





1. GPU是显卡的核心部件
GPU负责处理图像和视频信息
显卡除GPU外,还负责输出图像到显示器及通信
但是,大多数情况下,可以将显卡叫做是GPU
2. 单卡与多卡
输入命令 nvidia-smi
单卡
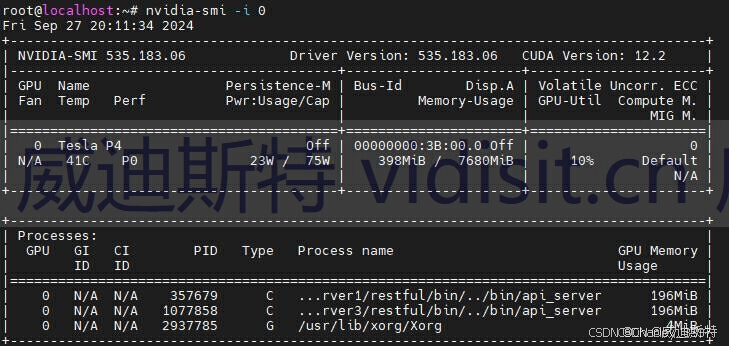
多卡


1. GPU是显卡的核心部件
GPU负责处理图像和视频信息
显卡除GPU外,还负责输出图像到显示器及通信
但是,大多数情况下,可以将显卡叫做是GPU
2. 单卡与多卡
输入命令 nvidia-smi
单卡
多卡
 873
4738
6830
2114
873
4738
6830
2114

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言


























