







 本文探讨了深度学习中归一化方法的作用,包括Normalization、BatchNormalization、LayerNormalization、InstanceNormalization和GroupNormalization。归一化能加快梯度下降速度,避免梯度消失问题,但可能限制非线性学习。BatchNormalization通过动态调整数据分布解决了这一问题。
本文探讨了深度学习中归一化方法的作用,包括Normalization、BatchNormalization、LayerNormalization、InstanceNormalization和GroupNormalization。归一化能加快梯度下降速度,避免梯度消失问题,但可能限制非线性学习。BatchNormalization通过动态调整数据分布解决了这一问题。
深度学习中的归一化方法总结:
- Normalization
- Batch normalization
- Layer Normalization
- Instance Normalization
- Group Normalization
Normalization
网络层越深,发现网络的数据的分布发生偏移(internal covariate shift 内部协变量偏移),因此,采用归一化方法可以是数据分布集中在激活函数0-1上(网络输出的白化处理whitening activation Neural Net-works: Tricks of the trade. LeCun etal),使得训练的过程中梯度下降更快,同时也能避免sigmod等函数出现梯度消失、爆炸的问题。
但是,使用Normalization后,每层的数据分布相同,意味着是一个线性学习的过程,这让原来的网络不能够学习非线性的特征,因此,Batchnormalization被提出来解决这个问题。
BatchNormalization
在batchnormalization之前是有一些方案解决internal covariate shift的,但是计算量较大,而且不是处处可微,因此这篇文章的设计了一个替代方案。
首先说明一下,几个问题:
- training和val过程是参数不一样的,training的参数(主要是E,Var)是由一个batch决定的,而val时BN的参数是将每个B作为一个样本集,对所有的B做样本的无偏估计作为E、Var;
- training过程是有反向传播的;
- 总的思想是,对输入的X进行归一化处理,简单的说就是X-N(u,var2)变为X’-N(0,1),而后面的y=gamma*x冒+beta,个人理解是gamma和beta作为参数是网络的训练内容,而进行分类任务是,有效的特征体现在数据的均值和方差上,激活层所表示的非线性特征通过这两个参数得以保存,val使用的正是网络训练的值。
- BN处理时采用了减去了均值,所以在卷积时,bias没有存在的意义。整个卷积可以表示为g(bn(wx))

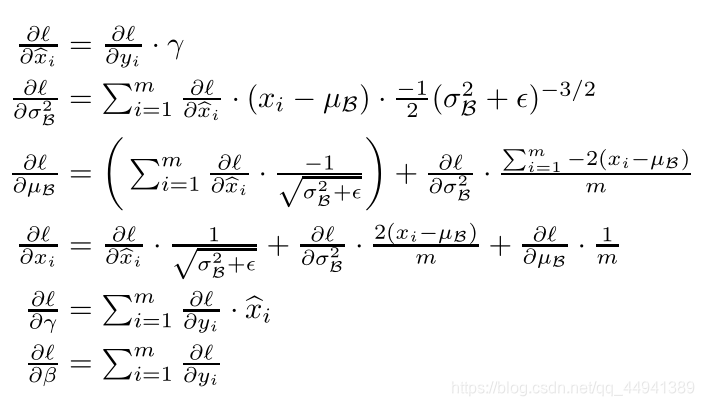
训练过程:

文章主要内容是这些,其余实现和方法的优势介绍。


















 2497
2497

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











