







1.大数据解题技巧

2.题目一

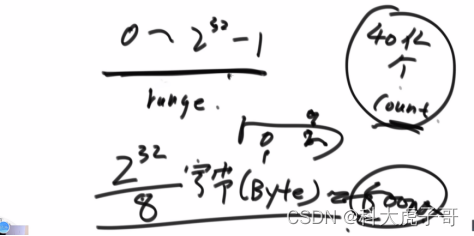
解:范围是0~232-1,可以申请一个长度为232的位图,占用的内存空间为:2^32/8byte=500M,用每一位表示一个文件是否出现过
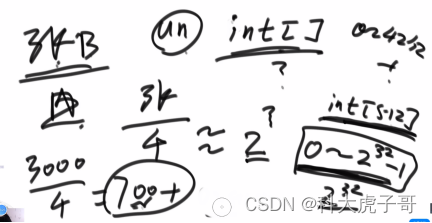
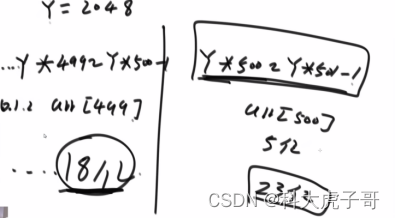
进阶:申请一个不超过给定内存且是2的某次方的最大长度(假设为512)的整形数组,将pow(2,32)等分成512份,每一份为8388608个数。数组的每个元素代表一定范围的文件出现多少次;由于文件数小于2^32,所以一定存在每个位置上的元素小于8388608个,可以确定缺少的数字在哪个范围;然后将定位到的范围再分为512份,周而复始,一定能定位到那个没出现的数字
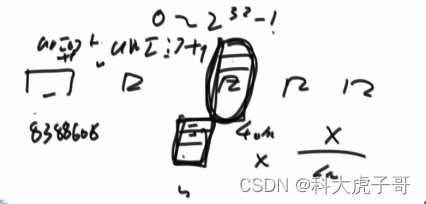
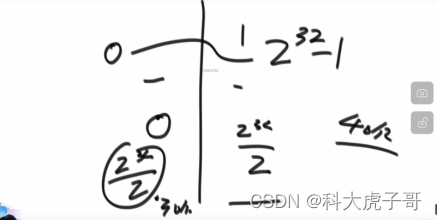
更进一步,可以用另个变量的内存进行二分:
3.题目二

补充问题解:将海量词汇通过哈希函数分流到小文件中去,对每种小文件统计出各自的搜索热门top100词汇,然后利用下面的方法求出总体的top100:小文件根据词频用大根堆组织;把每个大根堆的堆顶拿出单独组成一个总大根堆,每次从总堆弹出一个元素,并且将该元素原来所在的堆再取出一个元素放入总堆(堆上堆的结构可以理解为是一个二维堆)
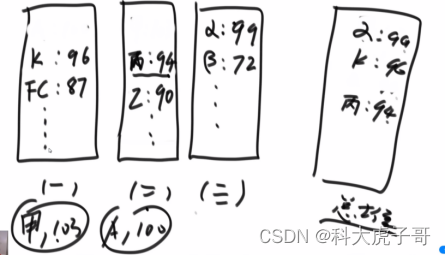
4.题目三:

解:位图的升级:用两个位表示一个数出现的状态:00->0次、01->1次、10->2次、11->2次以上
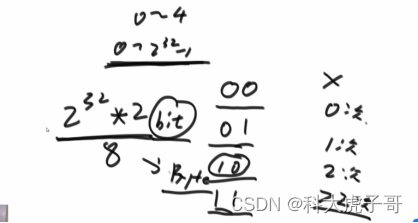
补充解:还是范围统计的思想
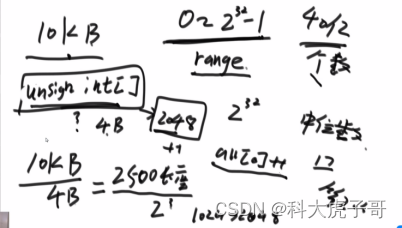
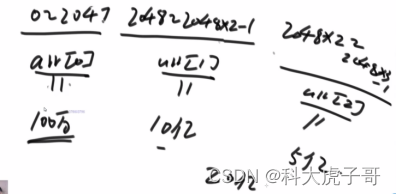
5.补充题目(腾讯)
假设有一个10G(硬盘空间)的文件,每个文件是一个有符号整数,只给你5G内存,将这10G文件排序
解:
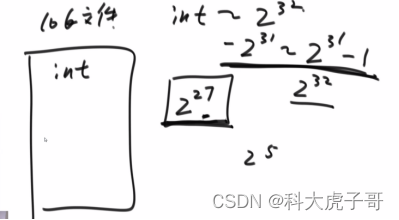
方法一:根据给定内存大小申请一个小根堆(估计上额外消耗),将整个文件的范围(-231~231-1)等分成N份,每份的大小位小根堆的容量,从最低范围开始,依次将每一份上的数据添加到小根堆(跳过不属于当前范围的数字),然后将小根堆中的数据输出到硬盘中
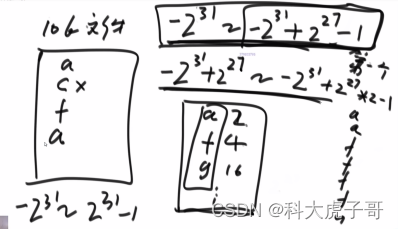
方法二:准备一个大根堆,依次将文件数字加入到大根堆,直到大根堆满,然后继续遍历文件数字,如果当前数字大于栈顶数字,则跳过;小于栈顶数字则将栈顶元素移除,将当前数字加入到大根堆。当遍历完所有文件数字之后,大根堆中存储的就是整个文件最小的大根堆size个数,存储到硬盘中。然后再次遍历整个文件数字,忽略之前已经输出的数字(即进入大根堆的门槛提高了)


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









