







 本文档详述了如何使用Spark创建WordCount,包括创建测试文件、使用flatMap和map处理数据,以及reduceByKey计算单词频率。通过实例解析sc.textFile、flatMap与map的区别,并展示了完整的WordCount操作流程。
本文档详述了如何使用Spark创建WordCount,包括创建测试文件、使用flatMap和map处理数据,以及reduceByKey计算单词频率。通过实例解析sc.textFile、flatMap与map的区别,并展示了完整的WordCount操作流程。
10.12使用Spark创建WordCount
10.12.1创建测试文件
在“终端”输入下列命令
#WordCount的数据目录
mkdir -p ~/pythonwork/ipynotebook/data
#切换至WordCount的数据目录
cd ~/pythonwork/ipynotebook/data
#编辑test.txt
gedit test.txt
输入下列内容

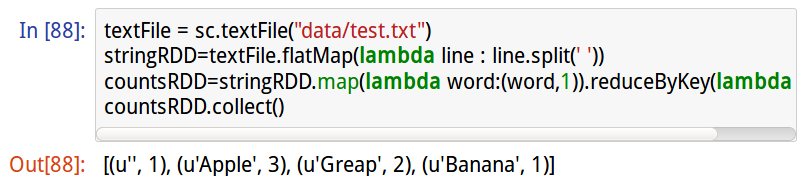
10.12.2执行WordCount spark命令
#读取文本文件
textFile = sc.textFile(“data/test.txt”)
#使用flatMap空格符分隔单词,并读取每个单词
stringRDD=textFile.flatMap(lambda line : line.split(" "))
#通过map reduce计算每个单词出现的次数
countsRDD=stringRDD.map(lambda word:(word,1).reduceByKey(lambda x,y :x+y)
#显示结果
countsRDD.collect()
10.13 Spark WordCount详细解说
10.13.1sc.textFile读取本地文件
sc.textFile是一个转换运行,不会立刻执行。所以可以使用.collect()显示文本内容

10.13.2 flatMap读取每一个单词
文本文件时以空格符分隔单词,我们可以使用flatMap指令取出每一个文字,并编写stringRDD,因为flatMap是转换运算,所以使用.collect()将结果转换为List,就会立刻执行。

10.13.3flatMap与map的差异
#map命令,具有分层

Map产生的List是分层的,第一层List是文本文件的第一行,第二层List是文本文件的二行。
#flatMap命令

Flat有平坦的意思,也就是说flatMap产生后会将List分层去掉。
10.13.4 map创建Key-Value Pair(键值对)

使用map命令将stringRDD每一个英文单词转换为Key-Value
其中Key值就是每一个英文单词、value值都是1
因为map值“转换”运算,所以不会立刻执行,所以加上.collect()
显示结果。
10.13.5 map加reduceByKey

reduceByKey传入匿名函数(lambda x,y: x+y),此匿名函数会将相同的Key值相加。因为reduceByKey是“转换”运算,所以不会立刻执行,加上“动作”运算.collect(),转换为列表List,就会马上执行。
10.14结论
我们学会了IPythonNoteBook介绍了Spark的基本功能RDD,还用WordCount作为Spark MapReduce统计文章单词的字数。

















 1968
1968

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









