







 本文介绍了信息论中的基本概念——熵,它表示一种可能性的所有信息量。接着讨论了相对熵(KL散度),用于衡量真实分布与预测分布的差异,值越小表示两者越接近。最后,解释了交叉熵的概念,它是从KL散度公式变形而来,常用于损失函数优化。博客适合信息论和机器学习的学习者进行复习和整理。
本文介绍了信息论中的基本概念——熵,它表示一种可能性的所有信息量。接着讨论了相对熵(KL散度),用于衡量真实分布与预测分布的差异,值越小表示两者越接近。最后,解释了交叉熵的概念,它是从KL散度公式变形而来,常用于损失函数优化。博客适合信息论和机器学习的学习者进行复习和整理。
便于理解但是不够精确的说法:
熵:一种可能性的所有的信息量
相对熵(KL散度):真实分布与预测的分布的信息量的差(真实-预测),值越小说明与真实约接近。
交叉熵:由kl散度公式变形而得,式子拆开来前半部分是熵后半部分就是交叉熵。因为前面的熵不变,所以优化的时候直接用交叉熵计算损失更加方便。
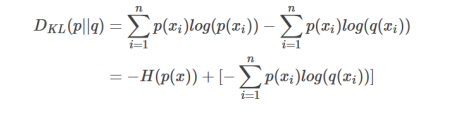 博客记录便于复习与整理,如有不对请指教,谢谢!
博客记录便于复习与整理,如有不对请指教,谢谢!
参考文献
https://blog.youkuaiyun.com/tsyccnh/article/details/79163834
便于理解但是不够精确的说法:
熵:一种可能性的所有的信息量
相对熵(KL散度):真实分布与预测的分布的信息量的差(真实-预测),值越小说明与真实约接近。
交叉熵:由kl散度公式变形而得,式子拆开来前半部分是熵后半部分就是交叉熵。因为前面的熵不变,所以优化的时候直接用交叉熵计算损失更加方便。
博客记录便于复习与整理,如有不对请指教,谢谢!
参考文献
https://blog.youkuaiyun.com/tsyccnh/article/details/79163834
 6144
4780
6144
4780

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言


























