







一、方法内联
- JVM将调用达到一定阈值的方法替换成方法体本身,从而消除调用成本。就是将调用的方法嵌入到方法里面去,成为方法的一部分,以后不用在考虑这个调用过程了。
- 之所以有方法内联,是因为调用方法的时候,有方法栈帧的生成、参数字段的压入(局部变量表)、栈帧的弹入弹出、指令的操作等消耗
public static void function_A(int a, int b){
//do something
function_B(a,b);
}
public static void function_B(int c, int d){
//do something
}
public static void main(String[] args){
function_A(1,2);
}
- 方法执行流程:由下图可以看出如果方法嵌套的很深,这种额外的方法开销就很大
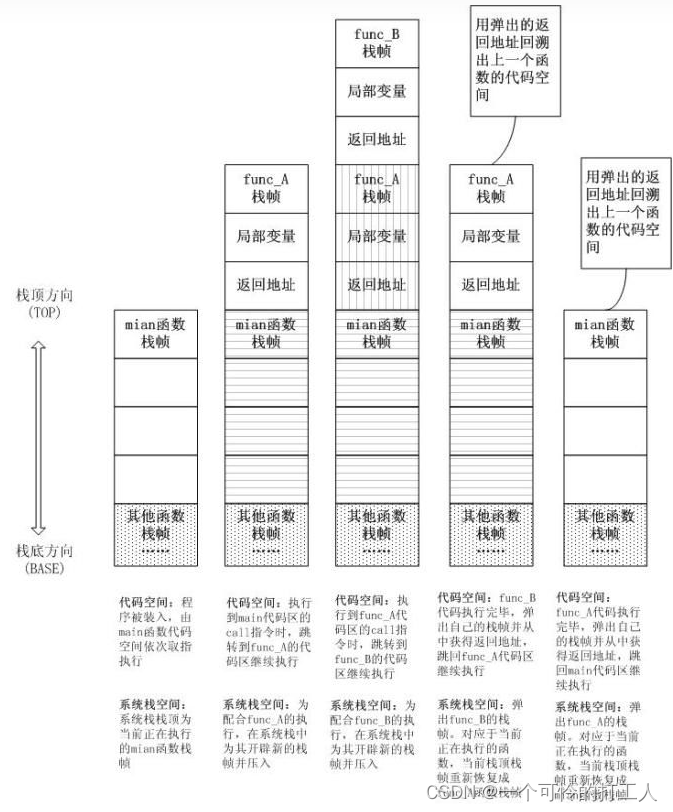
- 很有可能方法体本身执行的开销都没有这种额外的开销大, 这也就是为啥在热点代码中会出现方法内联的原因了
- 举例:
public int add(int a, int b , int c, int d){
return add(a, b) + add(c, d);
}
public int add(int a, int b){
return a + b;
}
public int add(int a, int b , int c, int d){
return a + b + c + d;
}
- 内联条件
- 热点代码:如果一个方法的执行频率很高,那么表示优化的潜力就很大。
- 方法体不能太大,因为太大的话JIT编译器翻译后,存放在code cache中,就很占空间。一般是热点代码小于325字节,非热点代码小于35字节
- 如果希望方法被内联,那么尽量使用private,final,static修饰,而不是使用public protected修饰,因为JIT要去判断这个方法是不是父类的,或者别的类的
二、逃逸分析
什么是“对象逃逸”
- 对象逃逸的本质是对象指针逃逸
- 如果一个对象的指针被多个方法或者线程引用,那么就称之为“对象逃逸”
什么是逃逸分析
- 主要是有效的减少java程序中同步负载和内存堆分配压力的一个算法。通过这个分析,就能知道一个新对象是否要分配到堆内。
- 逃逸分析不是优化手段,而是代码分析手段
- 举例:
public User doSomething1() {
User user1 = new User ();
user1 .setId(1);
user1 .setDesc("xxxxxxxx");
// ......
return user1 ;
}
public void doSomething2() {
User user2 = new User ();
user2 .setId(2);
user2 .setDesc("xxxxxxxx");
// ......
}
- jdk1.8以后是默认开起逃逸分析的
基于逃逸分析的优化
假设判断出对象不逃逸,编译器会做出一些优化的:
- 栈上分配:新对象分配在栈上,而不是堆中。如果对象在程序中被分配,并且这个对象的指针永远不会逃逸,那么就分配在栈上,这样会减少垃圾收集的频率
- 同步消除:如果发现某个对象只在当前线程使用,那么这个对象的操作可以不同步
public static void main(String[] args){
long start = System.currentTimeMillis();
for(int i = 0; i < 5_000_000; i++){
createObject();
}
}
public static void createObject(){
synchronized (new Object()){
}
}
- 标量、聚合量替换:如果发现一个对象的内存要求是不连续的,那么这个对象部分可以不存在内存中,而是存在cpu寄存器里面
标量替换
- 标量:不可在被分解的变量,比如基本数据类型int,long等
- 聚合量:可以进一步被分解的变量,比如对象
- 标量替换:通过逃逸分析,发现一个对象不会发生逃逸时,且可以进一步分解,JVM不会创建这个对象了。而是把这个对象的成员变量分解成若干个被这个方法使用的成员变量替换,这些替代的变量就存在方法的局部变量表里面,或者寄存器里面。这样就不会因为没有一个大的内存空间导致对象不能分配了
什么条件会触发逃逸分析?
- 新的对象判断是不是可以分配在栈中
- 判断是不是可以分配在TLAB中
- 是否使用JVM的悲观策略,分配在old区
- 分配在Eden区
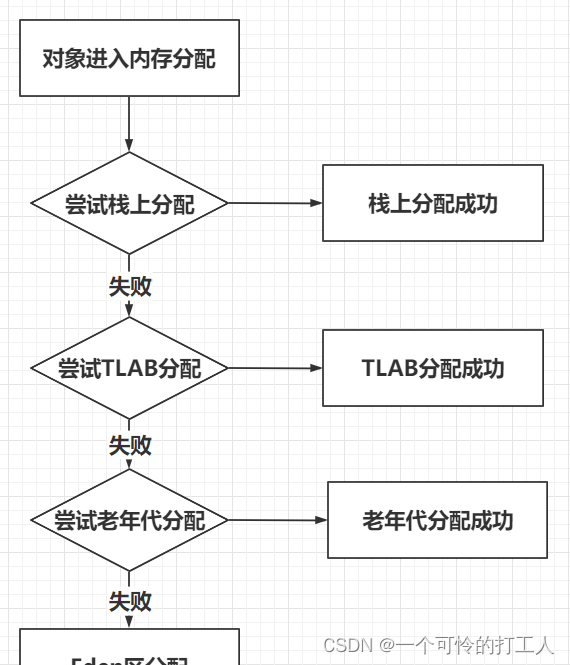
Java的逃逸分析只会发生在JIT的即时编译中,因为启动前已经通过各种条件判断是否满足逃逸分析。
只要满足以下条件就是逃逸:- 对象赋值给了堆中的字段或者对象
- 对象被传入了不确定的代码中运性
- 逃逸范围:全局逃逸、参数逃逸,不逃逸
TLAB
- 线程本地分配缓冲区,一个线程专属的内存区域
- 对象一般被分配在堆中,但是堆中的内存是共享的,如果有好几个线程同时去申请堆中的资源,就会导致竞争排队(CAS),这样效率就会很低。
- 每个线程都分配自己的TLAB。在堆中划分出来的,这个线程独享的连续内存。
- 当一个线程的TLAB满了,那么就将这个TLAB交给堆Eden管理,然后重新申请一个TLAB
- 当GC的时候,就跟正常GC流程走,然后线程又会重新在Eden中申请TLAB
- 不同线程之前的TLAB是可以共享的,也就是说B线程可以访问A线程的TLAB区,前提是你要能访问的到
内存优化
- 一般来说,我们是不需要去优化JVM内存的,这是最后的手段
- 但是如果业务有瞬时高并发的场景,那么就需要考虑了
- 瞬时高并发举例(条件:6000/1S的请求量,4U8G的机器,2台,这个时候你要怎么分配内存呢?):
- 首先8G的内存,一般我们设置堆内存6G,这个看实际,因为你要给方法区留空间,或者说你的机器上还有别的组件
- 6000/10S,也就是说2台服务器每台承受3000的请求,但是你的负载均衡一定能这么平分吗?所以一台基本上就是4000来估计
- 假设一个请求,需要在数据库里面查询的对象大小是1kb,那么4000*1kb=4000kb
- 堆内存在6G的情况下,young占用了2G,Eden区占用了1.6G。
- 你的一个请求所需的内存一般是多少呢?1kb只是查询数据库的对象,你还有别的额外的对象占用内存啊,比如说还有9kb的额外对象。那么就是说你需要4000kb*10=40M的内存
- 1.6G*1024/40M = 41S,也就是说,20S后你的Young就慢了触发YoungGC,会有STW,这个STW你能接受吗?
- 如果不能接受STW,那么我们可以把Young设成3.4G,将Old设置成1.6G。那么就能解决这个问题啦

















 2662
2662

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









