







1、引言
一些 X-formers 从以下几个方面提升了vanilla Transformer 的性能:模型的效率、模型泛化、模型适应性
2、背景
2.1 vanilla Transformer
The vanilla Transformer 是一种sequence-to-sequence 的模型。由 一个encoder和 一个decoder组成, (encoder和decoder都是由L个相同的块堆叠而成)。
encoder块是由多头自注意力模块和 position-wise FFN组成。为了构建更深层次的网络,层归一化后使用残差网络。
decoder块在多头自注意力模块和 position-wise FFN中加了一个交叉注意力模块。
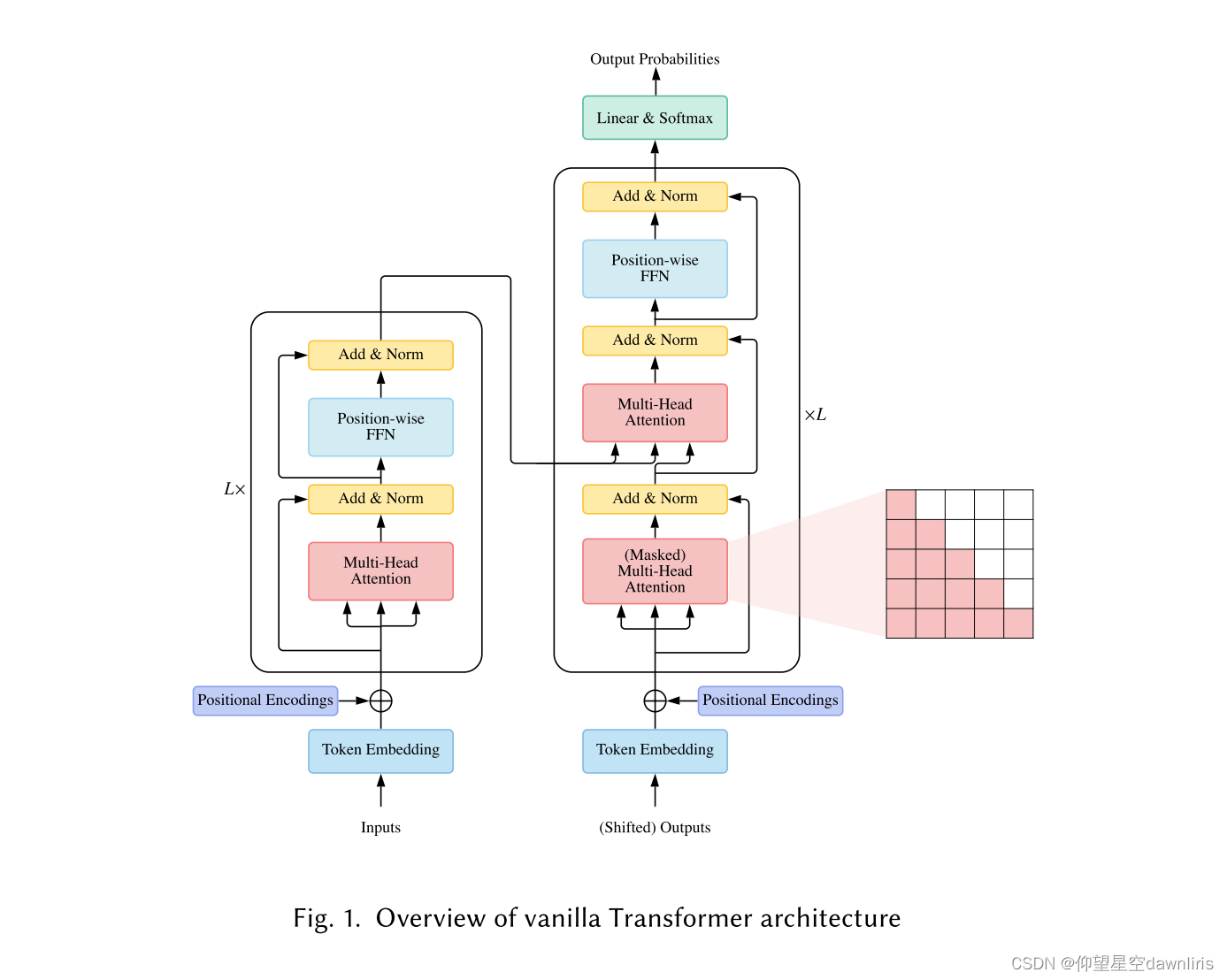
2.1.1注意力模块
the scaled dot-product attention used by Transformer is given by
![]() (式1)
(式1)
Query-Key-Value (QKV)
Q ∈; K ∈
;V ∈
N,M :queries and keys (or values)长度; and
: keys (or queries) and values的维度;
A:注意力矩阵
式中的是为了减轻softmax函数的梯度消失问题
multi-head attention
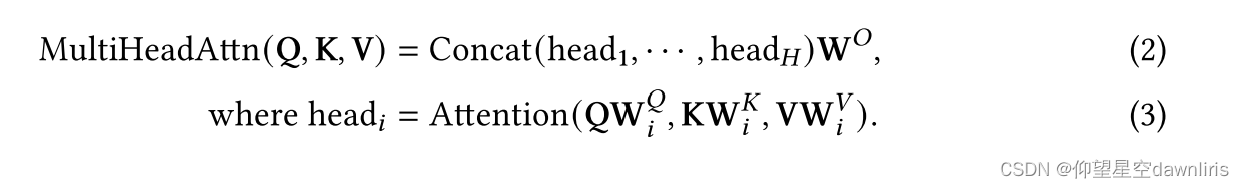
式2将queries, keys and values由维投射到
、
、
维;式3又将其还原为
维
分类:
依据q、k、v的来源分为三种:
- Self-attention :式1 Q = K = V = X
- Masked Self-attention:parallel training:
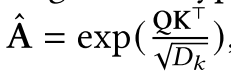
- Cross-attention:The queries are projected from the outputs of the previous (decoder) layer, whereas the keys and values are projected using the outputs of the encoder
2.1.2 Position-wise FFN.
实质是全连接前馈模块
![]()
H′ is the outputs of previous layer
2.1.3 Residual Connection and Normalization.
每个模块都加了一个残差网络
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 2319
2319

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









