




 本文详细介绍了如何使用Python Spark构建推荐系统,涵盖了从读取配置文件到训练RatingRDD数据,利用ALS模块进行训练,以及如何根据模型进行用户和电影的推荐。在训练过程中,通过ALS.train命令创建了MatrixFactorizationModel模型,并展示了针对用户和电影的推荐结果。
本文详细介绍了如何使用Python Spark构建推荐系统,涵盖了从读取配置文件到训练RatingRDD数据,利用ALS模块进行训练,以及如何根据模型进行用户和电影的推荐。在训练过程中,通过ALS.train命令创建了MatrixFactorizationModel模型,并展示了针对用户和电影的推荐结果。
12.6如何训练数据
ALS训练数据格式是RatingRDD数据类型
12.6.1配置文件读取路径
以上程序判断
·如果sc.master[0:5]是“local”,代表当前本地运行,读取文本文件。
·sc.master[0:5]不是是“local”,就有可能是YARN client或者Spark Stand Alone,必须读取HDFS文件。
12.6.2导入-100k数据
我们使用sc.textFile读取ml-100k数据集的u.data,并查看数据项数

12.6.3查看u.data第一项数据

以上4个字段分别是:用户id、项目id、评价、日期时间。
12.6.4导入Rating模块

12.6.5读取rawUserRDD前3个字段
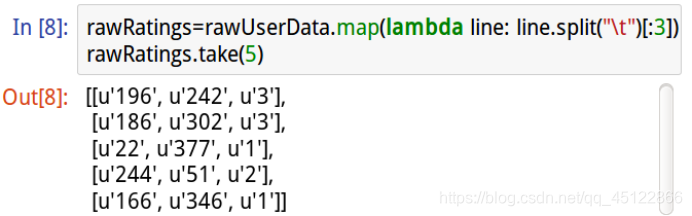
12.6.6准备ALS训练数据
ALS训练数据格式是RatingRDD数据类型,Rating定义如下。
Rating(user,product,rating)
各字段说明:
| 字段 | 说明 |
|---|---|
| User | 用户 |
| Product | 产品 |
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 2148
2148

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









