






闲的无聊用了deepseek配合claude3.7 写了一个今日头条的自动发文
部分代码
mport sys
import locale
import codecs
import time
import json
import os
import random
import requests
import http.client
import urllib.parse
import datetime # 添加datetime模块
from bs4 import BeautifulSoup
from PyQt5.QtWidgets import (QApplication, QMainWindow, QWidget, QVBoxLayout, QHBoxLayout,
QLabel, QLineEdit, QTextEdit, QPushButton, QFileDialog,
QProgressBar, QMessageBox, QCheckBox, QGroupBox, QListWidget,
QListWidgetItem, QTabWidget, QSplitter, QComboBox, QTimeEdit,
QSpinBox, QTableWidget, QTableWidgetItem, QHeaderView, QFormLayout,
QAbstractItemView)
from PyQt5.QtCore import Qt, QThread, pyqtSignal, QSettings, QTimer, QTime, QDate, QDateTime
from PyQt5.QtGui import QIcon, QFont, QColor, QTextCursor
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.chrome.service import Service
from selenium.common.exceptions import TimeoutException, NoSuchElementException
from webdriver_manager.chrome import ChromeDriverManager
from selenium.webdriver.common.keys import Keys
import re
# 配置信息
CONFIG = {
"news_api_key": "36de5db81215",
"whyta_api_key": "36de5db81215",
"max_title_length": 30,
"min_title_length": 2,
"max_content_length": 2000,
"default_tags": ["AI", "科技", "互联网"],
"user_agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36",
"max_retries": 3
}
# 设置控制台输出编码为 UTF-8
if sys.platform == 'win32':
# Windows 平台特殊处理
try:
if sys.stdout and hasattr(sys.stdout, 'buffer'):
sys.stdout = codecs.getwriter('utf-8')(sys.stdout.buffer, 'strict')
if sys.stderr and hasattr(sys.stderr, 'buffer'):
sys.stderr = codecs.getwriter('utf-8')(sys.stderr.buffer, 'strict')
except Exception as e:
print(f"设置控制台编码时出错: {str(e)}")
class Logger:
"""日志记录器"""
def __init__(self, text_edit=None):
self.text_edit = text_edit
def log(self, message, level="INFO"):
"""记录日志"""
timestamp = QDateTime.currentDateTime().toString("yyyy-MM-dd hh:mm:ss")
log_message = f"[{timestamp}][{level}] {message}"
if self.text_edit:
self.text_edit.append(log_message)
self.text_edit.moveCursor(QTextCursor.End)
print(log_message)
class ArticleCrawler(QThread):
"""文章爬取线程"""
article_signal = pyqtSignal(dict)
error_signal = pyqtSignal(str)
log_signal = pyqtSignal(str, str) # (message, level)
def __init__(self, source, keyword=None, category=None):
super().__init__()
self.source = source
self.keyword = keyword
self.category = category
self.logger = Logger()
def log(self, message, level="INFO"):
self.log_signal.emit(message, level)
self.logger.log(message, level)
def run(self):
try:
self.log(f"开始从 {self.source} 爬取文章...")
article = self.crawl()
if article:
self.log(f"成功获取文章:{article.get('title', '无标题')}")
article['source'] = self.source
self.article_signal.emit(article)
else:
self.error_signal.emit("未找到合适的文章")
except Exception as e:
self.log(f"爬取失败:{str(e)}", "ERROR")
self.error_signal.emit(f"爬取错误:{str(e)}")
def crawl(self):
"""主爬取方法"""
if self.source == "新闻API":
return self.crawl_news_api()
elif self.source == "知乎热榜":
return self.crawl_zhihu_hot()
else:
self.error_signal.emit(f"不支持的数据源:{self.source}")
return None
def crawl_news_api(self):
"""使用API获取新闻"""
for retry in range(CONFIG['max_retries']):
try:
self.log(f"尝试获取新闻(第{retry+1}次)...")
response = requests.get(
f"https://whyta.cn/api/tx/bulletin?key={CONFIG['whyta_api_key']}&num=1",
headers={'User-Agent': CONFIG["user_agent"]},
timeout=10
)
response.raise_for_status()
data = response.json()
if data.get("code") == 200:
return self.process_news_data(data)
self.log(f"API返回错误:{data.get('msg', '未知错误')}", "WARNING")
except Exception as e:
self.log(f"API请求失败:{str(e)}", "WARNING")
self.log("所有重试次数已用尽,尝试备用方案", "WARNING")
return self.generate_fallback_article()
def process_news_data(self, data):
"""处理新闻数据"""
news_list = data.get("result", {}).get("list", [])
if not news_list:
return None
news = news_list[0]
content = f"""
<div style="font-family: 'Microsoft YaHei'; line-height: 1.6;">
<h2>{news.get('title', '')}</h2>
<p>{news.get('digest', '')}</p>
<p>发布时间:{news.get('mtime', '')}</p>
</div>
"""
return {
'title': news.get('title', '默认标题'),
'content': content,
'tags': ["热点", "资讯"],
'cover_url': random.choice(self.get_cover_images()),
'source_url': news.get('url', '')
}
def get_cover_images(self):
"""获取封面图片列表"""
return [
"https://img.zcool.cn/community/01a9a55d145660a8012187f447cfef.jpg",
"https://img.zcool.cn/community/0372d195ac1cd55a8012062e3b6c21.jpg",
"https://img.zcool.cn/community/01639a56f0bb8a6ac7251df8e40a1a.jpg"
]
def generate_fallback_article(self):
"""生成备用文章"""
timestamp = time.strftime("%Y-%m-%d %H:%M")
return {
'title': f"备用文章 {timestamp}",
'content': f"<p>这是自动生成的备用内容,发布时间:{timestamp}</p>",
'tags': ["备用"],
'cover_url': "",
'source_url': ""
}
def crawl_zhihu_hot(self):
"""爬取知乎热榜"""
try:
response = requests.get('https://www.zhihu.com/billboard',
headers={'User-Agent': CONFIG["user_agent"]},
timeout=10)
soup = BeautifulSoup(response.text, 'html.parser')
items = soup.select('.HotList-item')
if not items:
return None
item = random.choice(items)
title = item.select_one('.HotList-itemTitle').get_text().strip()
metrics = item.select_one('.HotList-itemMetrics').get_text().strip()
content = f"""
<div style="font-family: 'Microsoft YaHei'; line-height: 1.6;">
<h2>{title}</h2>
<p>热度:{metrics}</p>
</div>
"""
return {
'title': title,
'content': content,
'tags': ["知乎", "热榜"],
'cover_url': "",
'source_url': "https://www.zhihu.com"
}
except Exception as e:
self.log(f"知乎热榜爬取失败:{str(e)}", "ERROR")
return None
class PublishWorker(QThread):
"""发布文章线程"""
update_signal = pyqtSignal(str, str) # (message, level)
progress_signal = pyqtSignal(int)
finished_signal = pyqtSignal(bool, str)
def __init__(self, account, title, content, tags=None, cover_image=None, headless=True, debug=False):
super().__init__()
self.account = account
self.title = title
self.content = content
self.tags = tags or []
self.cover_image = cover_image
self.headless = headless
self.debug = debug
self.driver = None
self.logger = Logger()
def log(self, message, level="INFO"):
self.update_signal.emit(message, level)
self.logger.log(message, level)
def run(self):
try:
self.initialize_browser()
self.login_account()
self.publish_article()
self.finished_signal.emit(True, "发布成功")
except Exception as e:
self.log(f"发布失败:{str(e)}", "ERROR")
self.finished_signal.emit(False, str(e))
finally:
self.cleanup()
def initialize_browser(self):
"""初始化浏览器"""
self.log("正在启动浏览器...")
chrome_options = Options()
if self.headless:
chrome_options.add_argument('--headless')
chrome_options.add_argument('--disable-gpu')
chrome_options.add_argument('--no-sandbox')
chrome_options.add_argument('--disable-dev-shm-usage')
chrome_options.add_argument('--disable-extensions')
chrome_options.add_argument('--disable-software-rasterizer')
chrome_options.add_argument(f'user-agent={CONFIG["user_agent"]}')
# 设置窗口大小为最大化
chrome_options.add_argument("--start-maximized")
# 设置更大的窗口尺寸
chrome_options.add_argument("--window-size=1920,1080")
if self.debug:
# 调试模式下不使用无头模式
self.headless = False
try:
self.driver = webdriver.Chrome(
service=Service(ChromeDriverManager().install()),
options=chrome_options
)
# 再次确保窗口最大化
self.driver.maximize_window()
except Exception as e:
self.log(f"使用 ChromeDriverManager 失败: {str(e)}", "WARNING")
try:
self.driver = webdriver.Chrome(options=chrome_options)
self.driver.maximize_window()
except Exception as e2:
raise Exception(f"浏览器初始化失败: {str(e2)}")
self.driver.set_page_load_timeout(30)
self.driver.set_script_timeout(30)
def login_account(self):
"""登录账号"""
self.log("正在登录账号...")
try:
# 先访问首页
self.driver.get("https://mp.toutiao.com/")
time.sleep(2)
# 清除所有cookie
self.driver.delete_all_cookies()
# 加载Cookies
for cookie in self.account['cookies']:
if 'expiry' in cookie:
del cookie['expiry']
try:
self.driver.add_cookie(cookie)
except Exception as e:
self.log(f"添加Cookie失败: {cookie['name']} - {str(e)}", "WARNING")
# 刷新页面
self.driver.refresh()
time.sleep(5)
# 检查登录状态
if "login" in self.driver.current_url:
# 尝试截图保存登录页面
try:
screenshot_path = f"login_error_{time.strftime('%Y%m%d%H%M%S')}.png"
self.driver.save_screenshot(screenshot_path)
self.log(f"已保存登录页面截图: {screenshot_path}", "INFO")
except:
pass
raise Exception("Cookie失效,需要重新登录")
# 验证是否成功登录
try:
username_element = WebDriverWait(self.driver, 10).until(
EC.presence_of_element_located((By.CSS_SELECTOR, ".username, .user-name"))
)
self.log(f"成功登录账号: {username_element.text}", "SUCCESS")
except:
self.log("无法验证用户名,但似乎已登录", "WARNING")
except Exception as e:
self.log(f"登录失败: {str(e)}", "ERROR")
raise
def publish_article(self):
"""发布文章"""
self.log("正在进入发布页面...")
self.driver.get("https://mp.toutiao.com/profile_v4/graphic/publish")
time.sleep(5)
max_retries = 2
for attempt in range(max_retries + 1):
try:
self.input_title()
self.input_content()
self.set_publish_options()
self.submit_article()
self.log("发布流程完成", "SUCCESS")
break
except Exception as e:
if attempt < max_retries:
self.log(f"发布尝试 {attempt+1} 失败,正在重试: {str(e)}", "WARNING")
time.sleep(3)
# 刷新页面重试
self.driver.refresh()
time.sleep(5)
else:
self.log(f"所有重试都失败: {str(e)}", "ERROR")
raise
def input_title(self):
"""输入标题"""
self.log("正在输入标题...")
try:
title_input = WebDriverWait(self.driver, 10).until(
EC.presence_of_element_located((By.CSS_SELECTOR, "textarea[placeholder*='请输入文章标题']"))
)
title_input.clear()
# 使用更安全的标题内容
safe_title = "今日资讯分享" if "晒" in self.title or "杨" in self.title else self.title
title_input.send_keys(safe_title)
self.log(f"输入标题: {safe_title}")
except Exception as e:
self.log(f"标题输入失败:{str(e)}", "WARNING")
self.driver.execute_script(f'document.querySelector("textarea[placeholder*=\"请输入文章标题\"]").value = "{self.title}";')
def input_content(self):
"""输入文章内容"""
self.log("正在输入内容...")
try:
# 清除可能的格式标记
clean_content = re.sub(r'p, li \{ white-space: pre-wrap; \}', '', self.content)
# 使用JavaScript设置内容,避免格式问题
js_script = f"""
var editor = document.querySelector('.ProseMirror');
if (editor) {{
editor.innerHTML = `{clean_content}`;
return true;
}}
return false;
"""
result = self.driver.execute_script(js_script)
if not result:
# 如果JavaScript方法失败,尝试传统方法
content_area = WebDriverWait(self.driver, 10).until(
EC.presence_of_element_located((By.CSS_SELECTOR, ".ProseMirror"))
)
content_area.clear()
content_area.send_keys(clean_content)
time.sleep(2)
except Exception as e:
self.log(f"内容输入失败:{str(e)}", "WARNING")
# 尝试使用更简单的方法
try:
content_area = self.driver.find_element(By.CSS_SELECTOR, ".ProseMirror")
self.driver.execute_script("arguments[0].innerHTML = arguments[1]", content_area, clean_content)
except Exception as e2:
raise Exception(f"内容输入失败: {str(e2)}")
def set_publish_options(self):
"""设置发布选项"""
self.log("正在设置发布选项...")软件截图
调用了免费的api接口
效果截图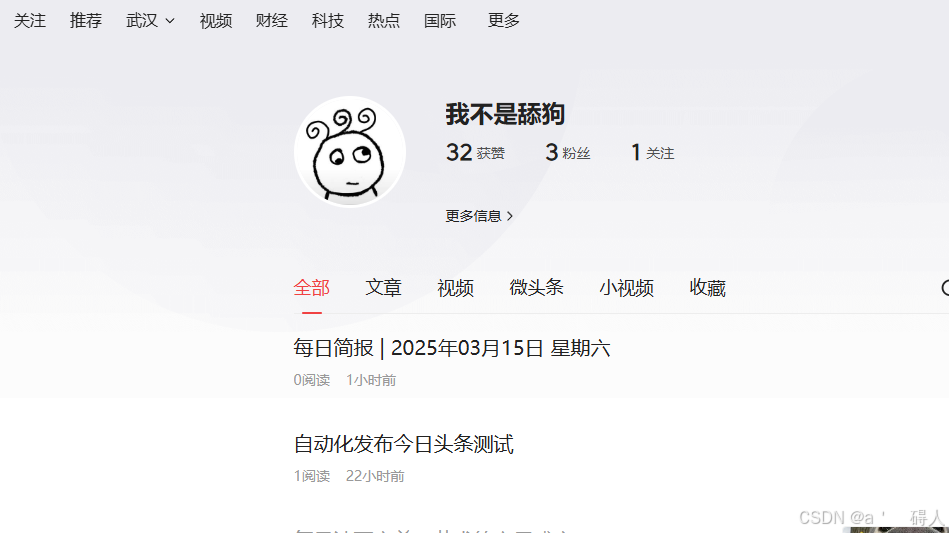
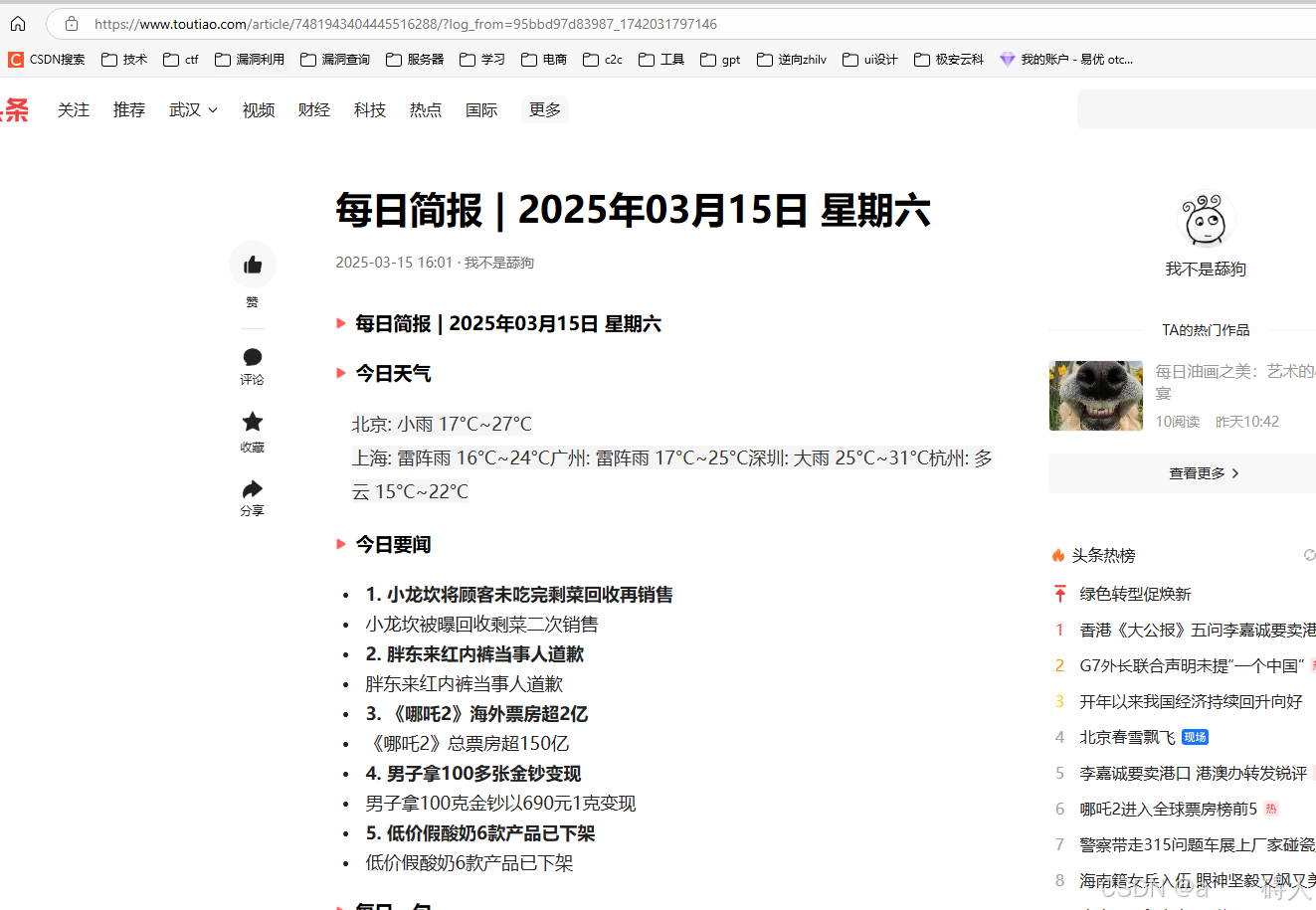 .之前遇到的难题是在今日头条发送按钮那里是先预览在发货
.之前遇到的难题是在今日头条发送按钮那里是先预览在发货
之前一致失败,后面用了禁用js和并发效果成功实现自动发文
现在可以去进入头条查看每天一篇舔狗日记

利用cookie登录的

















 835
835

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









