







使用的工具即环境
- pycharm professional
- python 3.6
- requests库
- lxml库
实验的代码
import requests
from lxml import etree
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:73.0) Gecko/20100101 Firefox/73.0'
}
url = 'https://movie.douban.com/cinema/nowplaying/ganzhou/'
response = requests.get(url, headers=headers)
text = response.text
film_lists = []
# 对数据进行抓取
def imformation():
html = etree.HTML(text)
ul = html.xpath("//ul[@class='lists']")[1]
lis = ul.xpath('./li')
for li in lis:
title = li.xpath('./@data-title')
duration = li.xpath('./@data-duration')
region = li.xpath('./@data-region')
actors = li.xpath('./@data-actors')
dicts = {
'title': title,
'duration': duration,
'region': region,
'actors': actors,
}
film_lists.append(dicts)
# 展示数据
def show_date():
for i in film_lists:
for k, v in i.items():
print(k, v)
print('---------------------')
if __name__ == '__main__':
imformation()
show_date()
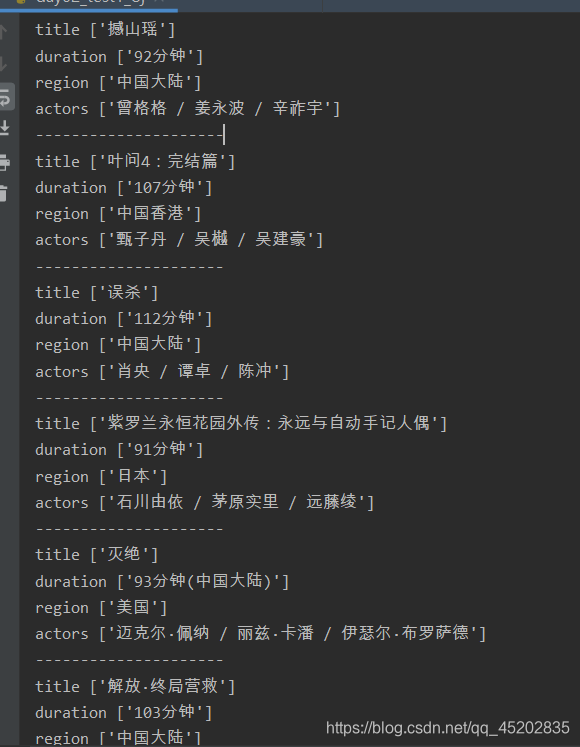
实验成果截图
结语
能新学到很多东西我很开心,希望在以后的学习生活里能更进一步,争取早日实现爬取更多更好的资源,能够自己完成聚焦爬虫的编写!

















 2724
2724

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









