







文章目录
各类概率分布的代码
# Normal distribution
dnorm(seq( -3, 3, by = 0.1), mean = 0, sd = 1)
pnorm(seq( -3, 3, by = 0.1), mean = 0, sd = 1)
qnorm(seq( 0.1, 0.9, by = 0.1), mean = 0, sd = 1)
rnorm(10, mean = 0, sd = 1)
# Binomial distribution
dbinom(x, N, p)
pbinom(x, N, p)
qbinom(q, N, p)
rbinom(n, N, p)
rchisq(100, df = 3) # chi square distribution
runif(x, min, max) # Uniform distribution
rnbinom(10, mu=3, theta=2) # Negative binomial distribution
rpois(x, lambda) # Poisson distribution
rgamma(100, shape = 3, scale = 2) # Gamma distribution
rweibull(100, shape = 3, scale = 2) # Weibull distribution
# F distribution
df(x, df1, df2, log = FALSE)
pf(q, df1, df2, lower.tail = TRUE, log.p = FALSE)
qf(p, df1, df2, lower.tail = TRUE, log.p = FALSE)
rf(n, df1, df2)
一、离散分布
1 二项分布
二项分布的条件。

随机生成100个数(1和0),看100数中1的累计值,重复4次。
N = 100 # number of trials
p = 0.5 # probability of success
N.EXP = 5
trial = numeric(N)
BN = numeric(N.EXP)
trial.1 = sample(c(1, 0), 1, p=c(p, 1-p))
for (j in 1:N.EXP) {
for (i in 1:N){
trial[i] = sample(c(1, 0), 1, p=c(p, 1-p))}
X = sum(trial)
BN[j] = X
}
BN
hist(BN)
mean(BN)
var(BN)

# R function 骰子为5的概率
p.x <- function(n, p, x)
{gamma(n+1)/gamma(x+1)/gamma(n-x+1)*p^x*(1-p)^(n-x)}
p.x(n=10, p=1/6, x=5)
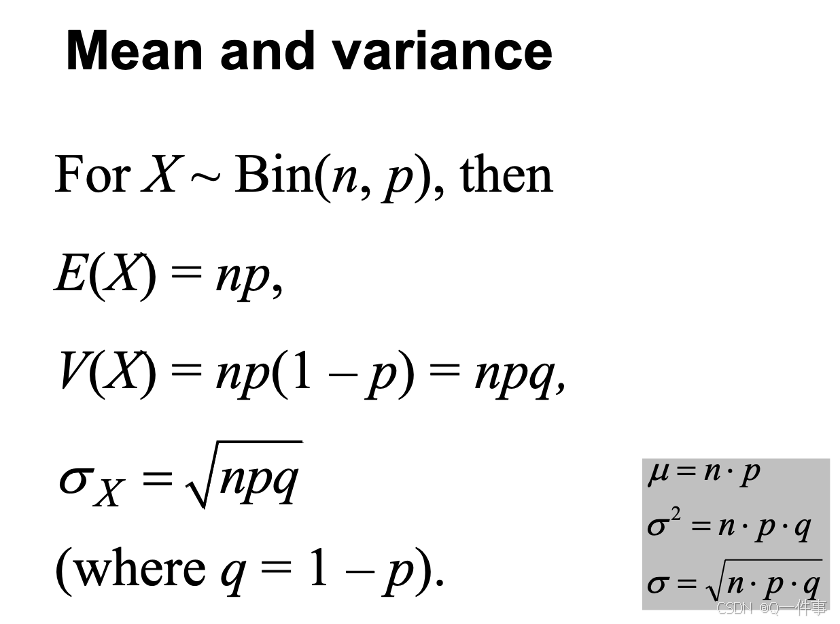
公式推导:https://zhuanlan.zhihu.com/p/89366172
不同参数的概率密度函数,当概率函数的p值不一样
binomial.PDF = dbinom(0:10, 10, 0.5)
plot(binomial.PDF * 10, type = 'l', ylim = c(0, 4.5),
xlab = "Number of success", ylab = "Frequency",
main = paste('dbinom (0:10, 10, P) # P = 0.1, 0.2, ..., 0.9', sep = ''))
for (i in seq(0.1, 0.9, by = 0.1)) {
binomial.PDF = dbinom(0:10, 10, i)
lines(binomial.PDF * 10, type ='l', # 线的颜色
col = rainbow(9)[i*10], lwd=2) # 设置不同的颜色类型
legend(-0.3 + 11 * i, 4.5,
paste('p =', i, sep = " "), # 图例的设置
text.col = rainbow(9)[i * 10], # 颜色的设置
box.lty = 0, cex = 0.8)
}
2 poisson distribution
它是描述小概率的事件的情况。例如,婴儿的死亡率。
是个离散分布,有标准值,有p值。没有方差?
这样也可以算出概率密度函数。
0,1,2分布的情况

一般用均值来表示朗姆大,用模型来进行比较,最后得出它的结果。
这个时候算n特别大,p特别小的情况。
查看网上的情况

link:参考的链接
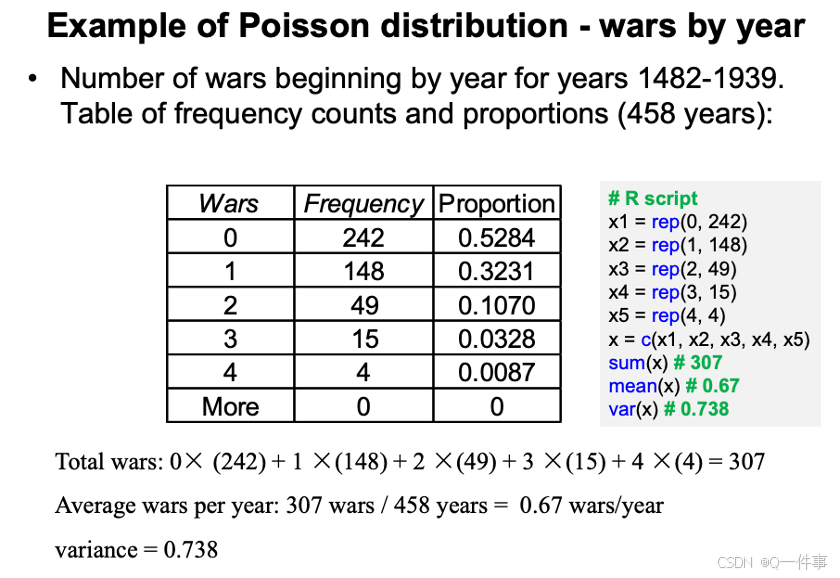
# R script
x1 = rep(0, 242)
x2 = rep(1, 148)
x3 = rep(2, 49)
x4 = rep(3, 15)
x5 = rep(4, 4)
x = c(x1, x2, x3, x4, x5)
sum(x) # 307
mean(x) # 0.67
var(x) # 0.738
# R script
options(digits = 3) # 控制有效打印的数字
dpois(0:4, 0.67) #这里的唯一参数值为0.67,计算0:4所有可能的柏松分布的值。
柏松和二项分布的比较。
# Poisson distribution
poisson = dpois(1:10, 1.25)
plot(poisson, type='b', lwd=2, xlab="X", ylab="Probability")
# bionomial distribution
bn = dbinom(1:10, 150, 0.008)
lines(bn, col="blue", lwd=2)
随着lambda的值的变化,柏松分布图像的变化。
lambda <- 1
poisson.d <- dpois(seq(1,20), lambda)
plot(poisson.d, xlab = 'X', ylab="p", type='l')
for (lambda in 1:10){
poisson.d <- dpois(seq(1,20), lambda)
lines(poisson.d, type = 'l',
col = rainbow(10)[lambda])
legend(lambda, 0.4-lambda/45,
paste('lambda =', lambda, sep=' '),
text.col = rainbow(10)[lambda],
box.lty = 0, cex = 0.5)}
柏松分布的性质。

3 负二项分布
在发生指定(非随机)次数的失败(表示为 r)之前,一系列伯努利试验中的成功次数。
负二项分布的特点。

size <- seq(1, 10, len = 10); prob = seq(0.01, 1, len = 20)
p.nb <- matrix(apply(expand.grid(size, prob), 1,
function(z) dnbinom(5, size = z[1], prob = z[2])), # x=5
nrow = length(size), ncol = length(prob))
colnames(p.nb) <- round(prob, 2); rownames(p.nb) <- size
image(size, prob, p.nb, col = terrain.colors(12), xlab = 'Size', ylab = 'p')
contour(size, prob, p.nb, add = TRUE)
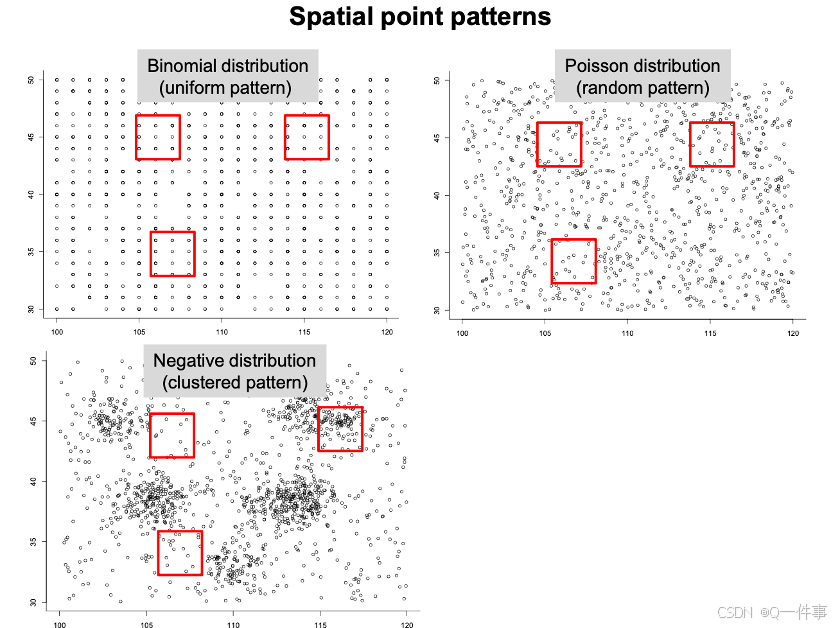
4 离散分布总结
三大离散分布:数据都是整数。以及各项分布的均值和方差。

怎么去判断,用那个分布
二、连续分布
几种比较重要的连续分布。

1 均匀分布
均匀分布,
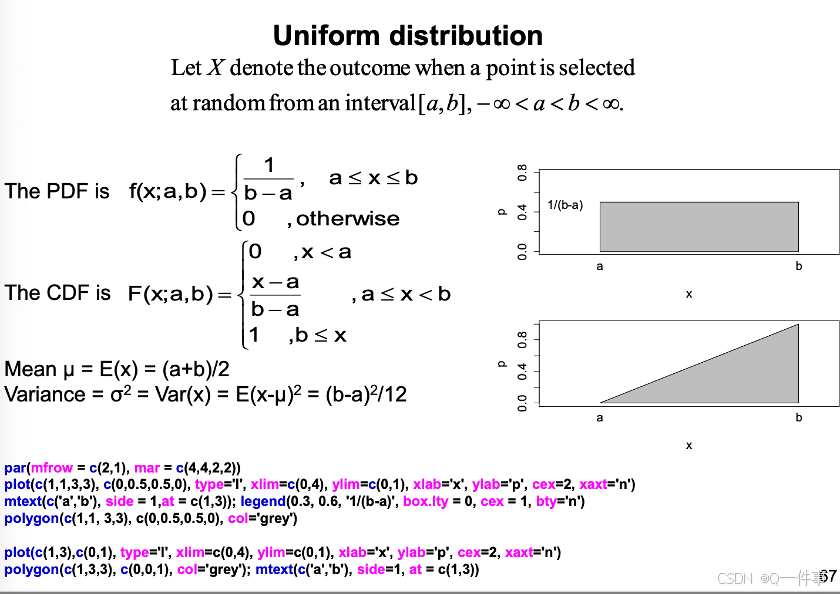
par(mfrow = c(2,1), mar = c(4,4,2,2))
plot(c(1,1,3,3), c(0,0.5,0.5,0), type='l', xlim=c(0,4), ylim=c(0,1), xlab='x', ylab='p', cex=2, xaxt='n')
mtext(c('a','b'), side = 1,at = c(1,3)); legend(0.3, 0.6, '1/(b-a)', box.lty = 0, cex = 1, bty='n')
polygon(c(1,1, 3,3), c(0,0.5,0.5,0), col='grey')
plot(c(1,3),c(0,1), type='l', xlim=c(0,4), ylim=c(0,1), xlab='x', ylab='p', cex=2, xaxt='n')
polygon(c(1,3,3), c(0,0,1), col='grey'); mtext(c('a','b'), side=1, at = c(1,3))
2 正态分布
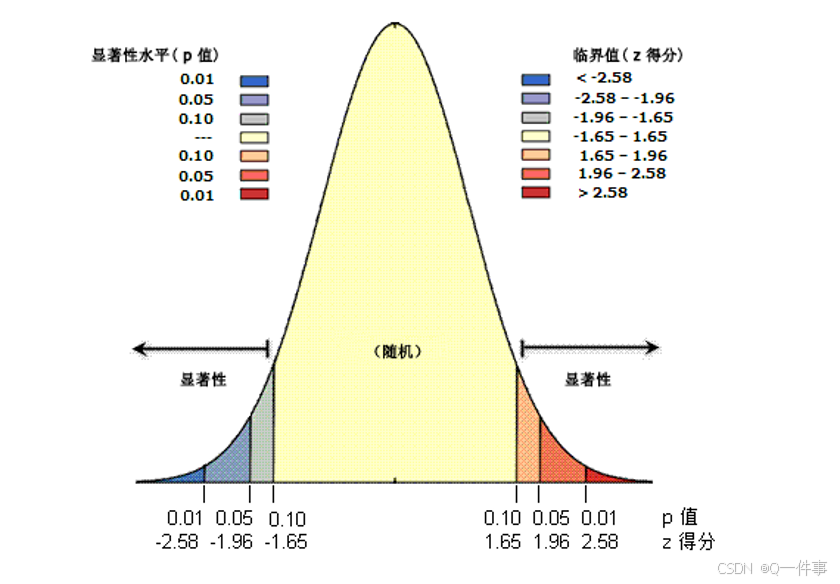
pnorm(2.58)# 这块是计算的累积概率密度的情况。
pnorm(2.58) # 这块在GIS中对应的是Z值
# 设置随机种子
set.seed(123)
# 生成正态分布数据
mean <- 0
sd <- 1
data <- rnorm(1000, mean, sd)
mean2 <- 0
sd2 <- 2
# 绘制直方图
hist(data, breaks=30, probability=TRUE, main="RNORM", xlab="VALUE", col="lightblue")
# 添加正态分布曲线
curve(dnorm(x, mean, sd), add=TRUE, col="red", lwd=2)
curve(dnorm(x, mean2, sd2), add=TRUE, col="blue", lwd=2)
# 标注均值和标准差
abline(v=mean, col="blue", lwd=2, lty=2)
text(mean, 0.3, paste("EX =", mean), pos=4)
text(mean + sd, 0.25, paste("VAR =", sd), pos=4)
正态总结:
标准差越小,实施上,更容易拒绝原假设,从而得到想要的结果。(如果想要得到小p值则需要,在均值不变的情况下,需要控制标准差最小。)数量越多标准差越小??这个还需要证明。

整体
中心极限定律:把所有分布的结果的平均值计算出来,整体结果是正态分布。平均值永远是正态分布。正态性和每次所选的数量有关。
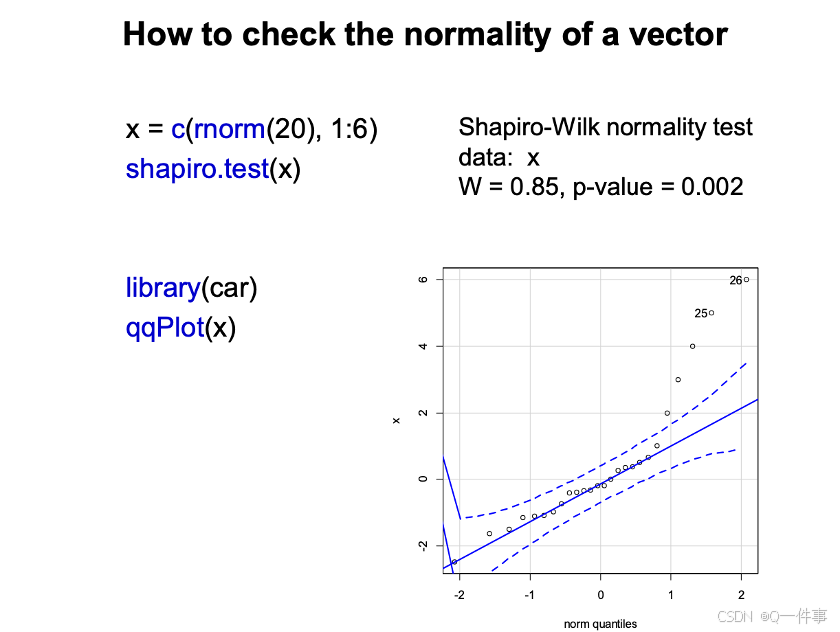
判断数据是否正态
1 方法一
一个是p值
x = c(rnorm(20), 1:6)
shapiro.test(x)
library(car)
qqPlot(x)
2 方法二
与均值相关,另一个就是plot,图形的方式
3.卡方分布
将正态分布进行平方事实上就是卡方分布。

卡方分布的情况。
plot(dchisq(seq(0.1, 10, by=0.1), df = 1), type='l',
xlab = 'x', xlim = c(0,10))
卡方分布的自由度越大,其越平稳。
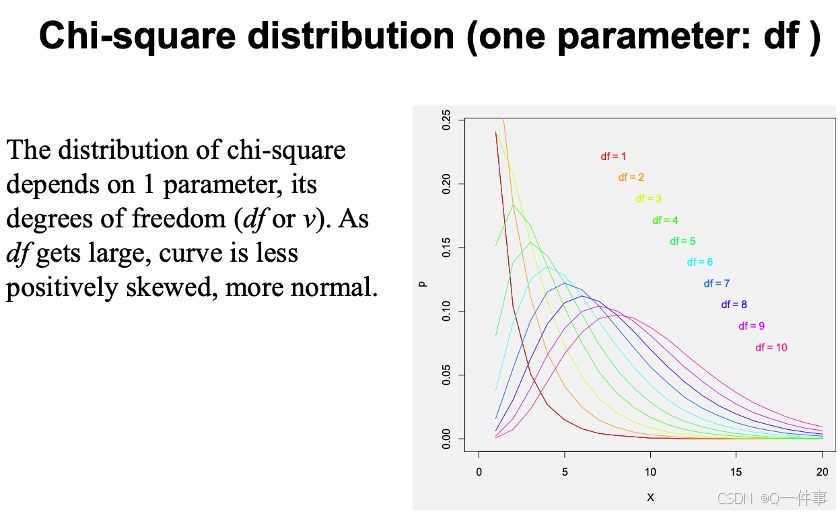
卡方分布有一个自由度,自由度可以根据数据的加和来进行分析。下面是卡方分布的方差。

4 F分布
F分布是通过比值来计算分布的情况。

卡方分布的一些统计数。

组间分布和组内分布,一个是分子的自由度和一个分子
mode 众数
coefficient of 变异系数(标准差除以平均值)
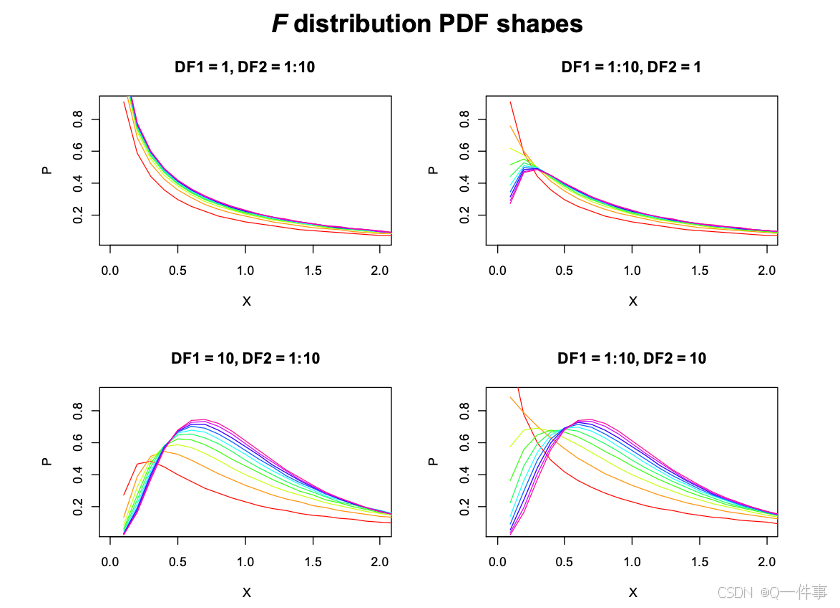
X = seq(0.1, 3, length=30); Y = df(X, 1,1)
par(mfrow=c(2,2))
plot(X, Y, type='n', xlab = 'X', ylab = 'P', xlim=c(0,2), main="DF1=1, DF2=1:10")
for (i in 1:10) lines(X, df(X, 1, i), col=rainbow(10)[i])
plot(X, Y, type='n', xlab = 'X', ylab = 'P', xlim=c(0,2), main="DF1=1:10, DF2=1")
for (i in 1:10) lines(X, df(X, i, 1), col=rainbow(10)[i])
plot(X, Y, type='n', xlab = 'X', ylab = 'P', xlim=c(0,2), main="DF1=10, DF2=1:10")
for (i in 1:10) lines(X, df(X, 10, i), col=rainbow(10)[i])
plot(X, Y, type='n', xlab = 'X', ylab = 'P', xlim=c(0,2), main="DF1=1:10, DF2=10")
for (i in 1:10) lines(X, df(X, i, 10), col=rainbow(10)[i])
5 指数分布
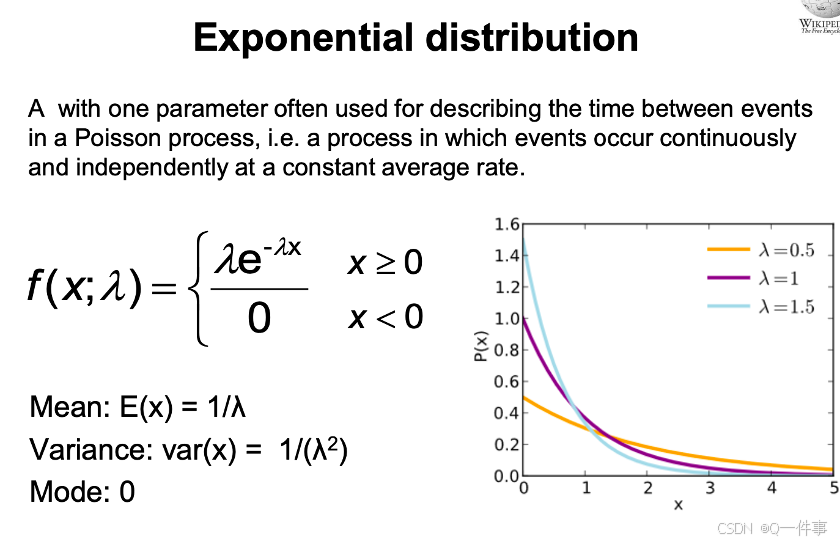
6 gamma分布

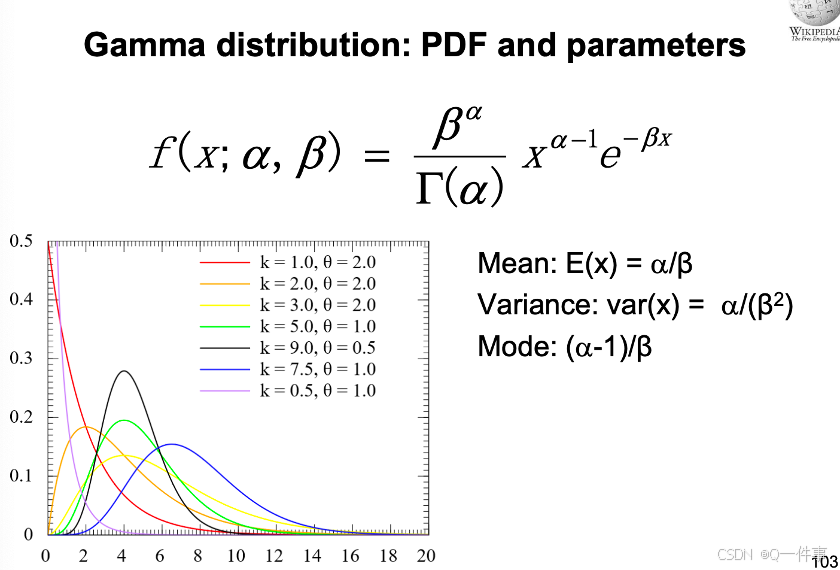
7 Weibull 分布
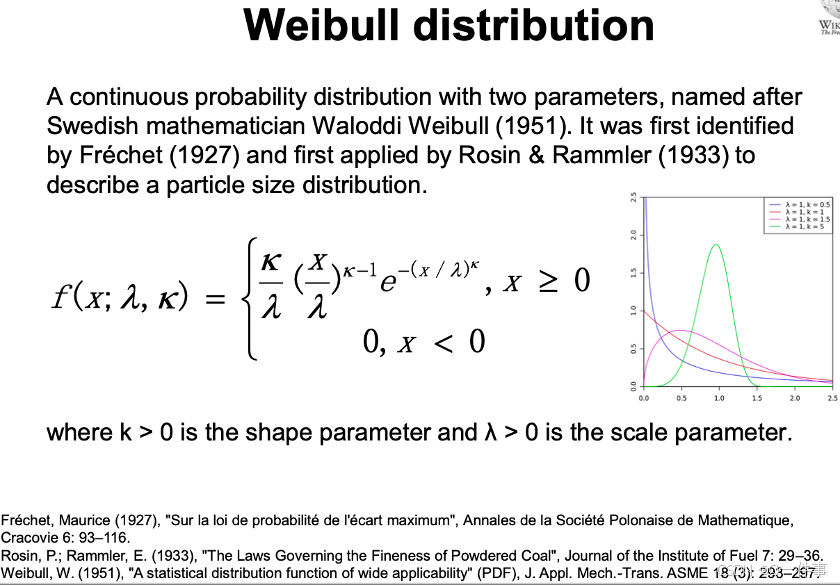
练习
obs = c(7,5,6,6,7,5,3,4,5,8,2,4,5,6,7,6,4,5,9,3,6,4)
hist(obs, freq = F)
mean = mean(obs)
SD = sd(obs)
x = seq(min(obs), max(obs), by = .1)
norm = dnorm(x, mean = mean, sd = SD)
lines(x, norm, type = 'l', col = 'red')
abline(v=c(qnorm(.025, mean, SD), qnorm(.975, mean, SD)), col = 'brown')
abline(v=c(mean - 2*SD, mean + 2*SD), col = 'blue')
x = rnorm(100)
mean(x)
sd(x)
var(x)
min(x)
max(x)
median(x)
range(x)
quantile(x)
summary(x)



















 1770
1770

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











