






本人正在学习RT-DETR中,将学习过程记录下来,如有错误,请指正!通融通融
本博客以RT-DETR的r18为基准模型学习。
最开始学习要知道整个RT-DETR的大致结构,如图。backbone位于最前面,骨干网络(Backbone)用于从输入图像中提取特征。它的任务是通过一系列卷积操作和其他处理方法,将输入的原始图像转换为一个高维的特征表示。P1, P2, P3, P4, P5是不同网络层的输出特征图的尺寸(通常是下采样的结果),这些代表了卷积神经网络(CNN)中特征图的不同层级。这里图片的S3,S4,S5就是指的P3,P4,P5。
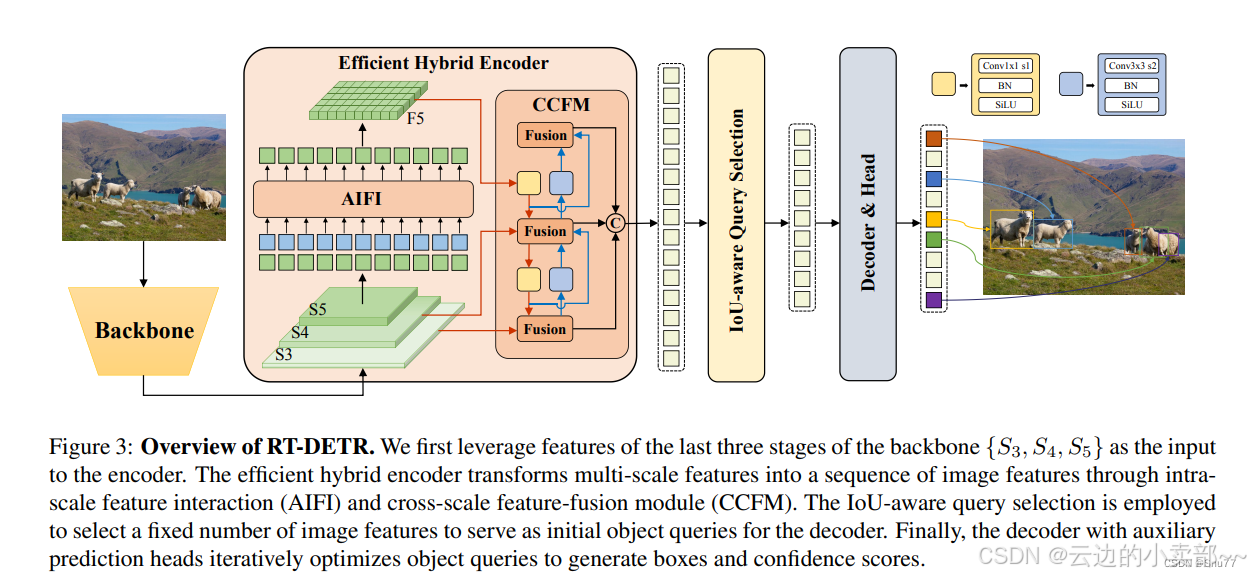
开始学习
首先来看配置文件(yaml文件)中backbone的代码
backbone:
# [from, repeats, module, args]
- [-1, 1, ConvNormLayer, [32, 3, 2, None, False, 'relu']] # 0-P1/2
- [-1, 1, ConvNormLayer, [32, 3, 1, None, False, 'relu']] # 1
- [-1, 1, ConvNormLayer, [64, 3, 1, None, False, 'relu']] # 2
- [-1, 1, nn.MaxPool2d, [3, 2, 1]] # 3-P2/4
# [ch_out, block_type, block_nums, stage_num, act, variant]
- [-1, 1, Blocks, [64, BasicBlock, 2, 2, 'relu']] # 4
- [-1, 1, Blocks, [128, BasicBlock, 2, 3, 'relu']] # 5-P3/8
- [-1, 1, Blocks, [256, BasicBlock, 2, 4, 'relu']] # 6-P4/16
- [-1, 1, Blocks, [512, BasicBlock, 2, 5, 'relu']] # 7-P5/32第一行代码(配置文件第0层)
- [-1, 1, ConvNormLayer, [32, 3, 2, None, False, 'relu']] # 0-P1/2这个配置代表了一层的设置,它有四个元素:
from:-1表示输入来自于上一层的输出。对于第一行的配置(即-1作为输入),它通常表示输入来自于“最初的输入图像”或者说是“图像输入层”。repeats:1表示该层只会被执行一次。如果为大于 1 的值,则该层会重复多次。module:ConvNormLayer表示这一层的模块类型是ConvNormLayer,即卷积 + 批归一化 + 激活函数的层。(后面介绍)args:这个部分是一个列表,包含了ConvNormLayer所需要的参数:32:输出通道数(ch_out)。3:卷积核的大小(kernel_size)。2:卷积步长(stride)。步长就是卷积的时候滑动窗口一次滑动几格,这里就是一次滑动两格。如图1,对一个5*5的图像做卷积,卷积核是3*3,步长是2,就可以得到一个2*2的特征输出图像。None:填充方式(padding),默认为None,即会自动根据卷积核大小计算填充。有时候需要在原图像周围加一圈或者几圈0或1,来使原图像更大。如图2False:是否使用偏置(bias),这里设置为False。偏置(bias) 是一种额外的参数,它的作用是为每个神经元(或者每个神经层的输出)提供一个额外的自由度。也就是y=wx+b,中的b。'relu':激活函数(act),这里使用 ReLU 激活函数。
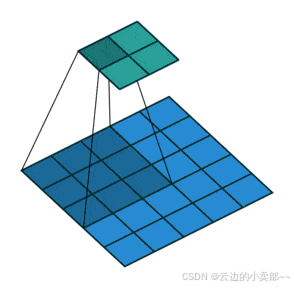
图1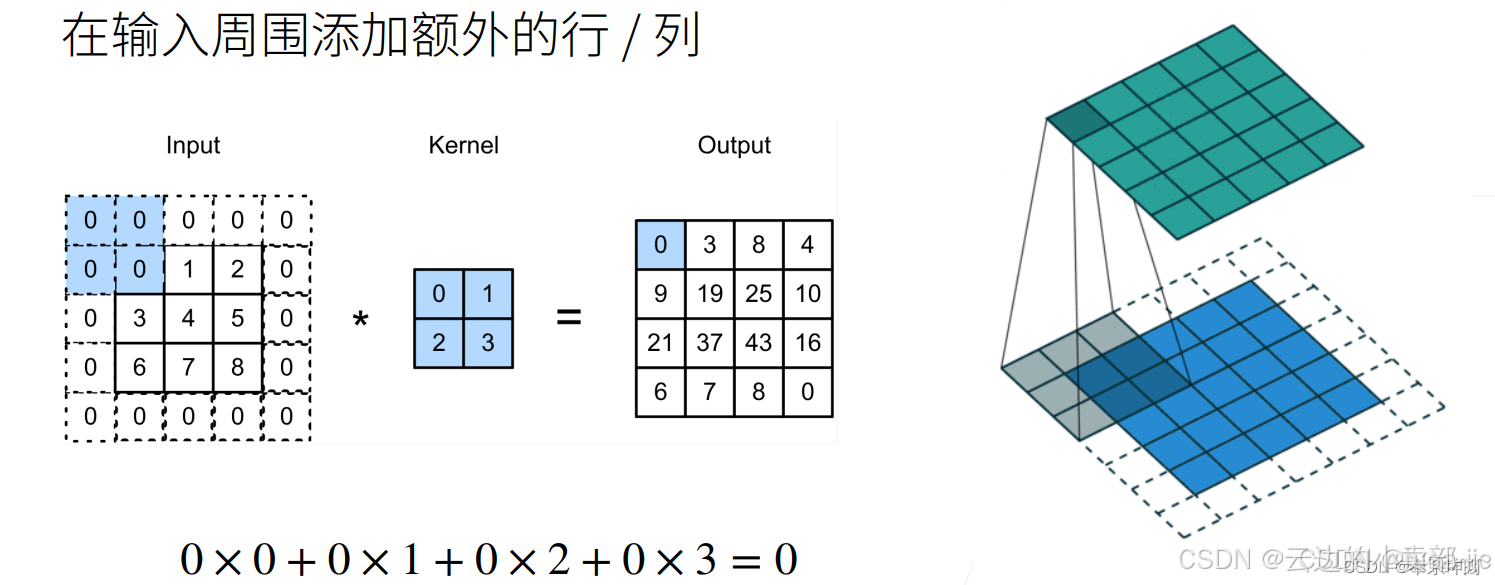
图2
默认输入图像是640*640,3通道的图像
输入图片解析:
- 输入图片为 640x640 的 3 通道图像,即每张图片的尺寸是 3
x640x640。
计算卷积后的输出尺寸:
给定输入图像的尺寸为 640x640,卷积层的参数为:
kernel_size = 3stride = 2padding = None
在这种配置下,卷积的输出尺寸可以使用以下公式来计算:
Output Height=(StrideInput Height+2×Padding−Kernel Size)/stride+1
Output Width=(StrideInput Width+2×Padding−Kernel Size)/stride+1
将 640x640 输入和卷积层的参数代入公式:
Output Height=(640+2×0−3)/2+1=637/2+1=318.5+1=319.5
Output Width=(640+2×0−3)/2+1=637/2+1=318.5+1=319.5
因此,卷积操作之后的输出尺寸将是 32x320x320因为结果是 319.5,所以通常 取整 变成 320,即高度和宽度都缩小了一半,输出通道数变为 32。这就是P1/2。P1/2: P1层的特征图的尺寸是输入图像尺寸的一半,代表网络中的第一个下采样层。
结果:
- 输入图像大小:3
x640x640 - 卷积层输出大小:32
x320x320
第二行(配置文件第1层)
- [-1, 1, ConvNormLayer, [32, 3, 1, None, False, 'relu']] # 1这一层配置实际上是在 第一层卷积层之后添加的另一层卷积操作。它的主要作用是继续处理前一层卷积后的特征图,进一步提取特征。和第一行唯一的区别就是步长,从2变成了1. 意味着卷积操作不会减少特征图的尺寸(宽度和高度保持不变)。
因此:
- 输出通道数:这一层的卷积核数量是
32,因此输出的通道数是32。
第1层卷积的输出尺寸:32x320x320
第三行(配置文件第2层)
- [-1, 1, ConvNormLayer, [64, 3, 1, None, False, 'relu']] # 2同样是 backbone 中的一个卷积层,只不过这次它的输出通道数变成了 64。
- 64 个 3x3 的卷积核,用于提取更多的特征。
- 步长为 1,表示不会改变特征图的空间尺寸,保持图像的宽度和高度不变。
- 第二层卷积的输出尺寸:
64x320x320
为什么增加通道数?
在深度神经网络中,通常会在深层次逐渐增加通道数(即卷积核的数量)。这样做的目的是在特征图的空间维度(宽度和高度)不变的情况下,增加网络可以捕捉到的特征的复杂性和多样性。通过增加通道数,网络能够学习更多的高维特征,从而提高最终的模型表现。
第四行(配置文件第3层)
- [-1, 1, nn.MaxPool2d, [3, 2, 1]] # 3-P2/4nn.MaxPool2d:这是一个 2D 最大池化层,它将对输入图像进行池化操作,从而减少图像的空间维度(宽度和高度),通常用于特征压缩或降维。- 参数
[3, 2, 1]表示:3:池化核的大小,即 3x3 的矩阵用于池化操作。2:步长(stride),池化核每次滑动的步长为 2。1:填充(padding),在池化时对输入的边缘进行填充,确保池化后的输出尺寸。
池化操作尺寸计算
对于 MaxPool2d 操作,输出的高度和宽度可以通过以下公式计算:
输出尺寸=(步长输入尺寸+2×填充−池化核尺寸)/步长+1
在这里:
- 输入尺寸:
320(高度和宽度相同,所以这里就用316计算)。 - 池化核尺寸:
3 - 步长:
2 - 填充:
1
计算过程
计算输出高度和宽度:
输出高度/宽度=(320+2×1−3)/2+1
=(320+2−3)/2+1
=319/2+1
=159+1=160
所以,输出高度和宽度 都是 160。
输出通道数:
池化层不会改变通道数,所以输出的通道数仍然是 64(输入的通道数)。
结果
经过 MaxPool2d 层后,输入尺寸 316x316x64 变为输出尺寸:
- 输出尺寸:
64x160x160(P2/4: P2层的特征图的尺寸是输入图像尺寸的1/4)
第五行代码(配置文件第4层)
- [-1, 1, Blocks, [64, BasicBlock, 2, 2, 'relu']][-1, 1]:表示当前层输入来自上一层,并且重复一次。Blocks:表示一个包含多个BasicBlock的模块。在这里,Blocks模块会包含若干个BasicBlock。[64, BasicBlock, 2, 2, 'relu']:64:表示每个BasicBlock的输出通道数。BasicBlock:模块类型,意味着每个块是一个BasicBlock。2:表示在当前Blocks模块中有 2 个BasicBlock。2:阶段编号,还是P2层的大小,没有变化,后面几行的代码,这个位置分别是3,4,5,就代表P3,P4,P5。'relu':表示使用ReLU激活函数。
先来看Blocks的代码
class Blocks(nn.Module):
def __init__(self, ch_in, ch_out, block, count, stage_num, act='relu', input_resolution=None, sr_ratio=None, kernel_size=None, kan_name=None, variant='d'):
super().__init__()
self.blocks = nn.ModuleList()
for i in range(count):
if input_resolution is not None and sr_ratio is not None:
self.blocks.append(
block(
ch_in,
ch_out,
stride=2 if i == 0 and stage_num != 2 else 1,
shortcut=False if i == 0 else True,
variant=variant,
act=act,
input_resolution=input_resolution,
sr_ratio=sr_ratio)
)
elif kernel_size is not None:
self.blocks.append(
block(
ch_in,
ch_out,
stride=2 if i == 0 and stage_num != 2 else 1,
shortcut=False if i == 0 else True,
variant=variant,
act=act,
kernel_size=kernel_size)
)
elif kan_name is not None:
self.blocks.append(
block(
ch_in,
ch_out,
stride=2 if i == 0 and stage_num != 2 else 1,
shortcut=False if i == 0 else True,
variant=variant,
act=act,
kan_name=kan_name)
)
else:
self.blocks.append(
block(
ch_in,
ch_out,
stride=2 if i == 0 and stage_num != 2 else 1,
shortcut=False if i == 0 else True,
variant=variant,
act=act)
)
if i == 0:
ch_in = ch_out * block.expansion
def forward(self, x):
out = x
for block in self.blocks:
out = block(out)
return out__init__ 方法
- 这是
Blocks类的构造函数,接收多个参数来定义块的特性:ch_in: 输入通道数。ch_out: 输出通道数。block: 使用的块类型(例如卷积块、残差块等)。count: 该层中块的数量。stage_num: 网络的阶段,用于决定第一个块的步幅。act: 激活函数(默认为'relu')。input_resolution,sr_ratio,kernel_size,kan_name: 用于定制块的附加参数(根据块的要求有条件地使用)。没有传入input_resolution、sr_ratio、kernel_size或kan_name,它们的值默认是None,并未在构造过程中使用variant: 用于定制化的变种参数(默认为'd')。
self.blocks = nn.ModuleList()- 这行代码初始化了一个空的块列表(
nn.ModuleList())。这个列表用来存储每个块。ModuleList是 PyTorch 中用于注册子模块的容器,这样每个块就可以被包含在计算图中,并在训练时进行优化。
for循环
- 这个循环会执行
count次,创建指定数量的块。
在循环内部:
-
每个块都是通过
block函数(可能是一个自定义的层,如卷积块、残差块等)创建的,传入的参数包括:ch_in、ch_out:输入和输出的通道数。stride:如果是第一个块且stage_num不是 2,则步幅为 2,否则为 1。shortcut:第一个块的shortcut设置为False,后续的块为True,以便使用残差连接。variant、act:激活函数和块的变种。input_resolution、sr_ratio、kernel_size或kan_name:根据条件提供的额外参数。这里没用
-
在添加第一个块后,输入通道
ch_in会被更新为ch_out * block.expansion,这是因为有些块(如残差块)可能会扩展通道数。
所以其实 Blocks 看起来很长,但是for循环中有用的只有
self.blocks.append(
block(
ch_in,
ch_out,
stride=2 if i == 0 and stage_num != 2 else 1,
shortcut=False if i == 0 else True,
variant=variant,
act=act)
)Blocks 初始化逻辑:
-
stride的赋值规则:
在Blocks的循环中,每个BasicBlock的stride由以下条件决定:stride=2 if i == 0 and stage_num != 2 else 1,- 第一个块(
i=0)且stage_num ≠ 2:stride=2(下采样)。 - 其他情况:
stride=1(保持分辨率)。
- 第一个块(
-
shortcut的赋值规则:shortcut=False if i == 0 else True,- 第一个块(
i=0):shortcut=False(需要调整通道或分辨率)。 - 后续块(
i>0):shortcut=True(直接使用输入作为shortcut)。
- 第一个块(
通道数更新
if i == 0:
ch_in = ch_out * block.expansion-
第一个块(
i=0)执行后,输入通道ch_in会被更新为ch_out * block.expansion(即ch_out * 1,因为BasicBlock.expansion = 1)。 -
后续块的输入通道与输出通道相同(
ch_in = ch_out),因此无需调整通道数,直接使用shortcut=True。
forward方法
- 这是
Blocks类的前向传播方法。它接收输入x,将其依次通过每个块,最终返回处理后的输出。 - 输入
x被传递给每个块,且每个块的输出都成为下一个块的输入。
接下来根据BasicBlock代码解释其作用
class BasicBlock(nn.Module):
expansion = 1
def __init__(self, ch_in, ch_out, stride, shortcut, act='relu', variant='d'):
super().__init__()
self.shortcut = shortcut
if not shortcut:
if variant == 'd' and stride == 2:
self.short = nn.Sequential(OrderedDict([
('pool', nn.AvgPool2d(2, 2, 0, ceil_mode=True)),
('conv', ConvNormLayer(ch_in, ch_out, 1, 1))
]))
else:
self.short = ConvNormLayer(ch_in, ch_out, 1, stride)
self.branch2a = ConvNormLayer(ch_in, ch_out, 3, stride, act=act)
self.branch2b = ConvNormLayer(ch_out, ch_out, 3, 1, act=None)
self.act = nn.Identity() if act is None else get_activation(act)
def forward(self, x):
out = self.branch2a(x)
out = self.branch2b(out)
if self.shortcut:
short = x
else:
short = self.short(x)
out = out + short
out = self.act(out)
return out
expansion: 这个变量用于确定BasicBlock最终输出的通道数与输入通道数之间的比例。在BasicBlock中,expansion被设置为1。__init__方法:初始化方法接收参数ch_in(输入通道数),ch_out(输出通道数),stride(步幅),shortcut(是否使用快捷连接),act(激活函数类型),variant(变体类型)。self.shortcut: 指示是否使用快捷连接。self.short: 如果不使用快捷连接,则创建一个short分支。- 变体
d且步幅为2时,short分支包括一个平均池化和一个ConvNormLayer卷积层。 - 否则,
short分支仅为一个ConvNormLayer卷积层。
- 变体
self.branch2a和self.branch2b: 定义了两层卷积层。branch2a使用传入的激活函数,branch2b没有激活函数。self.act: 激活函数,如果act为None,使用nn.Identity(),否则使用指定的激活函数。
forward方法:定义了数据在BasicBlock中的前向传播路径。out = self.branch2a(x):输入x通过第一个卷积层branch2a。out = self.branch2b(out):输出out通过第二个卷积层branch2b。short = x或short = self.short(x):如果使用快捷连接,则short为输入x。否则,short为通过self.short分支后的输出。out = out + short:将branch2b的输出与short相加,进行残差连接。out = self.act(out):通过激活函数。- 返回
out:返回结果。
先说明Blocks在BasicBlock中的作用,就是定义shortcut和stride的值
BasicBlock 中 shortcut 的 stride 值
-
当
shortcut=False时(仅在第一个块发生):self.short层的stride直接继承自Blocks传入的stride参数。- 具体值:
- 如果
stage_num ≠ 2:stride=2(下采样)。 - 如果
stage_num = 2:stride=1(保持分辨率)。
- 如果
-
当
shortcut=True时(后续块):
直接使用输入作为shortcut,不涉及stride操作。
所以当输入是158*158*64时
-
第一个
BasicBlock(i=0):stride:由于stage_num = 2,根据规则stride=1。shortcut:False(强制调整通道,即使输入输出通道相同)。- 操作:
self.branch2a和self.branch2b:3x3卷积,stride=1,分辨率保持 160x160。self.short:1x1卷积,stride=1,仅调整通道(输入输出均为64,实际无意义但代码仍执行)。
- 输出:64x158x158。
-
第二个
BasicBlock(i=1):stride:1。shortcut:True(输入输出通道相同,直接相加)。- 操作:3x3卷积,
stride=1,分辨率保持 160x160。 - 输出:64x160x160。
最终输出
- 尺寸:64x160x160(分辨率不变,通道数不变)。模块没有改变分辨率和通道数,但它通过增加网络深度、增强特征提取能力和引入残差连接,提高了模型的表现力和鲁棒性。这些模块在现代卷积神经网络(如 ResNet)中的应用已经证明了它们的有效性。
每个 BasicBlock 对输入数据进行两次卷积操作,并通过残差连接(shortcut connection)将原始输入添加到卷积输出中,最终通过激活函数。如果 stride 为 2 且 shortcut=False,则进行空间尺寸缩减。每个卷积操作的输出通道数由 ch_out 决定,空间尺寸根据卷积核和步幅决定。
第六行代码(配置文件第5层)
- [-1, 1, Blocks, [128, BasicBlock, 2, 3, 'relu']] # 5-P3/8参数解析
ch_out = 128:输出通道为128。count = 2:包含2个BasicBlock。stage_num = 3:阶段编号为3。
处理逻辑
-
第一个
BasicBlock(i=0):stride:由于stage_num ≠ 2,根据规则stride=2。shortcut:False(需要下采样并调整通道)。- 操作:
self.branch2a:3x3卷积,stride=2,输入 64x160x160 → 输出 128x80x80。self.branch2b:3x3卷积,stride=1,保持 128x80x80。self.short:若variant='d',使用AvgPool2d(2,2)+ 1x1卷积(stride=1),将输入 64x160x160 → 128x80x80。
- 输出:128x80x80(分辨率减半,通道数翻倍)。
-
第二个
BasicBlock(i=1):stride:1。shortcut:True(输入输出通道相同,直接相加)。- 操作:3x3卷积,
stride=1,分辨率保持 80x80。 - 输出:128x80x80。
最终输出
- 尺寸:128x80x80(标记为 P3/8,表示相对原图下采样 8 倍)。
第七行代码(配置文件第6层)
- [-1, 1, Blocks, [256, BasicBlock, 2, 4, 'relu']] # 6-P4/16参数解析
ch_out = 256:输出通道为256。count = 2:包含2个BasicBlock。stage_num = 4:阶段编号为4。
处理逻辑
-
第一个
BasicBlock(i=0):stride:由于stage_num ≠ 2,根据规则stride=2。shortcut:False(需要下采样并调整通道)。- 操作:
self.branch2a:3x3卷积,stride=2,输入 128x80x80 → 输出 256x40x40。self.branch2b:3x3卷积,stride=1,保持 256x40x40。self.short:若variant='d',使用AvgPool2d(2,2)+ 1x1卷积(stride=1),将输入 128x80x80 → 256x40x40。
- 输出:256x40x40(分辨率减半,通道数翻倍)。
-
第二个
BasicBlock(i=1):stride:1。shortcut:True(输入输出通道相同,直接相加)。- 操作:3x3卷积,
stride=1,分辨率保持 39x39。 - 输出:256x40x40。
最终输出
- 尺寸:256x40x40(标记为 P4/16,表示相对原图下采样 16 倍)。
第八行代码(配置文件第7层)
- [-1, 1, Blocks, [512, BasicBlock, 2, 5, 'relu']] # 7-P5/32参数解析
ch_out = 512:输出通道为512。count = 2:包含2个BasicBlock。stage_num = 5:阶段编号为5。
处理逻辑
-
第一个
BasicBlock(i=0):stride:由于stage_num ≠ 2,根据规则stride=2。shortcut:False(需要下采样并调整通道)。- 操作:
self.branch2a:3x3卷积,stride=2,输入 256x40x40 → 输出 512x20x20。self.branch2b:3x3卷积,stride=1,保持 512x20x20。self.short:若variant='d',使用AvgPool2d(2,2)+ 1x1卷积(stride=1),将输入 256x40x40 → 512x20x20。
- 输出:512x20x20(分辨率减半,通道数翻倍)。
-
第二个
BasicBlock(i=1):stride:1。shortcut:True(输入输出通道相同,直接相加)。- 操作:3x3卷积,
stride=1,分辨率保持 20x20。 - 输出:512x20x20。
最终输出
- 尺寸:512x20x20(标记为 P5/32,表示相对原图下采样 32 倍)。

















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









