







 本文介绍了强化学习中的策略梯度方法,通过神经网络表示策略π,并利用环境交互数据来优化网络参数θ以最大化期望奖励。讨论了轨迹概率、回合奖励目标以及梯度上升策略。此外,提到了两种实用技巧:基线方法用于降低样本方差,并通过动作的未来奖励权重区分动作价值;还介绍了使用交叉熵损失函数进行网络优化。
本文介绍了强化学习中的策略梯度方法,通过神经网络表示策略π,并利用环境交互数据来优化网络参数θ以最大化期望奖励。讨论了轨迹概率、回合奖励目标以及梯度上升策略。此外,提到了两种实用技巧:基线方法用于降低样本方差,并通过动作的未来奖励权重区分动作价值;还介绍了使用交叉熵损失函数进行网络优化。
基本概念
1. 策略π , 用一个网络 表示,θ 是网络的参数。网络 输入 observation 的状态 ,输出 动作 的概率分布。
2.一条轨迹,是由 环境输出 s状态 和 actor 输出的动作 a 组成 ,可以 存在 状态转移概率【取决于环境,不可控】 和 策略(本身是概率) 【actor 控制的 ,取决于 策略的参数 θ 】 因此可以计算出 一条轨迹发生的概率

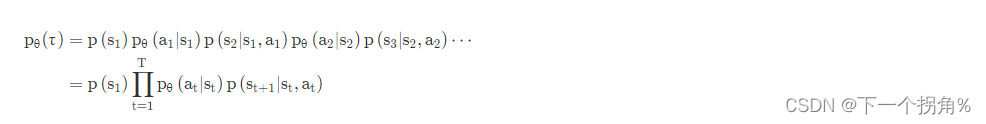
3. 一个回合的奖励 R,目的:调整 内部参数 θ 使得 R 越大越好。
R 是一个随机变量 ,所以无法直接计算 ,能够计算的 是 R 的的期望 。给定一组参数 θ,得到的期望为

最大化的手段——》梯度上升【更新参数 θ】。所以先 求期望奖励的梯度:
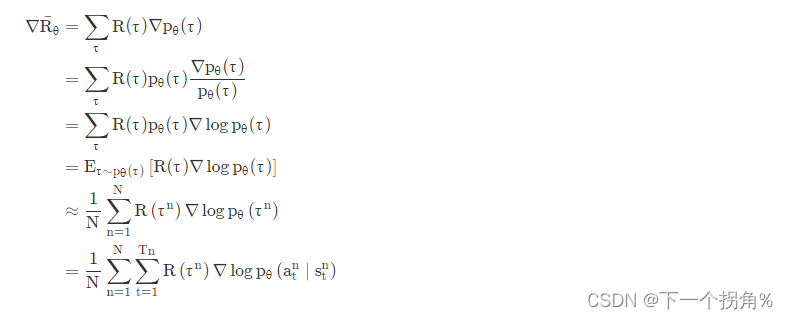
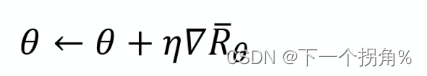
因为期望无法计算出来,所以采用 采样 的方式,让agent和环境互动 记录下来数据。数据每次只用一次,更新完一次 θ 。就在重新采样。
实现tips
1.baseline
解决问题:奖励总为 正 的情况。削弱 采样 带来的样本不充分 导致 的有些动作 概率 下降 【MC 方差大】。
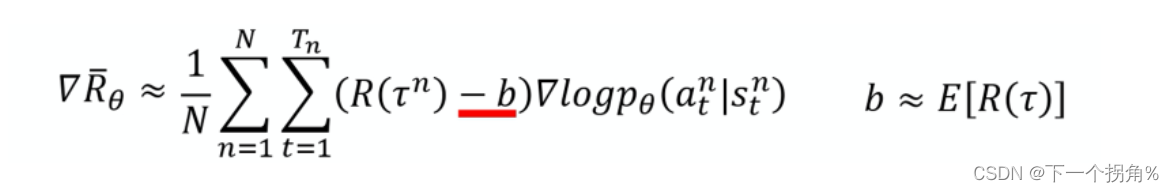
这里 b 是 奖励值求期望,Sutton 的书中 用的 是状态价值函数 v'(St,w) ,会更新参数w。
2.给每个 动作 合适的分数
解决的问题: 之前 的权重 是 一场游戏(回合)的总奖励 ,相当于 这场游戏的 每个动作 被赋予 了相同的权重 ,但是 一场游戏里面肯定 有好动作 和坏动作 ,只是累计加和 的 回合 奖励 多还是少。
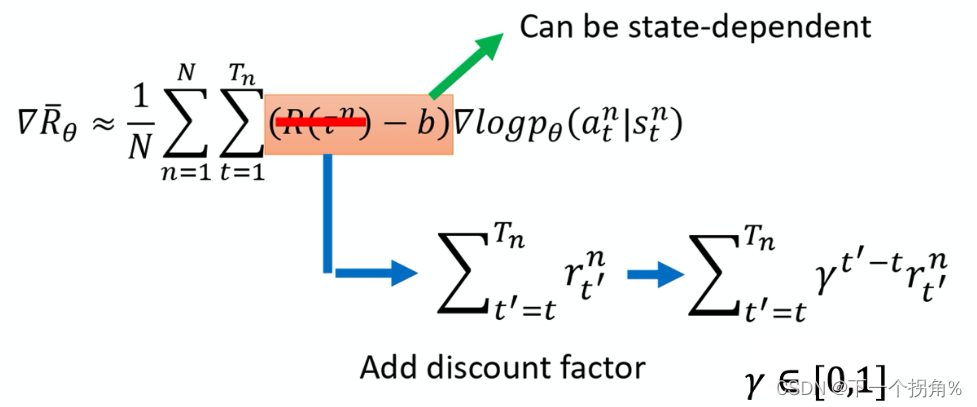
权重 改为 从某一个动作 执行到 以后的奖励。来区别对待 不同的动作。同时 ,加上 折扣因子γ。【一般设为 0.9 或 0.99】
其中,上式中 的 ![]()
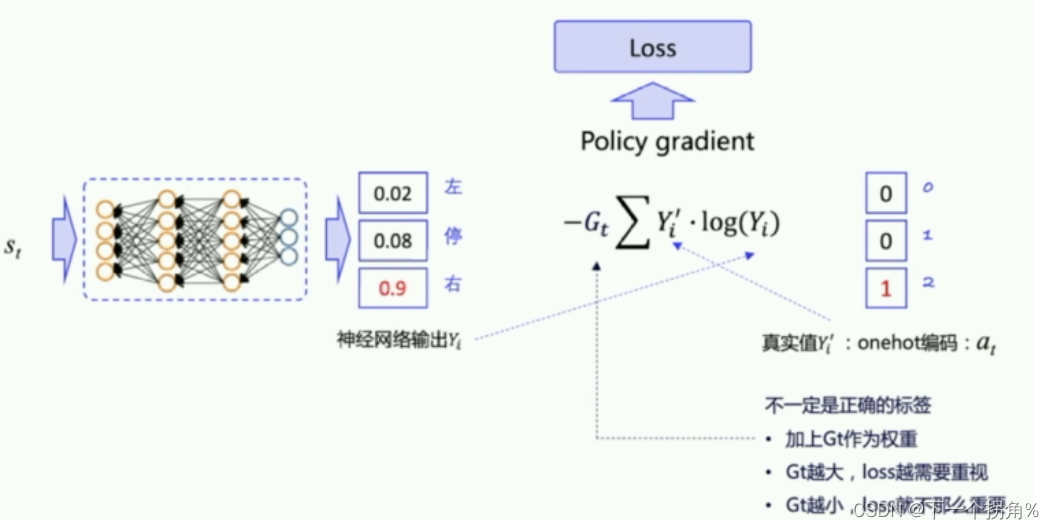
用 交叉熵 得到。
交叉熵 :来表示 两个 概率分布 之间的差距。作为 损失函数 loss ,传给 神经网络 的优化器 去优化。自动 求偏导 做神经网络参数优化。

















 5566
5566

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









