







书山有路勤为径,学海无涯苦作舟

一、字符串的基本操作
1.1脱去多余字符
左右同时脱去
input_str = '今天天气真不错,风和日丽 '
input_str.strip()
'今天天气真不错,风和日丽'
左脱去、右脱去
input_str = ' 今天天气真不错,风和日丽 '
input_str.rstrip()
input_str = ' 今天天气真不错,风和日丽 '
input_str.lstrip()
' 今天天气真不错,风和日丽'
今天天气真不错,风和日丽 '
1.2 替换
input_str = 'A今天天气真不错,风和日丽A'
input_str.replace('今天','明天')
'A明天天气真不错,风和日丽A'
替换空字符
input_str = 'A今天天气真不错,风和日丽A'
input_str.replace('今天','')
‘A天气真不错,风和日丽A’
1.3 查找
input_str='今天天气真不错'
input_str.find('天气')
输出的是字符位置
2
1.4 判断
input_str = 'asdf'
input_str.isalpha()
input_str = '123'
input_str.isdigit()
True
True
1.5 分割与合并
input_str = '今天 天气 真的 不错 '
new_list = input_str.split(' ')
new_list
[‘今天’, ‘天气’, ‘真的’, ‘不错’, ‘’]
"".join(new_list)
‘今天天气真的不错’
'A'.join(new_list)
‘今天A天气A真的A不错A’
二、正则表达式
2.1正则查询表
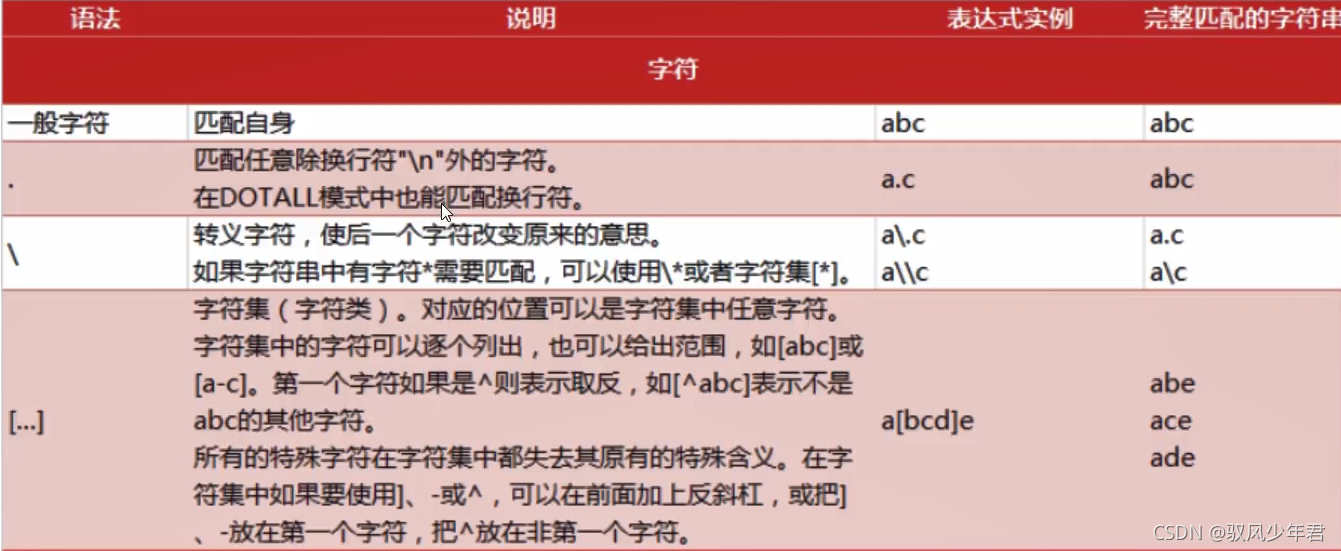
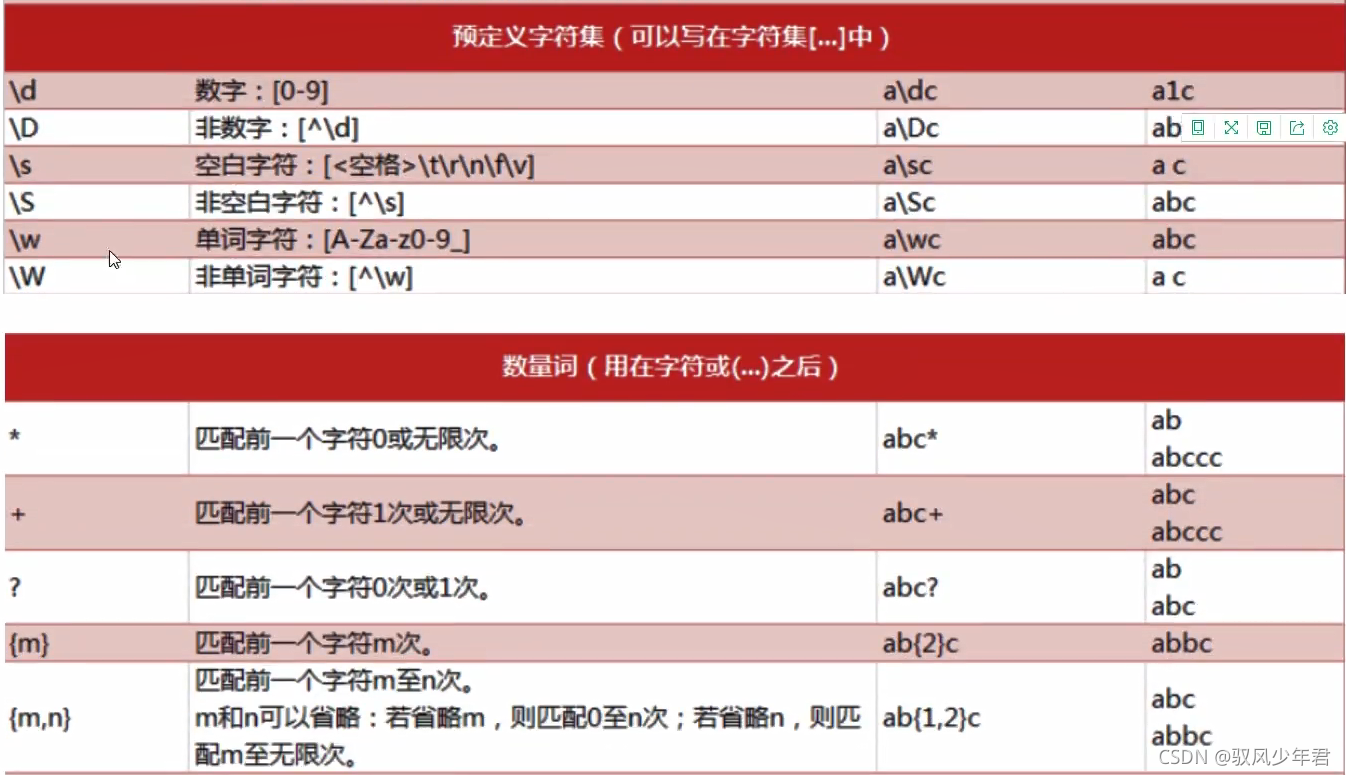
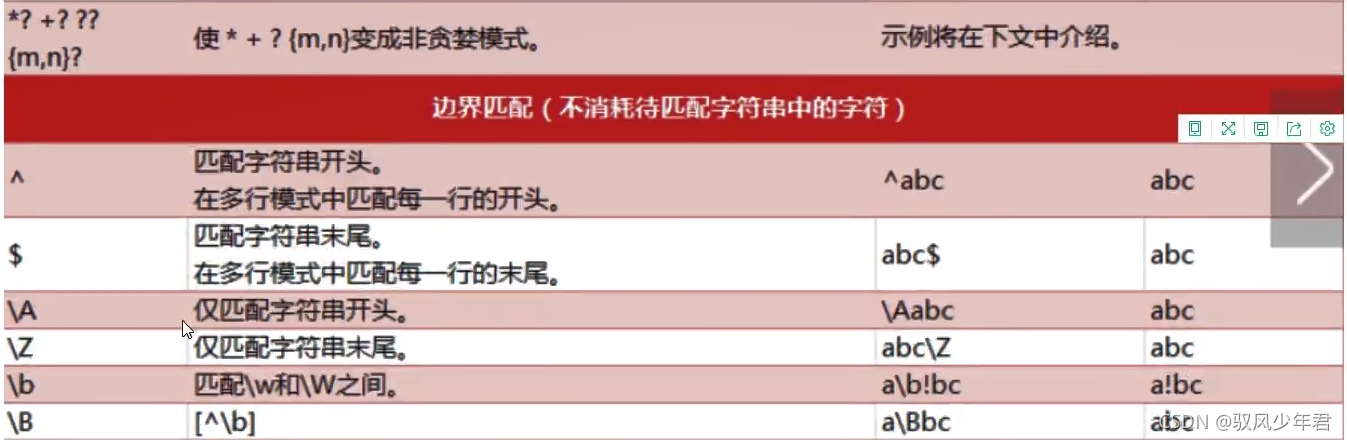
2.2 正则的规则
2.2.1 字符的匹配

import re
input = '自然语言处理很重要。 12abc789'
pattern = re.compile(r".")
re.findall(pattern,input)
[‘自’,
‘然’,
‘语’,
‘言’,
‘处’,
‘理’,
‘很’,
‘重’,
‘要’,
‘。’,
’ ',
‘1’,
‘2’,
‘a’,
‘b’,
‘c’,
‘7’,
‘8’,
‘9’]

一个[]只代表一个字符
pattern = re.compile(r"[abc]")
re.findall(pattern,input)
[‘a’, ‘b’, ‘c’]

pattern = re.compile(r"[a-zA-Z]|[0-9]")
re.findall(pattern,input)
[‘1’, ‘2’, ‘a’, ‘b’, ‘c’, ‘7’, ‘8’, ‘9’]
匹配数字‘\d’等价于[0-9]
pattern = re.compile(r"\d")
re.findall(pattern,input)
[‘1’, ‘2’, ‘7’, ‘8’, ‘9’]
2.2.2 量词
2.2.2.1 模糊量词
- ’*’ :0次后者多次
pattern = re.compile(r"\d*")
re.findall(pattern,input)
[’’, ‘’, ‘’, ‘’, ‘’, ‘’, ‘’, ‘’, ‘’, ‘’, ‘’, ‘12’, ‘’, ‘’, ‘’, ‘789’, ‘’]
- “+” :一次或者多次
pattern = re.compile(r"\d+")
re.findall(pattern,input)
[‘12’, ‘789’]
- ’?’: 0或者1次
pattern = re.compile(r'\d?')
re.findall(pattern,input)
2.2.2.1 精确量词
- 精确匹配 {m}次
pattern = re.compile(r'\d{3}')
re.findall(pattern,input)
[‘789’]
- {m,n}’匹配最少m次,最多n次。(n>m)
pattern = re.compile('\d{1,3}')
re.findall(pattern,input)
[‘12’, ‘789’]
2.2.2.3 match 与search的区别:
它们的返回不是一个简单的字符串列表,而是一个MatchObject,可以得到更多的信息。
如果匹配不成功,它们则返回一个NoneType。所以在对匹配完的结果进行操作之前,必需先判断一下是否匹配成功了。
match从字符串的开头开始匹配,如果开头位置没有匹配成功,就算失败了;而search 会跳过开头,继续向后寻找是否有匹配的字符串。
input2 = '123自然语言处理'
pattern = re.compile(r"\d")
match = re.match(pattern,input2)
match,group()
1
2.3 常用函数
2.3.1 字符串的替换
在目标字符串中规格规则查找匹配的字符串,再把它们替换成指定的字符串。你可以指定一个最多替换次数,否则将替换所有的匹配到的字符串。
sub ( rule , replace , target [,count] )
subn(rule , replace , target [,count])
第一个参数是正则规则,第二个参数是指定的用来替换的字符串,第三个参数是目标字符串,第四个参数是最多替换次数。
sub返回一个被替换的字符串
subn返回一个元组,第一个元素是被替换的字符串,第二个元素是一个数字,表明产生了多少次替换。
input2 = '123自然语言处理'
pattern = re.compile(r"\d")
re.sub(pattern,'数值',input2)
‘数值数值数值自然语言处理’
input2 = '123自然语言处理'
pattern = re.compile(r"\d")
re.subn(pattern,'数值',input2)
(‘数值数值数值自然语言处理’, 3)
2.3.2 过滤操作
input2 = '123自然语言处理'
pattern = re.compile(r"\d")
re.sub(pattern,'',input2)
‘自然语言处理’
2.3.3 split切片函数。使用指定的正则规则在目标字符串中查
找匹配的字符串,用它们作为分界,把字符串切片。
split( rule , target [,maxsplit])
第一个参数是正则规则,第二个参数是目标字符串,第三个参数是最多切片次数,返回一个被切完的子字符串的列表
input3 = '自然语言处理123机器学习456深度学习'
pattern = re.compile(r'\d+')
re.split(pattern,input3)
[‘自然语言处理’, ‘机器学习’, ‘深度学习’]
2.3.4 分组
- ‘(?P<组名>)命名组名’
pattern = re.compile(r"(?P<dota>\d)(?P<lol>\D+)")
m = re.search(pattern,input3)
m.group("dota")
‘123’
# 筛选号码
#要有括号括起来
import re
input = 'number 338-343-220'
pattern = re.compile(r'(\d\d\d-\d\d\d-\d\d\d)')
m = re.search(pattern,input)
print(m.groups())
(‘338-343-220’,)
三、NLTK
3.1 nltk的安装
import nltk
nltk.download()
3.2 英文分词
from nltk.tokenize import word_tokenize
from nltk.text import Text
input_str = "Today's weather is good.very windy and sunny,we has no classes"
tokens = word_tokenize(input_str)
3.3 单词转为小写
tokens = [word.lower() for word in tokens]
3.4 Text 对象
t = Text(tokens)
# 统计某个词的个数
t.count('good')
# 统计位置
t.index('good')
# 将前8个词频高的词汇输出
t.plot(8)
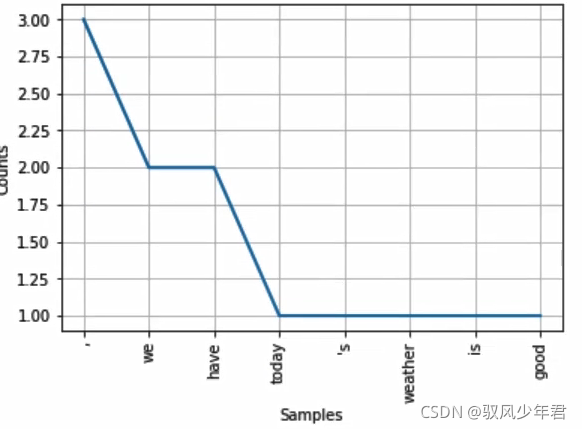
3.5 停用词
from nltk.corpus import stopwords
stopwords.readme().replace('\n',' ')
stopwords.fileids()
stopwords.raw('english').replace('\n','')
test_words = [word.lower() for word in tokens]
test_words_set = set(test_words)
查看原始集与停用词的交际交集
test_word_set.intersection(set(stopword.words('english')))
过滤停用词
filtered = [w for w in test_words_set if (w not in stopword.word('english'))]
filtered
3.6词性标注
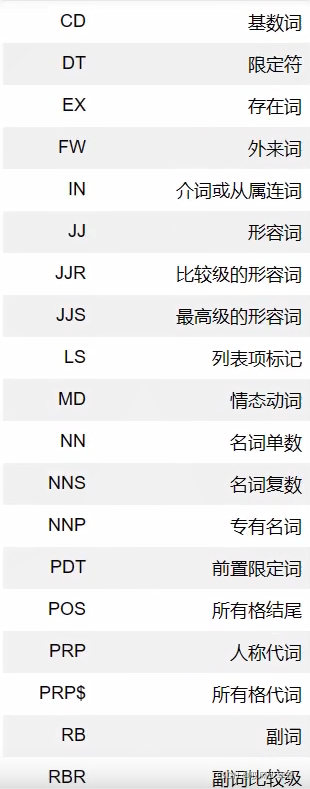
from nltk import pos_tag
tags = pos_tag(token)
tags
``
## 3.7 分块
```python
from nltk.chunk import RegexParser
sentence = [(' the','DT'),('little','JJ'), ('yellow','JJ'),(' dog', ' NNV') , ('diedl',' VBD')]
grammer ="MY_NP: {<DT>?<JJ>*<N>}"
cp =nltk.RegexpParser(grammer)#生成规则
result = cp. parse(sentence)#进行分块
print (result)
result.draw()#调用matplotlib库画出来
3.7 命名实体识别
from nltk import ne_chunk
sentence = "Edison went to Tsinghua University today"
print(ne_chunk(pos_tag(word_tokenize(sentence))))


















 1831
1831

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











