




论文研读来源A Survey of Transformers (arxiv.org)
摘要
文章行文顺序:
首先,简短的介绍最基本的transformer,然后提出X-formers的新的分类方法
之后,从三个方面介绍X-formers:模型变化、预训练、应用
最后,提出一些未来的研究方向
1 引言
Transformer 最初是作为机器翻译的序列到序列模型提出的。后来的工作表明,基于 Transformer 的预训练模型可以在各种任务上实现最先进的性能。Transformer 已成为 NLP 中的首选架构,尤其是对于 PTM。(Transformer-based pre-trained models)
这些 X-formers 从不同的角度改进了原版 Transformer。
- Model Efficiency.长序列计算注意力导致很高的计算代价,改进方法包括轻量级注意力(sparse attention variants),分治方法(recurrent and hierarchical mechanism)。【个人认为FFN的阶段,参数规模不亚于计算注意力的时候】
- Model Generalization.由于输入数据的结构偏差,很难在小规模的数据集上进行训练。改进方法主要包括引入结构偏差,或者正则化、在大规模无标签的数据上进行预训练
- Model Adaptation.在下游任务中应用Transformer
上述分类方法比较含糊,可能出现一个改进的模型出现在多个类别。因此提出全新的分类方法:architecture modification, pre-training, applications
2 背景
2.1 原始Transformer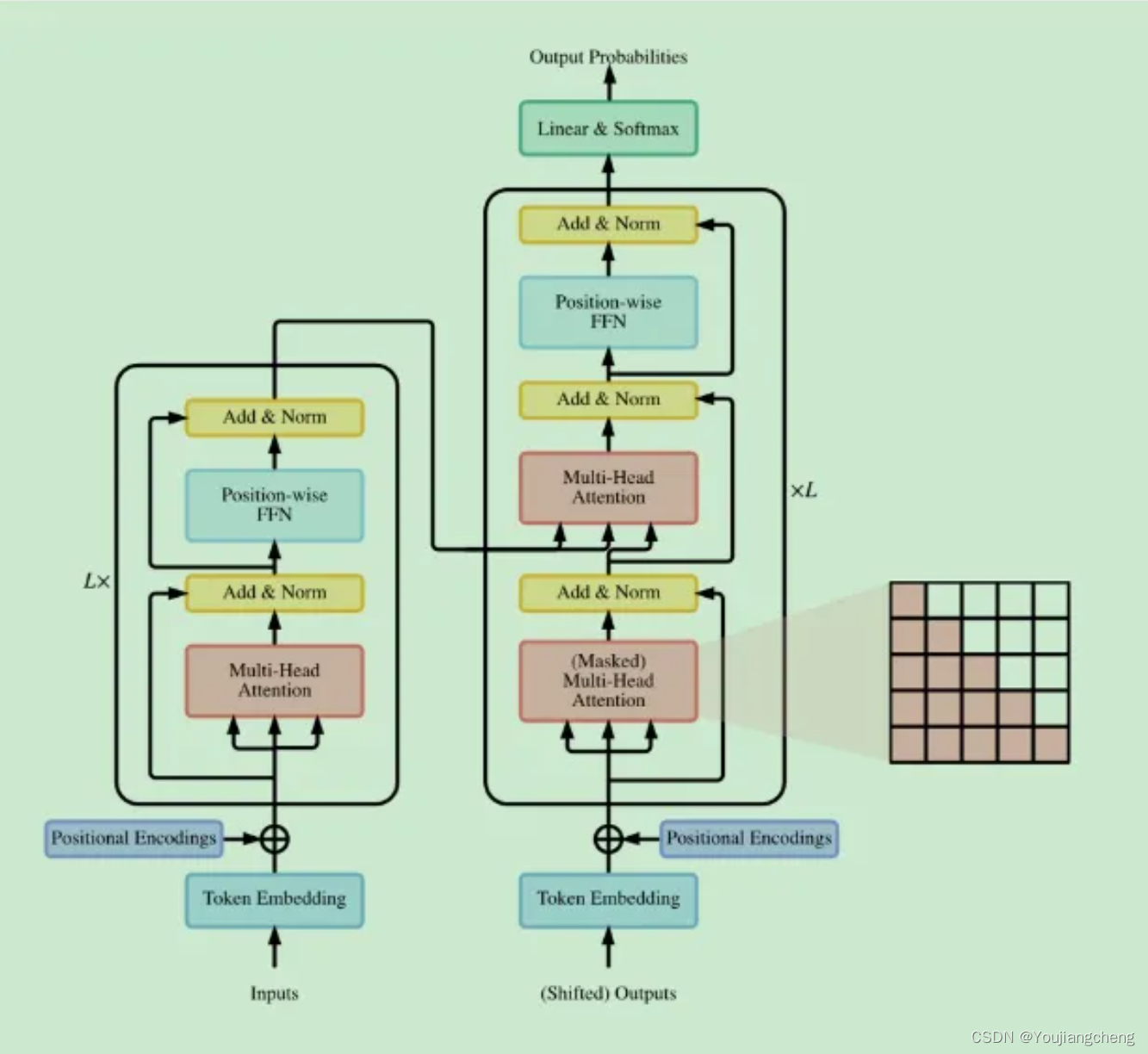
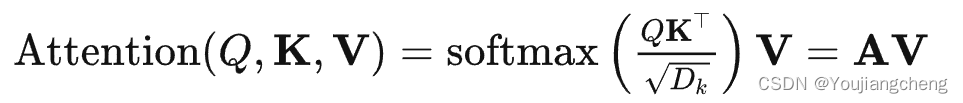
A:注意力权重矩阵
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2400
2400




 到【灌水乐园】发言
到【灌水乐园】发言







