






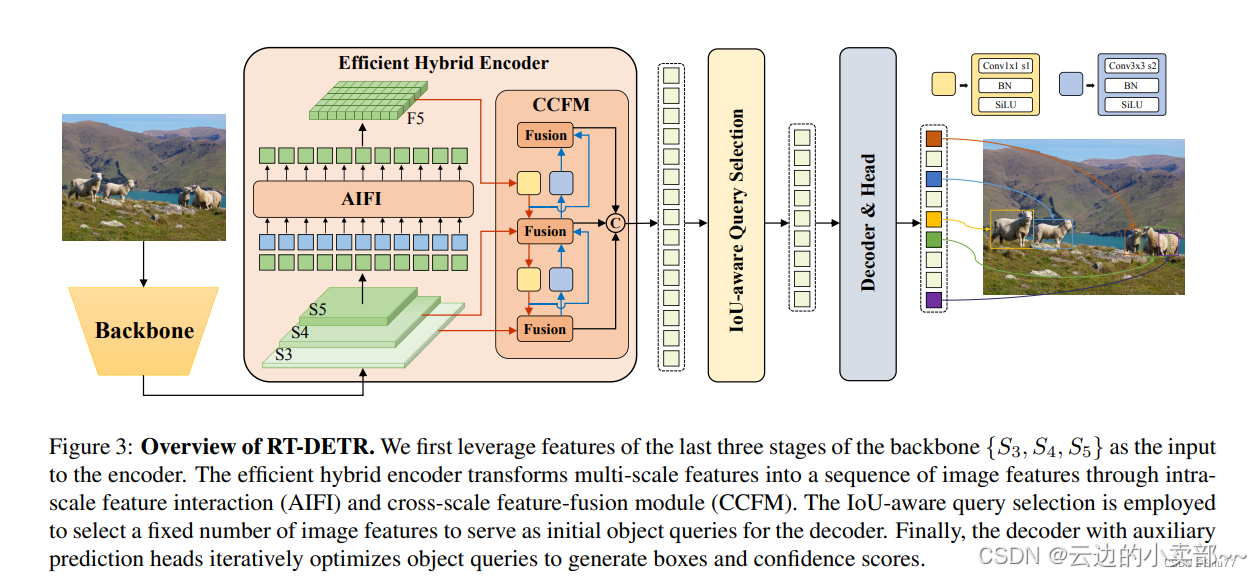
还是那张图,我们学习了Backbone后,接下来学习AIFI(Intra-scale feature interaction)部分是干什么的-----单尺度内的特征交互。简而言之就是如图。输入为S5,输出为F5。
首先我们来看模型的配置文件
nc: 80 # number of classes
scales: # model compound scaling constants, i.e. 'model=yolov8n-cls.yaml' will call yolov8-cls.yaml with scale 'n'
# [depth, width, max_channels]
l: [1.00, 1.00, 1024]
backbone:
# [from, repeats, module, args]
- [-1, 1, ConvNormLayer, [32, 3, 2, None, False, 'relu']] # 0-P1/2
- [-1, 1, ConvNormLayer, [32, 3, 1, None, False, 'relu']] # 1
- [-1, 1, ConvNormLayer, [64, 3, 1, None, False, 'relu']] # 2
- [-1, 1, nn.MaxPool2d, [3, 2, 1]] # 3-P2/4
# [ch_out, block_type, block_nums, stage_num, act, variant]
- [-1, 1, Blocks, [64, BasicBlock, 2, 2, 'relu']] # 4
- [-1, 1, Blocks, [128, BasicBlock, 2, 3, 'relu']] # 5-P3/8
- [-1, 1, Blocks, [256, BasicBlock, 2, 4, 'relu']] # 6-P4/16
- [-1, 1, Blocks, [512, BasicBlock, 2, 5, 'relu']] # 7-P5/32
head:
- [-1, 1, Conv, [256, 1, 1, None, 1, 1, False]] # 8 input_proj.2
- [-1, 1, AIFI, [1024, 8]] # 9
- [-1, 1, Conv, [256, 1, 1]] # 10, Y5, lateral_convs.0
- [-1, 1, nn.Upsample, [None, 2, 'nearest']] # 11
- [6, 1, Conv, [256, 1, 1, None, 1, 1, False]] # 12 input_proj.1
- [[-2, -1], 1, Concat, [1]] # 13
- [-1, 3, RepC3, [256, 0.5]] # 14, fpn_blocks.0
- [-1, 1, Conv, [256, 1, 1]] # 15, Y4, lateral_convs.1
- [-1, 1, nn.Upsample, [None, 2, 'nearest']] # 16
- [5, 1, Conv, [256, 1, 1, None, 1, 1, False]] # 17 input_proj.0
- [[-2, -1], 1, Concat, [1]] # 18 cat backbone P4
- [-1, 3, RepC3, [256, 0.5]] # X3 (19), fpn_blocks.1
- [-1, 1, Conv, [256, 3, 2]] # 20, downsample_convs.0
- [[-1, 15], 1, Concat, [1]] # 21 cat Y4
- [-1, 3, RepC3, [256, 0.5]] # F4 (22), pan_blocks.0
- [-1, 1, Conv, [256, 3, 2]] # 23, downsample_convs.1
- [[-1, 10], 1, Concat, [1]] # 24 cat Y5
- [-1, 3, RepC3, [256, 0.5]] # F5 (25), pan_blocks.1
- [[19, 22, 25], 1, RTDETRDecoder, [nc, 256, 300, 4, 8, 3]] # Detect(P3, P4, P5)
这次我们就来学习有关AIFI的这部分
- [-1, 1, Conv, [256, 1, 1, None, 1, 1, False]] # 8 input_proj.2
- [-1, 1, AIFI, [1024, 8]] # 9
- [-1, 1, Conv, [256, 1, 1]] # 10, Y5, lateral_convs.0这里的第一行代码很显然是一个卷积,但是我们在Backbone中也涉及到卷积操作,名字(ConvNormLayer)和这个(Conv)不一样 。所以首先学习一下,这两个有什么区别:
Backbone中卷积操作ConvNormLayer和head中卷积操作Conv的区别
先分别展示他们两个的源代码
ConvNormLayer源代码
class ConvNormLayer(nn.Module):
def __init__(self, ch_in, ch_out, kernel_size, stride, padding=None, bias=False, act=None):
super().__init__()
self.conv = nn.Conv2d(
ch_in,
ch_out,
kernel_size,
stride,
padding=(kernel_size-1)//2 if padding is None else padding,
bias=bias)
self.norm = nn.BatchNorm2d(ch_out)
self.act = nn.Identity() if act is None else get_activation(act)
def forward(self, x):
return self.act(self.norm(self.conv(x)))
def forward_fuse(self, x):
"""Perform transposed convolution of 2D data."""
return self.act(self.conv(x))Conv源代码
class Conv(nn.Module):
"""Standard convolution with args(ch_in, ch_out, kernel, stride, padding, groups, dilation, activation)."""
default_act = nn.SiLU() # default activation
def __init__(self, c1, c2, k=1, s=1, p=None, g=1, d=1, act=True):
"""Initialize Conv layer with given arguments including activation."""
super().__init__()
self.conv = nn.Conv2d(c1, c2, k, s, autopad(k, p, d), groups=g, dilation=d, bias=False)
self.bn = nn.BatchNorm2d(c2)
self.act = self.default_act if act is True else act if isinstance(act, nn.Module) else nn.Identity()
def forward(self, x):
"""Apply convolution, batch normalization and activation to input tensor."""
return self.act(self.bn(self.conv(x)))
def forward_fuse(self, x):
"""Perform transposed convolution of 2D data."""
return self.act(self.conv(x))区别
首先第一个区别,卷积nn.Conv2d 中参数设置不一样
ConvNormLayer中的nn.Conv2d
self.conv = nn.Conv2d(
ch_in,
ch_out,
kernel_size,
stride,
padding=(kernel_size-1)//2 if padding is None else padding,
bias=bias)Conv中的nn.Conv2d
self.conv = nn.Conv2d(c1, c2, k, s, autopad(k, p, d), groups=g, dilation=d, bias=False),前4个参数是一样的,都是输入通道数(ConvNormLayer中的ch_in和Conv中的c1),输出通道数(ch_out和c2),卷积核(kernel_size和k),步长(stride和s)。从第5个参数就不一样了。先看ConvNormLayer中剩下的参数,padding和bias。就是设置了简单步长和偏置。Conv中的就更加复杂。
autopad(k, p, d):自动填充计算
-
根据卷积核大小
k、膨胀率d和用户指定的填充p,自动计算卷积层的填充值,确保输出尺寸与输入尺寸匹配(当stride=1时)。 -
当
p=None时,默认填充方式为 "SAME" 填充(保持输入输出尺寸一致)。
groups=g:分组卷积
-
将输入和输出的通道分成
g组,每组独立进行卷积操作。 -
优势:减少参数量和计算量,提升模型效率。常用于深度可分类卷积。
dilation=d:膨胀卷积
-
通过控制卷积核的膨胀率(空洞间隔),扩大感受野而不增加参数数量。
-
用于捕获大范围上下文信息(如焊接缺陷的全局分布)。
卷积核结构
-
膨胀率
d=1:普通卷积核(无间隔) -
膨胀率
d=2:卷积核元素间隔1个像素(感受野等效于k + (k-1)*(d-1))
示例
-
卷积核
k=3,膨胀率d=2:-
实际覆盖区域:
3x3→ 等效5x5的感受野(但仅用9个参数)。
-
像素间隔

区别二:
激活函数的配置
先看 ConvNormLayer的
self.act = nn.Identity() if act is None else get_activation(act) 默认无激活(act=None 时使用 nn.Identity),需手动指定激活函数
再看Conv的
default_act = nn.SiLU() # default activation
self.act = self.default_act if act is True else act if isinstance(act, nn.Module) else nn.Identity()默认使用 SiLU 激活(即 Swish 激活),兼顾 ReLU 的非线性和 Sigmoid 的平滑性
总结:
-
Conv:
当需要灵活配置膨胀/分组卷积,或希望利用 SiLU 激活函数增强非线性表达能力时(尤其适合检测小目标)。 -
ConvNormLayer:
在基础特征提取层(如主干网络前半部分),追求计算效率且无需复杂卷积配置时。
现在我们来看
配置文件第一行
- [-1, 1, Conv, [256, 1, 1, None, 1, 1, False]] # 8 input_proj.2
回忆一下,最开始我们的输入图片为3*640*640,经过Backbone后,最后一层图片输出为512x20x20。
对应参数解析:
-
输出通道数 c2=256
-
卷积核大小 k=1×1k=1×1
-
步长 s=1s=1
-
填充 p=Nonep=None(自动计算为 00)
-
分组数 g=1g=1
-
膨胀率 d=1d=1
-
激活函数 act=False
输出计算
-
空间尺寸
Hout=[Hin+2p−d×(k−1)−1]/s+1=20
输入尺寸为 Hin×Win=20×20,卷积核为 1×1,步长 s=1,填充 p=0,膨胀率 d=1。
输出尺寸公式:同理 Wout=20。
-
通道数
输入通道数 c1=512 → 输出通道数 c2=256。
作用总结
-
通道降维:将通道数从 512 压缩至 256,减少后续计算量。
-
特征融合:通过 1×1卷积实现跨通道信息融合,增强特征表达能力。
-
保持分辨率:不改变空间尺寸(无下采样),保留缺陷定位精度。
-
归一化:通过内置的
BatchNorm2d稳定训练过程。
配置文件第二行
- [-1, 1, AIFI, [1024, 8]] # 9- 输入通道数为 1024。
- 多头注意力机制中的头数为 8
接下来看AIFI的源码
class AIFI(TransformerEncoderLayer):
"""Defines the AIFI transformer layer."""
def __init__(self, c1, cm=2048, num_heads=8, dropout=0, act=nn.GELU(), normalize_before=False):
"""Initialize the AIFI instance with specified parameters."""
super().__init__(c1, cm, num_heads, dropout, act, normalize_before)
def forward(self, x):
"""Forward pass for the AIFI transformer layer."""
c, h, w = x.shape[1:]
pos_embed = self.build_2d_sincos_position_embedding(w, h, c)
# Flatten [B, C, H, W] to [B, HxW, C]
x = super().forward(x.flatten(2).permute(0, 2, 1), pos=pos_embed.to(device=x.device, dtype=x.dtype))
return x.permute(0, 2, 1).view([-1, c, h, w]).contiguous()
@staticmethod
def build_2d_sincos_position_embedding(w, h, embed_dim=256, temperature=10000.0):
"""Builds 2D sine-cosine position embedding."""
grid_w = torch.arange(int(w), dtype=torch.float32)
grid_h = torch.arange(int(h), dtype=torch.float32)
grid_w, grid_h = torch.meshgrid(grid_w, grid_h, indexing='ij')
assert embed_dim % 4 == 0, \
'Embed dimension must be divisible by 4 for 2D sin-cos position embedding'
pos_dim = embed_dim // 4
omega = torch.arange(pos_dim, dtype=torch.float32) / pos_dim
omega = 1. / (temperature ** omega)
out_w = grid_w.flatten()[..., None] @ omega[None]
out_h = grid_h.flatten()[..., None] @ omega[None]
return torch.cat([torch.sin(out_w), torch.cos(out_w), torch.sin(out_h), torch.cos(out_h)], 1)[None]初始化
c1: 输入通道数。cm: 中间特征维度,默认为 2048。num_heads: 多头注意力机制中的头数,默认为 8。dropout: dropout 概率,默认为 0。act: 激活函数,默认为 GELU。normalize_before: 是否在注意力机制之前进行归一化,默认为 False。
super().__init__(c1, cm, num_heads, dropout, act, normalize_before) 调用基类 TransformerEncoderLayer 的初始化方法。
前向传播
- 获取形状信息:
c, h, w = x.shape[1:]提取输入特征图的通道数、高度和宽度。x.shape将返回一个包含四个元素的元组(B, C, H, W)。x.shape[1:]会跳过第一个元素(即跳过批量大小B),取后面的部分,即(C, H, W)。c, h, w = x.shape[1:]是一种 Python 的多变量赋值(解包)语法,它将元组(C, H, W)解包为三个独立的变量c、h和w,分别表示通道数、图像高度和图像宽度。
- 生成位置嵌入:
pos_embed = self.build_2d_sincos_position_embedding(w, h, c)生成 2D 正弦-余弦位置嵌入。
- 特征处理:
x.flatten(2).permute(0, 2, 1)将输入特征从[B, C, H, W]变换为[B, H*W, C],以适应 transformer 输入格式。x.flatten(2)会将张量x从第 2 个维度开始展平(flatten),这意味着它会将H和W维度展平为一个维度。展平后的张量形状会变成[B, C, H*W]。例如,如果
x的形状是[B, C, H, W]:x.flatten(2)的形状会变成[B, C, H*W]。permute方法x.flatten(2).permute(0, 2, 1)会对展平后的张量进行维度重排。permute方法会改变张量的维度顺序。在这个例子中,permute(0, 2, 1)表示将第 0 个维度保持不变,将第 2 个维度移到第 1 个位置,将第 1 个维度移到第 2 个位置。具体来说:0代表批量大小B。2代表展平后的维度H*W。1代表通道数C,因此,x.flatten(2).permute(0, 2, 1)会将形状从[B, C, H*W]变成[B, H*W, C]super().forward()调用基类的前向传播方法,传入处理后的特征和位置嵌入。x.permute(0, 2, 1).view([-1, c, h, w]).contiguous()将输出特征重整为[B, C, H, W]形状。x.permute(0, 2, 1)会改变张量的维度顺序。permute(0, 2, 1)表示将第 0 个维度保持不变,将第 2 个维度移到第 1 个位置,将第 1 个维度移到第 2 个位置。具体来说:
0代表批量大小B。2代表特征维度C。1代表序列长度N。因此,x.permute(0, 2, 1)会将形状从[B, N, C]变成[B, C, N]。view方法view方法用于重新整形张量。x.permute(0, 2, 1).view([-1, c, h, w])将张量重新整形为[B, C, H, W]。假设:B是批量大小。C是通道数。H和W是图像的高度和宽度,且N = H * W。那么x.permute(0, 2, 1)的形状是[B, C, N],即[B, C, H * W]。view([-1, c, h, w])将其重新整形为[B, C, H, W]。其中-1表示自动推断出批量大小B。contiguous方法contiguous方法用于确保张量在内存中的存储是连续的。经过permute和view操作后,张量在内存中的存储可能不再是连续的,contiguous会创建一个新的连续张量。
2D 正弦-余弦位置嵌入
- 生成网格:
grid_w和grid_h分别生成宽度和高度方向的网格坐标。torch.arangetorch.arange是 PyTorch 中生成序列数据的方法。其常见用法是torch.arange(start, end, step),其中:start是序列的起始值(默认为0)。end是序列的终止值(不包含此值)。step是序列中相邻值之间的间隔(默认为1)。在这行代码中,只用了一个参数end,默认为从0开始,到int(w)结束(不包括int(w)本身),步长为1。3.dtype=torch.float32,dtype参数指定生成的张量的数据类型。在这里,dtype=torch.float32表示生成的张量中的元素将是 32 位浮点数。grid_w, grid_h = torch.meshgrid(grid_w, grid_h, indexing='ij')创建 2D 网格。torch.meshgrid是 PyTorch 中用于生成网格坐标的方法。其常见用法是torch.meshgrid(tensor1, tensor2, ..., indexing='xy' or 'ij')。它接受多个一维张量,并返回相应的多维网格张量。'ij':基于矩阵索引顺序,返回的网格是(i, j)形式,即网格的第一个维度是 i 方向,第二个维度是 j 方向。
- 计算 Omega:
-
检查
embed_dim是否可以被 4 整除assert embed_dim % 4 == 0为了进行2D正弦-余弦位置嵌入,嵌入维度
embed_dim必须是 4 的倍数。这个检查是为了确保后续的计算能够正确进行。pos_dim = embed_dim // 4把
embed_dim除以 4 得到pos_dim。这是因为对于 2D 正弦-余弦位置嵌入,每个维度会使用 4 个值来进行编码(sin 和 cos 各两个方向)。 omega = torch.arange(pos_dim, dtype=torch.float32) / pos_dim生成omega值。这里使用torch.arange(pos_dim, dtype=torch.float32)生成一个从0到pos_dim-1的一维张量。然后将这个张量除以pos_dim,以得到一个在[0, 1)范围内的值序列。omega = 1. / (temperature ** omega)通过温度参数进行缩放。temperature这里通常是一个常数,用于控制位置编码的尺度。通常在位置编码中,temperature被设定为一个较大的值,如10000。这意味着omega序列中的每个值都是一个倒数,基于指数增长的方式。-
总结
omega是一个包含不同频率倒数的序列,这些频率用于生成 2D 正弦-余弦位置编码的频率成分。通过这些频率,位置编码能够有效地表示输入序列中每个位置的信息,并帮助模型捕捉序列中位置间的相对关系。
-
- 计算正弦和余弦嵌入:
out_w和out_h分别计算宽度和高度方向的正弦和余弦值。torch.cat([...], 1)[None]将所有嵌入值合并为[1, H*W, embed_dim]形状。@是矩阵乘法运算符。这里我们进行的是矩阵乘法,将两个二维张量相乘:grid_w.flatten()[..., None]的形状为(H * W, 1)。omega[None]的形状为(1, pos_dim)。矩阵乘法的结果out_w的形状为(H * W, pos_dim),因为(H * W, 1) @ (1, pos_dim) = (H * W, pos_dim)。同样,out_h的形状也是(H * W, pos_dim)。用途和意义out_w和out_h是位置编码的一部分,它们表示网格中每个位置在宽度和高度方向上的编码。grid_w.flatten()[..., None] @ omega[None]计算得到的out_w表示网格中所有位置的宽度编码。grid_h.flatten()[..., None] @ omega[None]计算得到的out_h表示网格中所有位置的高度编码。
输出为1024x20 x 20
配置文件第三行
- [-1, 1, Conv, [256, 1, 1]]通过一个1*1的卷积,输出为256x20x20
AIFI 作用总结(作用于P5(S5)层,生成F5层)
-
Transformer 编码层: AIFI 类继承自 TransformerEncoderLayer,意味着它主要功能是实现一种基于 Transformer 的编码层。
-
位置嵌入: 在前向传播过程中,AIFI 类生成二维正弦-余弦位置嵌入(2D Sin-Cos Positional Embedding),这在处理图像数据时很常见,因为图像的空间信息对模型理解非常重要。
-
特征处理:
- 输入特征格式变换:输入特征的形状为
[B, C, H, W](批量大小 B,通道数 C,高度 H,宽度 W),在处理前被展平并转置为[B, H*W, C]的格式,这样更适合 Transformer 模型处理。 - 位置嵌入添加:位置嵌入被添加到特征中,以提供位置信息。
- Transformer 处理:经过 Transformer 编码层处理后,特征被转置回原始格式
[B, C, H, W]。
- 输入特征格式变换:输入特征的形状为

















 1141
1141

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









