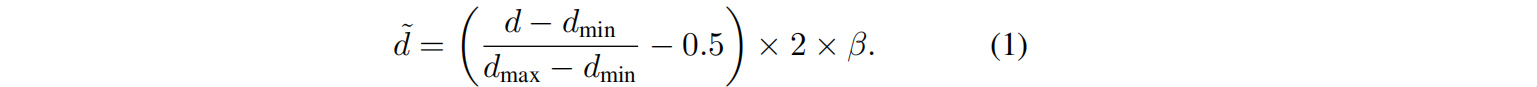
这种方法遵循了稳定扩散VAE的约定,同时也强制执行了一个独立于数据统计量的规范的、仿射不变的深度表示,确保了深度值受到近平面和远平面的限制,提供了稳定性,并减少了数据分布的影响。最后,对网络输出进行反归一化,恢复绝对深度尺度,实现深度嵌 inpaint。
Masking strategy 。为了最大限度地扩大大量下游任务的覆盖范围,采用了各种mask策略,从笔画、圆、正方形或这些形状的随机组合中随机选择来创建mask。其次,为了增强深度补全任务——从传感器捕获的稀疏深度数据中恢复一个完整的深度地图,采用随机点mask,其中只有0.1-2%的点被设置为已知的。最后,为了改进对象级的inpaint,使用Ground-sam[54]来标注训练数据,然后根据置信度过滤mask。多种掩mask策略的组合应用进一步提高了该方法的鲁棒性。
三、实验
3.1 实验设置与对比
训练细节。数据集包含两个:Hypesim包含461个室内场景的真实数据集,约54K个训练样本;Virtual KITTI是一个合成的街景数据集,包括五个不同条件下的场景,如天气和相机视角,大约有2万k个样本。训练200个epoch,使用随机翻转数据增强,在8个A100-80Ggpu训练两天。
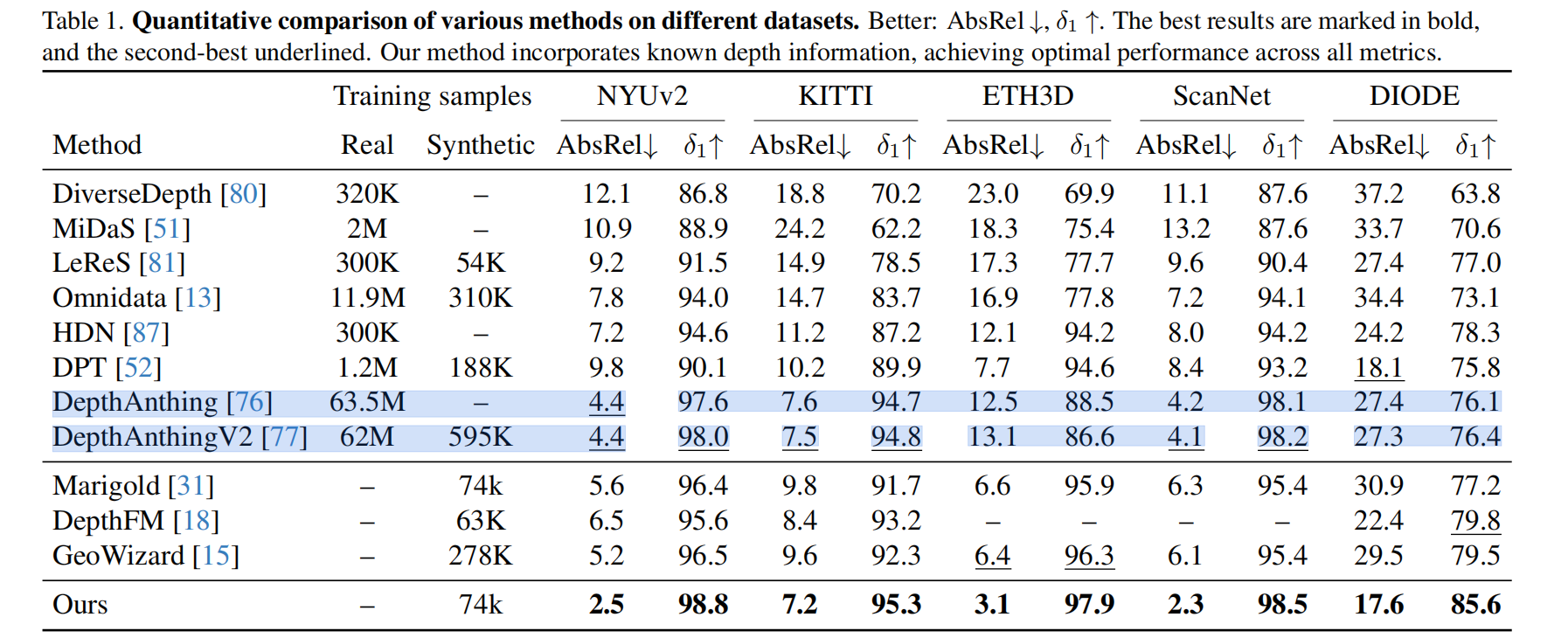
评估数据集。在五个zero-shot基准测试中评估性能,包括NYUv2 [46]、KITTI [17]、ETH3D [59]、ScanNet [9]和DIODE[66],推理随机选择笔画、圆、正方形或三者的组合来表示未知区域。此外,我们还包括了另一种类型的掩模,其中我们只在整个图像中随机设置0.5%到1%的稀疏像素为已知的深度。

3.2 应用
3D gaussian inpainting。首先采用高斯Grouping[78]来分割和去除部分高斯分布。然后,将SDXL inpaint model[50]应用于参考视图上的渲染图像。 重绘后的RGB图像随后作为指导,以完成该参考视图的深度信息 。然后将这些 点反投影到三维空间中以进行最优初始化 。如图4所示,由于重绘高斯和原始高斯之间的几何一致性,以及像素和重绘高斯之间的对齐,对绘制图像进行简单的编辑,可以在绘制区域进行纹理修改和插入对象。

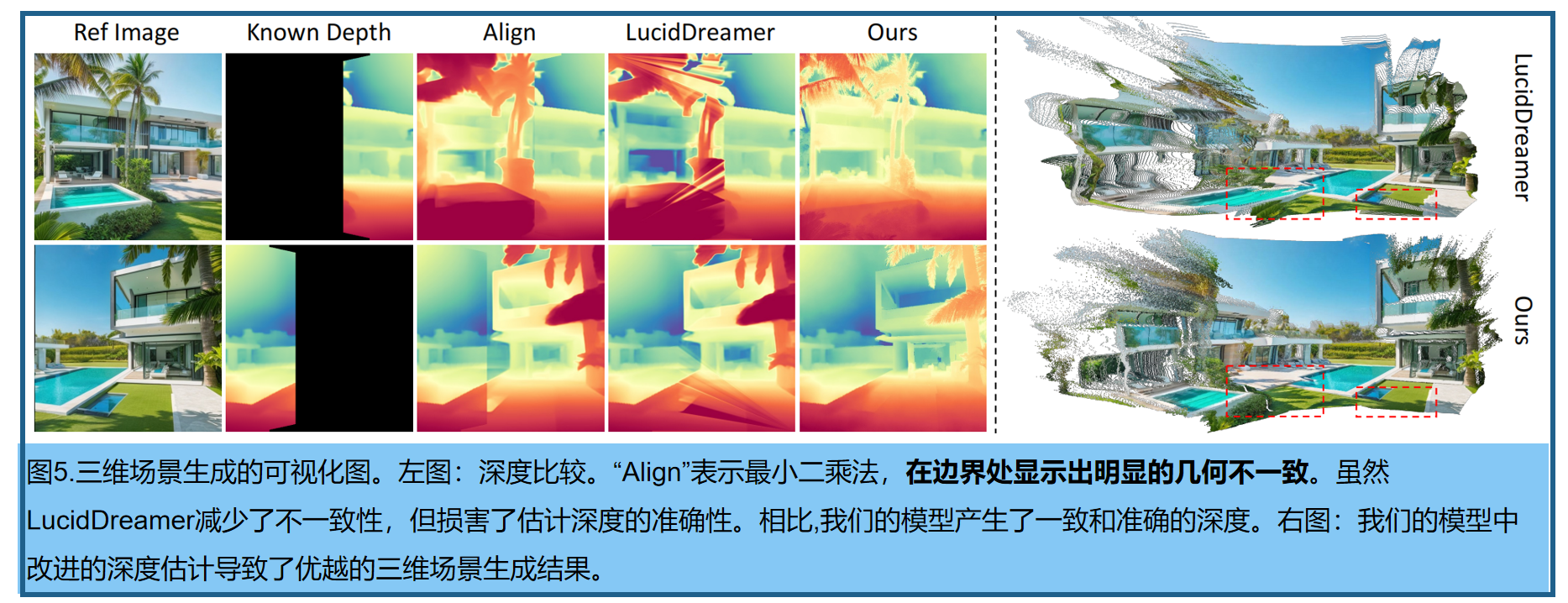
文本到三维场景生成。最近的方法[8,47,92]首先将单视图深度估计投影到3D场景上,从给定的视点创建一个初始点云。然后通过旋转照相机来计算warped image 和 warped depth。在对warped image进行inpaint后,采用单目眼深度估计将估计的深度与之前的warped depth对齐。然后,将对齐后的深度数据反投影回原始的点云中。然而,如图5所示,以LucidDreamer为例,该方法在不同尺度的深度对齐过程中存在几何不一致,对重绘区域的深度精度产生不利影响。相比之下,我们的模型可以直接将inpaint 图像和warped depth 作为输入,生成几何上一致的深度图,而不需要对齐
DUST3R重建。DUST3R可以重建没有相机pose的三维场景,提供密集的像素对和像素对点对应,适用于深度预测等各种三维视觉任务。然而,DUST3R主要在具有像素对应的点上提供高质量的深度预测,同时努力为不同视图之间没有对应的点生成清晰的深度边缘。
为了克服这一限制,我们引入了一个细化框架,来改进具有弱或不存在对应的区域的深度估计。我们的方法首先为没有从任何源图像中匹配的像素生成一个mask。这些不匹配的区域然后通过DepthLab进行细化。具体来说,我们使用变分自编码器(VAE)将DUST3R的初始深度估计编码到潜在空间,增加噪声产生噪声 latent。匹配点的深度被编码为 mask深度latent。有噪声和掩蔽的潜在表示,以及它们各自的掩模,都被输入到我们的模型中,以生成具有增强的精度和空间一致性的精细深度图。我们在 Intantsplat[14]上评估了我们的方法,这是一种稀疏视图、无sfm的高斯溅射方法,它使用来自DUST3R的预测点云来进行新的视图合成。通过将我们的增强的深度映射取消投影到3D空间中,我们用我们的改进数据替换了DUST3R的原始点云,作为InstanSplat的输入。如图6,我们的方法有效地提高了DUST3R的初始深度,大大提高了高斯喷溅的渲染质量。

Sensor depth completion。传感器深度完成是与深度估计相关的一项重要任务,在机器人技术和自主导航领域有着广泛的应用。由于深度传感器的硬件限制,只有部分深度图像可用,因此需要在保留已知深度值的同时填充缺失的深度值。我们根据稀疏深度的坐标得到相应的掩模,并在NYU深度v2 [46]上进行比较。按照CompletionFormer,评估使用双线性插值将大小为640×480的原始帧降采样一半,然后将中心裁剪到304×228,只有500个地面真实像素可用。如标签页中所示。2,我们的模型不同于传统的深度补全方法,后者通常是在固定的数据集上进行训练和测试,导致了有限的泛化能力。相比之下,我们的方法在不需要复杂设计的情况下表现出更好的泛化,并且只进行了10,000步的微调,它实现了与最先进的方法相媲美的性能,展示了它作为深度完成任务的基础模型的潜力。此外,一个主要的限制是需要在潜在空间中对mask进行降采样,其中SD 2.1的VAE难以精细地重建极其稀疏的数据。
四 拓展:Marigold:基于扩散的单目深度估计(CVPR 2024 Oral)
https://marigoldmonodepth.github.io/
创新点:
-
提出了一种简单且资源高效的微调协议,可将预训练的 LDM 图像生成器转换为图像条件深度估计器;
-
提出了Marigold,一种最先进的多功能单目深度估计模块,可在各种自然图像中提供出色的性能。
生成公式
将单目深度估计任务定义为一个条件去噪扩散生成任务。具体地,Marigold用于建模条件分布 D ( d ∣ x ) D(d|x) D(d∣x),其中d代表深度,x是给定的RGB图像。通过逐步添加和移除噪声,模型能够从噪声数据中恢复出清晰的深度信息。训练过程中,模型通过对抗性学习调整参数,以最小化去噪扩散目标函数,从而有效地从输入的RGB图像预测出对应的深度图。这种生成式框架不仅提升了深度估计的准确性,也增强了模型对新领域数据的泛化能力。
网络架构
Marigold的核心是预训练的文本到图像的潜在扩散模型(LDM),主要进行了微调以适应深度估计任务。该架构包括一个冻结的变分自编码器(VAE)用于编码图像和深度信息至潜在空间,并结合使用特定的深度编码器和解码器。在去噪过程中,模型通过修改U-Net来实现对图像的条件编码,从而提高了训练效率并保持了高分辨率图像生成的能力。通过这种精心设计的网络架构,Marigold能够高效地处理深度估计任务,同时保留了强大的图像先验知识。
微调协议
Marigold通过采用仿射不变深度归一化和训练于合成数据上的策略,模型能够有效地适应和学习从单一GPU上的短期训练中获得的合成RGB-D数据,这种数据无需复杂的预处理。此外,使用多分辨率噪声和退火调度的策略进一步提高了训练效率和模型性能。这一协议不仅提高了深度估计的准确性,还确保了模型对新场景的良好泛化能力,展示了在有限资源下通过微调预训练模型达到先进性能的可能性。
实验过程
Marigold模型推理时,模型通过逐步去除输入噪声来重构深度图,从一个随机噪声初始化开始,依次应用学习到的去噪操作。此外,为了提高预测的一致性和精度,研究者还提出了一个测试时集成方案,通过多次推理并聚合结果来优化最终深度预测。这种方法的实施,加上模型的生成性质和基于潜在空间的操作,使得Marigold在实际应用中能够有效地处理和优化深度估计任务。
实施细节
利用 Stable Diffusion v2 作为骨干并禁用文本调节。训练期间,应用具有 1000 个扩散步骤的 DDPM 噪声调度器。在推理时,应用 DDIM 并采样 50 个步骤。对于最终预测,汇总 10 次具有不同起始噪声的推理运行的结果。使用 32 的批量大小迭代 18000 次。为了适合一个 GPU,我们梯度累积步骤 16 ,使用Adam 优化器学习率为 3e−5 。此外,对训练数据应用随机水平翻转。在单个 Nvidia RTX 4090 GPU上,训练耗时大约需要 2.5 天。
训练集:Marigold模型在两个合成数据集上进行训练:Hypersim 和 Virtual KITTI。Hypersim 数据集包含461个室内场景的高分辨率图像和深度图,而 Virtual KITTI 数据集模拟不同天气和摄像头视角下的街景环境。这些数据集提供了丰富的环境和控制条件下的数据,有助于模型学习和预测深度信息。
评估集:使用五个未见过的真实世界数据集,包括两个室内场景数据集(NYUv2 和 ScanNet)和三个室外场景数据集(KITTI、ETH3D 和 DIODE)。这些数据集通过RGB-D Kinect传感器或LiDAR传感器收集,涵盖从住宅室内到复杂城市街景的多种环境。

















 3145
3145

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









