







PS:本文主要用于自我整理总结,涉及代码已成功在我电脑上运行,如果恰好帮到各位,不甚荣幸。
环境
Windows10
CUDA10.2
cudnn8.0.5.39
torch1.7
数据集
图像与标签
标注软件为labelImg
第一步
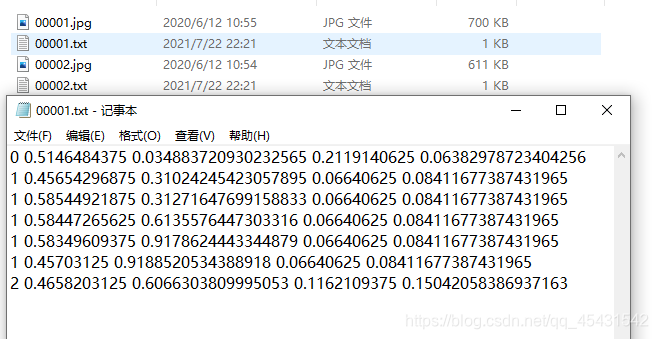
①如果你的数据本来就是txt格式的,那就直接将训练图像和训练标签放在一个文件夹中,验证图像和验证标签放在一个文件夹中,如下图:
②如果你之前用别的模型训练,已经有标注好的xml文件(我就是这样的),即可以用下面的方法批量得将xml文件转换成训练所需的txt文件。
首先,按照下面的格式构造目录结构:
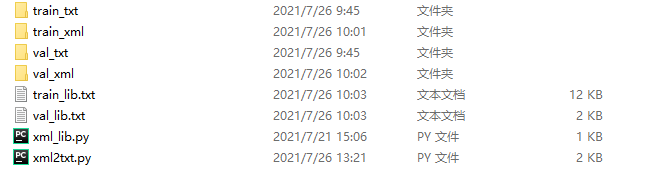
其中:
train_xml与val_xml文件夹用来存放我们已有的xml文件
train_txt与val_txt文件夹用来存放生成的txt文件
train_lib与val_lib为我们需要转换的索引目录(这个是后面程序生成的,刚开始没有)
xml_lib是用来生成索引目录的程序
xml2txt是用来进行转换的程序
先执行xml_lib,再执行xml2txt
xml_lib.py:
import os
train_xmlfilepath = r'train_xml'
val_xmlfilepath = r'val_xml'
train_xmls = os.listdir(train_xmlfilepath)
val_xmls = os.listdir(val_xmlfilepath)
train_nums = len(train_xmls)
train_list = range(train_nums)
print("训练集的数量:", train_nums)
val_nums = len(val_xmls)
val_list = range(val_nums)
print("验证集的数量:", val_nums)
ftrain = open('train_lib.txt', 'w')
fval = open('val_lib.txt', 'w')
for i in train_list:
name = train_xmls[i][:-4]+'\n'
ftrain.write(name)
ftrain.close()
for i in val_list:
name = val_xmls[i][:-4]+'\n'
fval.write(name)
fval .close()
xml2txt.py:
import os
import pickle
from PIL import Image
from os.path import join
import xml.etree.ElementTree as ET
sets = ['train', 'val']
classes = ["pig"] # 这里写你的标签
def convert(size, box):
dw = 1./size[0]
dh = 1./size[1]
x = (box[0] + box[1])/2.0
y = (box[2] + box[3])/2.0
w = box[1] - box[0]
h = box[3] - box[2]
x = x*dw
w = w*dw
y = y*dh
h = h*dh
return x, y, w, h
def convert_annotation(image_set, image_id):
in_file = open('%s_xml/%s.xml' % (image_set, image_id))
# print('%s_xml/%s.xml' % (image_set, image_id))
out_file = open('%s_txt/%s.txt'%(image_set, image_id), 'w')
tree = ET.parse(in_file)
root = tree.getroot()
image_PIL = Image.open(r'F:\Work\yolov5\datasets\pig\images\%s\%s.jpg' % (image_set, image_id))
# print('输出类型:{}'.format(type(image_PIL)))
# print('图片的尺寸:{}'.format(image_PIL.size))
w = int(image_PIL.size[0])
h = int(image_PIL.size[1])
for obj in root.iter('object'):
difficult = obj.find('difficult').text
cls = obj.find('name').text
if cls not in classes or int(difficult) == 1:
continue
cls_id = classes.index(cls)
xmlbox = obj.find('bndbox')
b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text), float(xmlbox.find('ymin').text), float(xmlbox.find('ymax').text))
bb = convert((w, h), b)
out_file.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + '\n')
for image_set in sets:
image_ids = open('%s_lib.txt' % image_set).read().strip().split()
for image_id in image_ids:
convert_annotation(image_set, image_id)
第二步
生成训练的索引目录
import os
import glob
import random
import xml.etree.ElementTree as ET
trainpath = r"./*.jpg" # 要绝对地址,后面好索引到具体图像
testpath = r'./*.jpg'
listset = r'List/' # 存放生成索引目录的文件夹
ftrain = open(os.path.join(listset, 'train.txt'), 'w')
for trainfile in glob.glob(trainpath):
ftrain.write(trainfile + '\n')
ftrain.close()
ftest = open(os.path.join(listset, 'test.txt'), 'w')
for testfile in glob.glob(testpath):
ftest.write(testfile + '\n')
ftest.close()
print('索引目录建立完毕')
配置文件的修改
我训练的是tiny版本,因为对硬件要求不高,完整的yolo版修改方法也大差不差,主要需要三个文件:

这是我修改的,原版的可以在📂x64(就是你生成darknet.exe的文件夹)的📂cfg和📂data里找到,即



这三个文件,复制粘贴重命名后,将他们改一下就行(可以都以文本文档的形式打开进行更改)。
obj.names文件:存放你的训练种类
obj.data文件:存放你的数据索引

yolov4-tiny.cfg文件:
需要改的参数一般是这些
batch=64 # 表示网络积累多少个样本后进行一次正向传播
subdivisions=16 # 将一个batch的图片分sub次完成网络的正向传播
learning_rate=0.001 # 初始学习率
max_batches = 6000 # 训练达到max_batches后停止学习,一般为classes2000
steps=4800,5400 # 根据batch_num调整学习率,分别为max_batches0.8和*0.9
然后搜索关键字yolo

修改filters和classes两个参数(tiny版修改两处,yolo版修改3处)
训练
当数据集准备好后,就可以打开命令提示符,先进入环境activate pytorch17,然后,进入cd到存放darknet.exe的文件夹📂x64,然后输入训练命令darknet.exe detector train Mine/obj.data Mine/yolov4-tiny-obj.cfg Mine/Models/yolov4-tiny.conv.29
命令分析:
Mine/obj.data 是我data文件放的位置
Mine/yolov4-tiny-obj.cfg是我cfg文件放的位置
Mine/Models/yolov4-tiny.conv.29是我预训练模型放的位置(这个在GitHub中就可以下载)
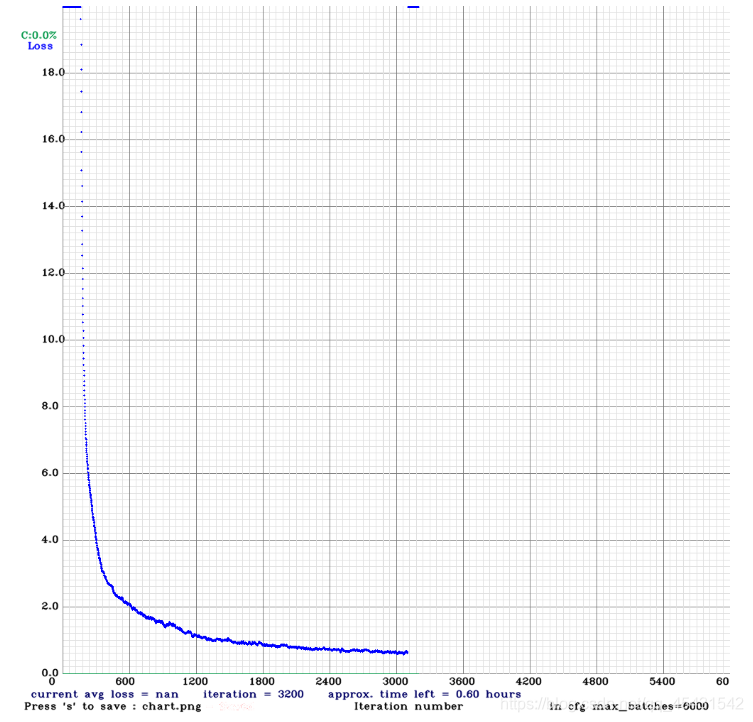
这个是我训练到3000步时的loss曲线,它默认时1000步保存一次,我到3000多时loss值就变成nan,原因还在思考中(我这个设备tiny版还是只能小bs来训练,也是难╥﹏╥,寻思后期可能电脑处理不过来了,导入图像为nan值,因为考虑底层loss值计算会加一个偏差值,不太会导致这个原因,再慢慢查吧)不过之前的模型也够用了,loss为0.7左右。
检测的命令darknet.exe detector test Mine/obj.data Mine/yolov4-tiny-obj.cfg Mine/Logs/yolov4-tiny-obj_1000.weights -ext_output Mine/Image/00001.jpg
差不多就是这样哈,有错误的话我后期再修正,如果还有什么问题评论里再谈吧。

















 633
633

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









