







目录
1. SparkCore
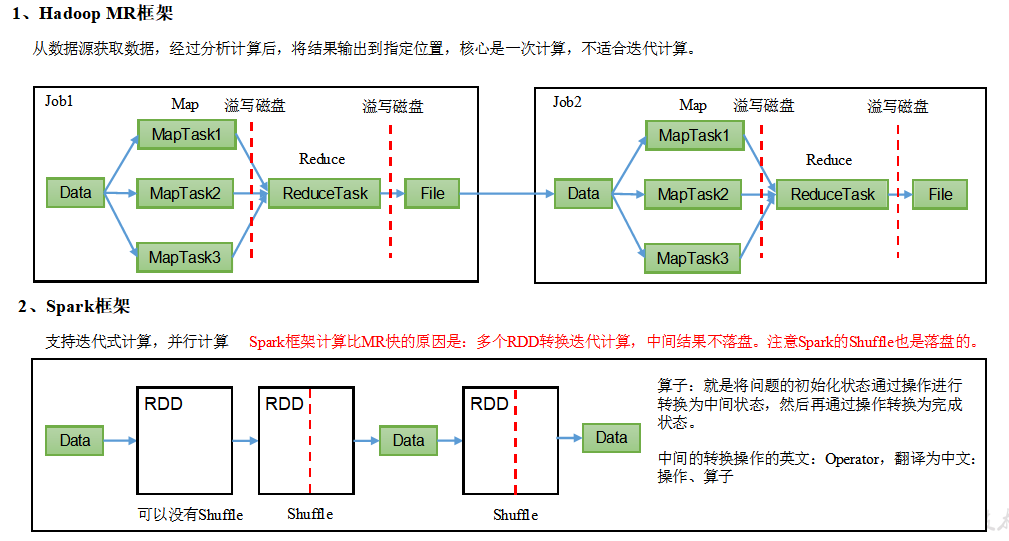
1.1 Hadoop与Spark框架的对比
1.2 Spark核心模块
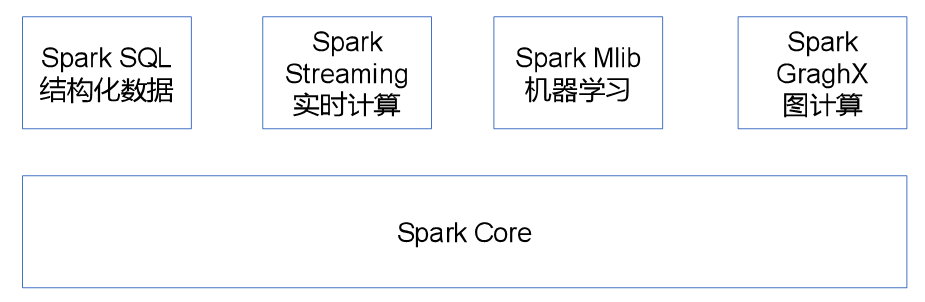
Spark Core
Spark Core中提供了Spark最基础与最核心的功能,Spark其他的功能如:Spark SQL,Spark Streaming,GraphX, MLlib都是在Spark Core的基础上进行扩展的
Spark SQL
Spark SQL是Spark用来操作结构化数据的组件。通过Spark SQL,用户可以使用SQL或者Apache Hive版本的SQL方言(HQL)来查询数据。
Spark Streaming
Spark Streaming是Spark平台上针对实时数据进行流式计算的组件,提供了丰富的处理数据流的API。
Spark MLlib
MLlib是Spark提供的一个机器学习算法库。MLlib不仅提供了模型评估、数据导入等额外的功能,还提供了一些更底层的机器学习原语。
Spark GraphX
GraphX是Spark面向图计算提供的框架与算法库。
1.3 简述Spark的架构
1.3.1 运行架构
Spark框架的核心是一个计算引擎,整体来说,它采用了标准 master-slave 的结构。
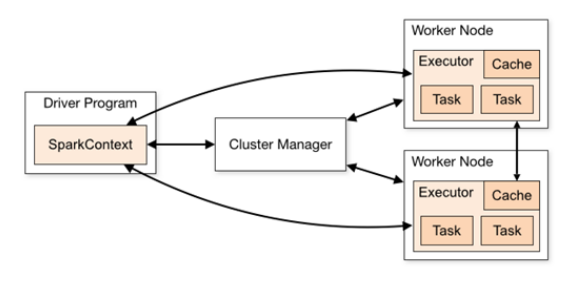
如下图所示,它展示了一个 Spark执行时的基本结构。图形中的Driver表示master,负责管理整个集群中的作业任务调度。图形中的Executor 则是 slave,负责实际执行任务。
1.3.2 核心组件
1)Driver
Spark驱动器节点,用于执行Spark任务中的main方法,负责实际代码的执行工作。
Driver在Spark作业执行时主要负责:
将用户程序转化为作业(job)
在Executor之间调度任务(task)
跟踪Executor的执行情况
通过UI展示查询运行情况
2)Executor
Spark Executor是集群中工作节点(Worker)中的一个JVM进程,负责在 Spark 作业中运行具体任务(Task),任务彼此之间相互独立。Spark 应用启动时,Executor节点被同时启动,并且始终伴随着整个 Spark 应用的生命周期而存在。如果有Executor节点发生了故障或崩溃,Spark 应用也可以继续执行,会将出错节点上的任务调度到其他Executor节点上继续运行。
Executor有两个核心功能:
负责运行组成Spark应用的任务,并将结果返回给驱动器进程
它们通过自身的块管理器(Block Manager)为用户程序中要求缓存的 RDD 提供内存式存储。RDD 是直接缓存在Executor进程内的,因此任务可以在运行时充分利用缓存数据加速运算。
1.4 Spark作业提交流程
Yarn Cluster模式
Cluster模式将用于监控和调度的Driver模块启动在Yarn集群资源中执行。一般应用于实际生产环境。
-
在YARN Cluster模式下,任务提交后会和ResourceManager通讯申请启动ApplicationMaster,
-
随后ResourceManager分配container,在合适的NodeManager上启动ApplicationMaster,此时的ApplicationMaster就是Driver。
-
Driver启动后向ResourceManager申请Executor内存,ResourceManager接到ApplicationMaster的资源申请后会分配container,然后在合适的NodeManager上启动Executor进程
-
Executor进程启动后会向Driver反向注册,Executor全部注册完成后Driver开始执行main函数,
-
之后执行到Action算子时,触发一个Job,并根据宽依赖开始划分stage,每个stage生成对应的TaskSet,之后将task分发到各个Executor上执行。
Spark提交作业参数
-
executor-cores —— 每个executor使用的内核数,默认为1
-
num-executors —— 启动executors的数量,默认为2
-
executor-memory —— executor内存大小,默认1G
-
driver-cores —— driver使用内核数,默认为1
-
driver-memory —— driver内存大小,默认512M
1.5 Spark核心编程
1.5.1 RDD概念
RDD(Resilient Distributed Dataset)叫做弹性分布式数据集,是Spark中最基本的数据处理模型。代码中是一个抽象类,它代表一个弹性的、不可变、可分区、里面的元素可并行计算的集合。
-
弹性
- 存储的弹性:内存与磁盘的自动切换;
- 容错的弹性:数据丢失可以自动恢复;
- 计算的弹性:计算出错重试机制;
- 分片的弹性:可根据需要重新分片。
-
分布式:数据存储在大数据集群不同节点上
-
数据集:RDD封装了计算逻辑,并不保存数据
-
数据抽象:RDD是一个抽象类,需要子类具体实现
-
不可变:RDD封装了计算逻辑,是不可以改变的,想要改变,只能产生新的RDD,在新的RDD里面封装计算逻辑
-
可分区、并行计算
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 1530
1530

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











