







 本文详细介绍了Spark中的RDD、DataFrame、DataSet及其特点,包括Broadcast变量和Accumulator的使用。深入探讨了Spark的部署模式,如standalone、yarn、mesos和k8s。同时讲解了Stage的Task并行度、宽依赖与窄依赖的概念,以及cache、persist、checkpoint和容错机制。此外,还对比了Spark与MapReduce的速度差异,并分析了Spark提交任务的执行流程。
本文详细介绍了Spark中的RDD、DataFrame、DataSet及其特点,包括Broadcast变量和Accumulator的使用。深入探讨了Spark的部署模式,如standalone、yarn、mesos和k8s。同时讲解了Stage的Task并行度、宽依赖与窄依赖的概念,以及cache、persist、checkpoint和容错机制。此外,还对比了Spark与MapReduce的速度差异,并分析了Spark提交任务的执行流程。
RDD,DataFrame,DataSet
- DataSet
- 产生于spaek1.6
- 比DataFrame多了泛型的支持
- DataFrame就是DataSet[row]
- DataSet[T]的元素经过tungsten优化,是内存的优化,可以节省空间85%
- 自动支持各种类型的编码器,就是强类型
- 基本类型 int ,long ,string
- row
- jvm对象,case class 对象
- 使得元素是样例类对象【student(name:string;age:int】时,将类的属性名映射成sql的表字段名,所以全面支持sql和dsl操作
- 支持编译时类型安全检查(ds.map(s=>s.不存在的字段) 这句代码编译时不通过
Hadoop,spark的各种端口
- 当使用standalone模式时,才设计下面4个端口
- 7077 sparkMaster进程的通信端口
- 8080 Master 的web ui 的查看端口
- 7078 spark worker 进程的通信端口
- 8081 worker 的webui 的查看端口
- 18080 spark 历史任务的webui查看端口
- 4040 查看某个蒸菜运行的spark application 的web端口
- 198888 是hadoop 的 mapreduce类型的任务的jobHistory的web端口
- 8088 是hadoop Yarn 类型的任务的监控页面
RDD的特点
-
五大特性
- 分区列表
- 依赖关系
- 计算函数
- 如果元素是key-value类型是,可以指定分区器
- 位置优先性
-
一个job,从action算子的最后一个RDD追溯到初始RDD之间的依赖关系,叫血缘关系,也叫lineaeg
- 依赖分为,宽依赖和窄依赖
Broadcast 广播变量
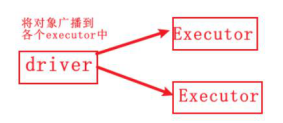
- 在driver中定义一个广播变量
obj对象需要支持序列化 val obj =new XXX val bc = sc.broadCast(obj) - 注意obj需要序列化,因为要从driver端网络传输到各个Executor端
- 在分布式的Executor的代码汇总获取对象
rdd.map(x=>{ //次obj是经过网络传输后反序列化后的 val obj =bc.value }) - spark 默认是将对象广播扫executor的每个task中,随着task数量增加,网络的传输压力也会增加,但是executor的数目比task要少很多,更适合将对象广播到executor中 ,executor 中的所有task都共享这个变量
Accumulator 累加器
- 多个节点对同一个变量进行累加操作,spark目前只支持累加操作
- spark有3个原生的累加器 : LongAccumulator ,DoubelAccumulator ,CollectionAccumulator
- 还可以自定义累加
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1092
1092

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









