【人工智能概论】 用Python实现数据的归一化
一. 数据归一化处理的意义
- 多特征数据集常会遇到这样的问题,不同特征间的取值范围往往有很大的差别,甚至是存在数量级方面的差异,这很有可能会导致深度学习算法精确度的降低,因此对数据进行归一化处理是很有意义的。
二. 常见的归一化方法
2.1 最大最小标准化(Min-Max Normalization)
- 公式:
x
′
=
x
−
m
i
n
(
x
)
m
a
x
(
x
)
−
m
i
x
(
x
)
x^{'} = \frac{x - min(x)}{max(x)-mix(x)}
x′=max(x)−mix(x)x−min(x)
- 这是一种线性映射的方法,将原始数据线性映射到[0 1]的范围内, X为原始数据;
- 比较适用于数值比较集中的情况;
- 缺陷:如果max和min不稳定,很容易使得归一化结果不稳定;
2.2 z-score 标准化
- 公式:
x
∗
=
x
−
μ
σ
x^{*} = \frac{x - \mu}{\sigma }
x∗=σx−μ其中,μ、σ分别为原始数据的均值和方差。
- 将原始数据归一化为均值为0、方差1的数据;
- 该方法要求原始数据的分布近似为高斯分布,否则归一化的效果会变得很糟糕。
三. 用sklearn实现归一化
import pandas as pd
import numpy as np
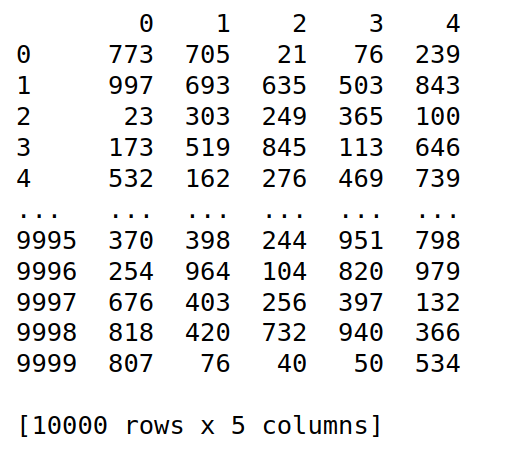
x=np.random.randint(1,1000,(10000,5))
x=pd.DataFrame(x)
print(x)
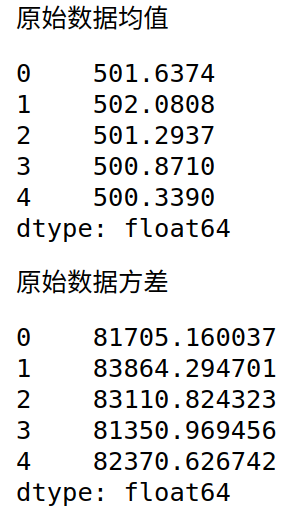
print("原始数据均值")
display(x.mean())
print("原始数据方差")
display(x.var())
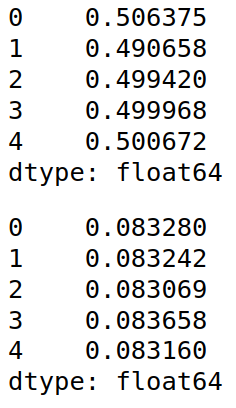
- 最大最小标准化(Min-Max Normalization)
from sklearn.preprocessing import MinMaxScaler
x_min=MinMaxScaler().fit_transform(x)
x_min=pd.DataFrame(x_min)
display(x_min.mean())
display(x_min.var())
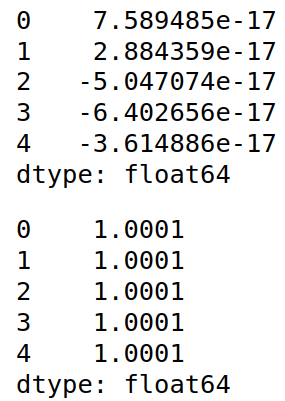
from sklearn.preprocessing import StandardScaler
x_std=StandardScaler().fit_transform(x)
x_std=pd.DataFrame(x_std)
display(x_std.mean())
display(x_std.var())








 文章介绍了数据归一化在处理多特征数据集中的重要性,特别是对于有数量级差异的情况。讨论了两种常见的归一化方法:最大最小标准化和z-score标准化,以及它们的适用场景和优缺点。接着,通过sklearn库展示了如何在Python中实现这两种数据归一化的例子。
文章介绍了数据归一化在处理多特征数据集中的重要性,特别是对于有数量级差异的情况。讨论了两种常见的归一化方法:最大最小标准化和z-score标准化,以及它们的适用场景和优缺点。接着,通过sklearn库展示了如何在Python中实现这两种数据归一化的例子。

















 1081
1081

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









