







 本文介绍了三种相关系数:Pearson、Spearman 和 Kendall 的区别及适用场景,并通过实例演示了如何使用 Python Pandas 计算不同数据类型之间的相关性。
本文介绍了三种相关系数:Pearson、Spearman 和 Kendall 的区别及适用场景,并通过实例演示了如何使用 Python Pandas 计算不同数据类型之间的相关性。

相关系数的类型:

三种相关系数区别以及计算:
两组数据间的相关性计算可以分为如下3种情况:
1 数值数据与分类数据
2 数值数据与数值数据
3 分类数据与分类数据
计算相关性用到的方法有pearson、spearman、kendall,具体区别如下表所示:
| 分析方法 | 数据类型 | 数据分布 | 数据间的关系 |
| pearson | 数值和数值 | 正态分布 | 线性 |
| spearman | 数值和数值 数值和分类 分类和分类 | 不做要求 | 不做要求 |
| kendall | 数值和数值 数值和分类 分类和分类 | 不作要求 | 不作要求 |
注:
kendall和spearman属于秩相关;
满足pearson相关系数的数据也可以用spearman计算;
kendall的结果偏小,不建议用。
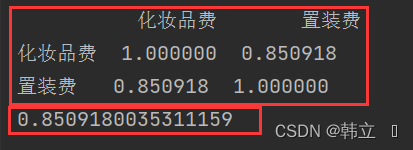
2.1 数值与数值的相关性
import pandas as pd
data = pd.DataFrame({'化妆品费': [30, 50, 120, 20, 70, 150, 50, 60, 80, 100],
'置装费': [70, 80, 250, 50, 120, 300, 100, 150, 20, 180]})
print(data.corr()) # 计算所有的变量的两两相关性
print(data['化妆品费'].corr(data['置装费'])) # 只计算选择的两个变量的相关性
2.2 数值与分类的相关性:(代码结果在注释里)
# 情况1:分类标签为数字
data = pd.DataFrame({'id': [3, 2, 1, 1, 2, 3, 2, 3, 1, 1, 2, 3, 1, 2, 1],
'age': [27, 33, 16, 29, 32, 23, 25, 28, 22, 18, 26, 26, 15, 29, 26]})
print('pearson:', data['id'].corr(data['age'])) # pearson: 0.4465155114816965
print('spearman', data['id'].corr(data['age'], method='spearman')) # spearman 0.4016086046008866
print(data.corr(method='spearman'))
"""
id age
id 1.000000 0.401609
age 0.401609 1.000000
"""
# 情况2:分类标签为字符串
data1 = pd.DataFrame({'id': ['c', 'b', 'a', 'a', 'b', 'c', 'b', 'c', 'a', 'a', 'b', 'c', 'a', 'b', 'a'],
'age': [27, 33, 16, 29, 32, 23, 25, 28, 22, 18, 26, 26, 15, 29, 26]})
print('spearman', data1['id'].corr(data1['age'], method='spearman')) # spearman 0.40160860460088662.3 分类与分类的相关性:(基本不用)
data1 = pd.DataFrame({'id': ['c', 'b', 'a', 'a', 'b', 'c', 'b', 'c', 'a', 'a', 'b', 'c', 'a', 'b', 'a'],
'age': ['1', '2', '3', '3', '2', '1', '2', '3', '1', '1', '2', '3', '1', '2', '1']})
print('kendall', data1['id'].corr(data1['age'], method='kendall'))
print('spearman', data1['id'].corr(data1['age'], method='spearman'))
# 输出
# kendall 0.1891891891891892
# spearman 0.19191919191919193


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









