







标题
一、二步为介绍,如果想要看怎样接入本地知识库,可直接从 第三步:AnythingLLM 安装 开始
一、RAG介绍
RAG 知识库概述
1. 定义
RAG(Retrieval-Augmented Generation)是一种结合检索技术与生成模型的自然语言处理方法,通过引入外部知识库提升系统回复的准确性与信息量。
2. 核心原理
- 检索优先:生成回答前,先从知识库中检索相关信息(类似“开卷考试”)。
- 动态生成:基于检索结果,利用大语言模型生成最终回答。
3. 应用步骤
- 创建知识库
将原始数据转化为结构化存储形式(如向量数据库)。 - 查询知识库
通过向量检索等技术匹配最相关信息。 - 生成答案
结合检索结果与生成模型输出最终回答。
4. 应用场景
- 企业级产品:如 FastGPT 等即用型平台。
- 自定义项目:个人/团队用于学习、科研或商业场景。
5. GraphRAG 技术
- 微软提出:通过图谱化处理数据,增强语义关联性。
- 优势:提升检索精度。
- 局限:数据处理成本较高,依赖 AI 预处理。
本地部署 RAG 的优势
1. 数据隐私与安全
- 本地化存储:敏感数据无需上传至外部服务器,规避泄露风险。
- 完全控制:自主管理访问权限,确保信息私密性。
2. 高度定制化
- 私有知识库:按需构建专属知识库。
- 参数调优:灵活调整模型配置以适配特定需求。
3. 成本效益
- 一次性投入:避免云服务持续订阅费用。
- 零额外成本:无数据存储/处理附加费。
4. 离线可用性
- 无需网络:支持断网环境下运行,保障服务稳定性。
5. 检索效率提升
- 精准匹配:快速定位知识库关键信息。
- 智能生成:结合检索结果生成高质量回答。
6. 个性化适配
- 场景定制:自由配置功能模块以满足垂直领域需求(如医疗、金融)。
二、DeepSeek-R1 模型本地部署
首先需要先本地部署一下DeepSeek,这里可以参考我上一篇文章 :
DeepSeek R1+Windows本地部署,保姆级教程,小白也能轻松部署 低配电脑可用,让R1不在 “繁忙”
https://editor.youkuaiyun.com/md/?articleId=145796894
三、AnythingLLM 安装
AnythingLLM则是一个知识整合的智能助手,能够帮助用户快速部署和整合DeepSeek和其他大语言模型。通过AnythingLLM,用户可以更方便地创建和管理本地知识库,实现高效的知识管理和智能问答,它提供 Web 界面,易于管理和调用,适合个人和企业打造专属 AI 助手。
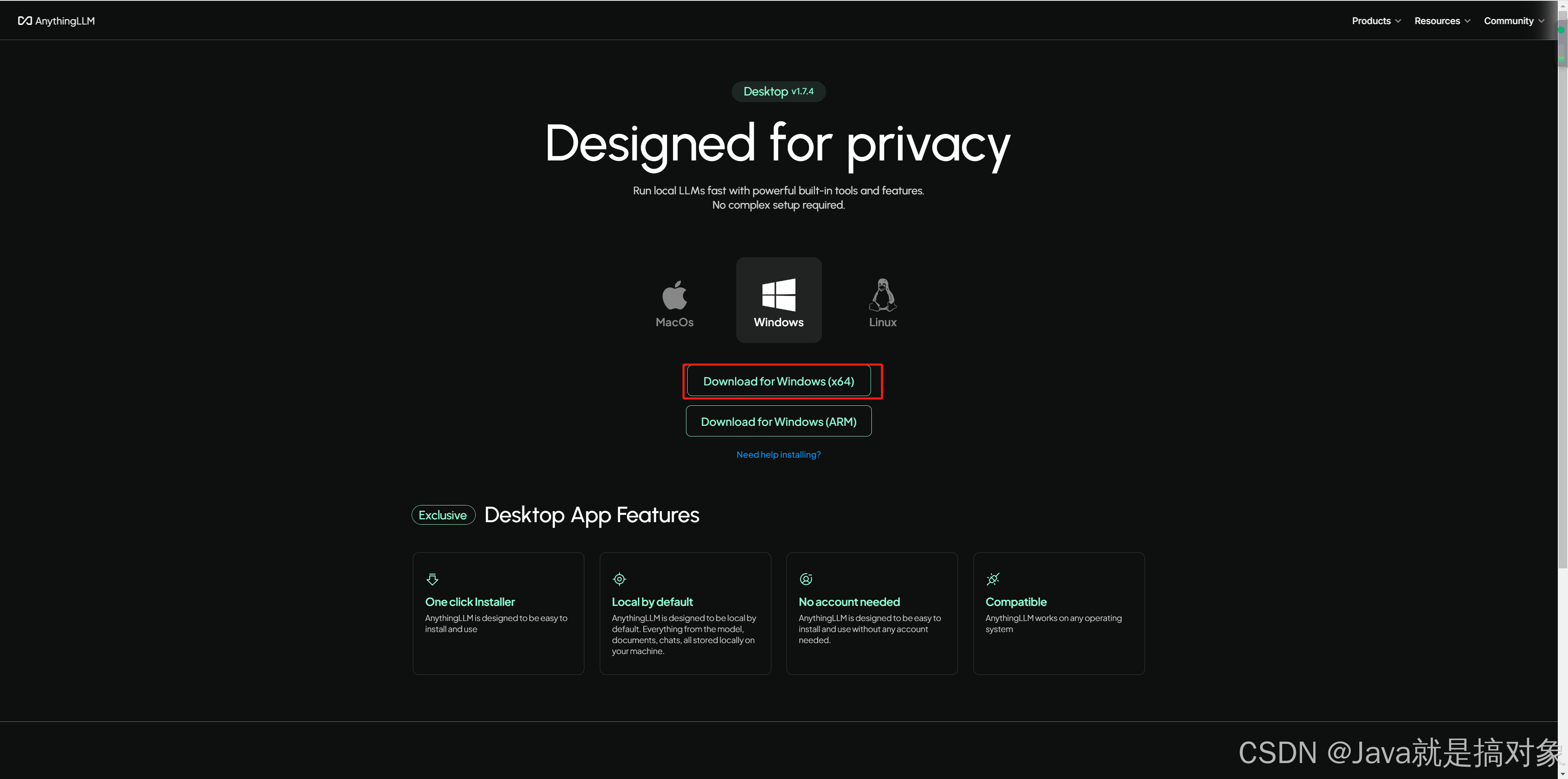
安装
下载完成后我们进行安装:
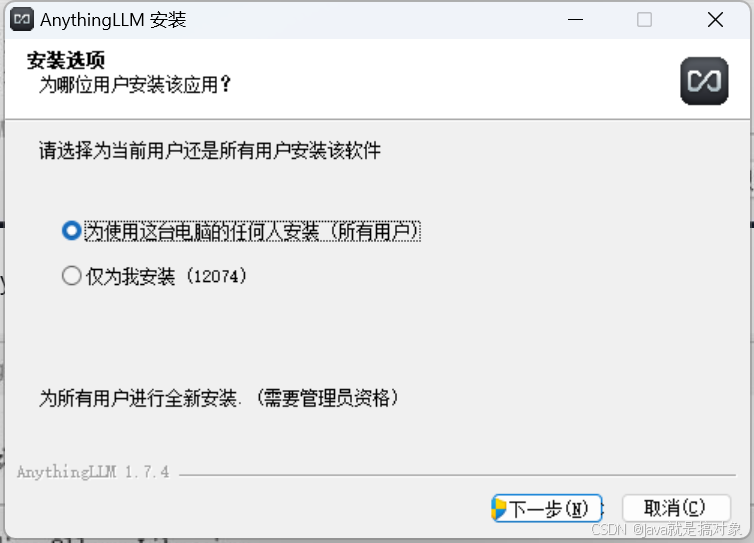

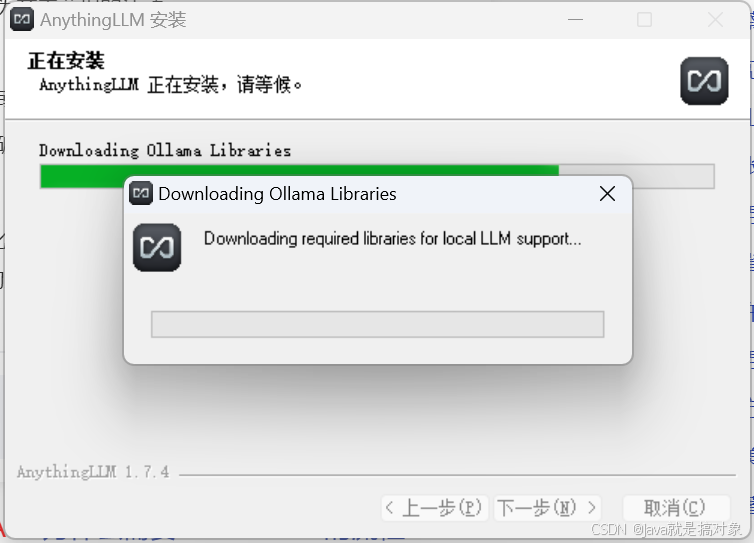
安装时一直下一步就行,安装过程中AnythingLLM会自动安装调用Ollama的库函数:
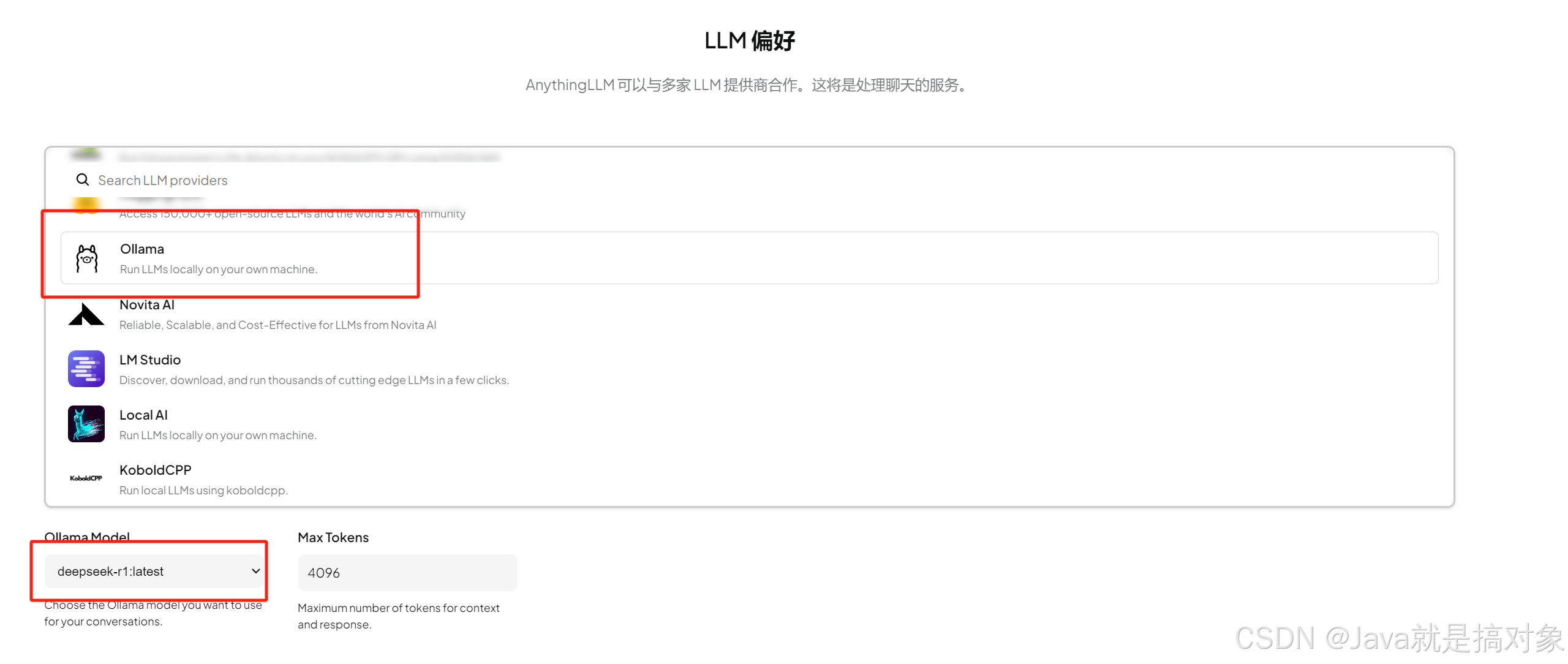
安装好开始配置 这里选Ollama 地址按它默认的填就行。
工作区名字随便取就行。
安装完成后,进入程序主界面,会有一段欢迎提示,如果觉得英文比较难读,可以通过点击左下角 扳手 按钮,
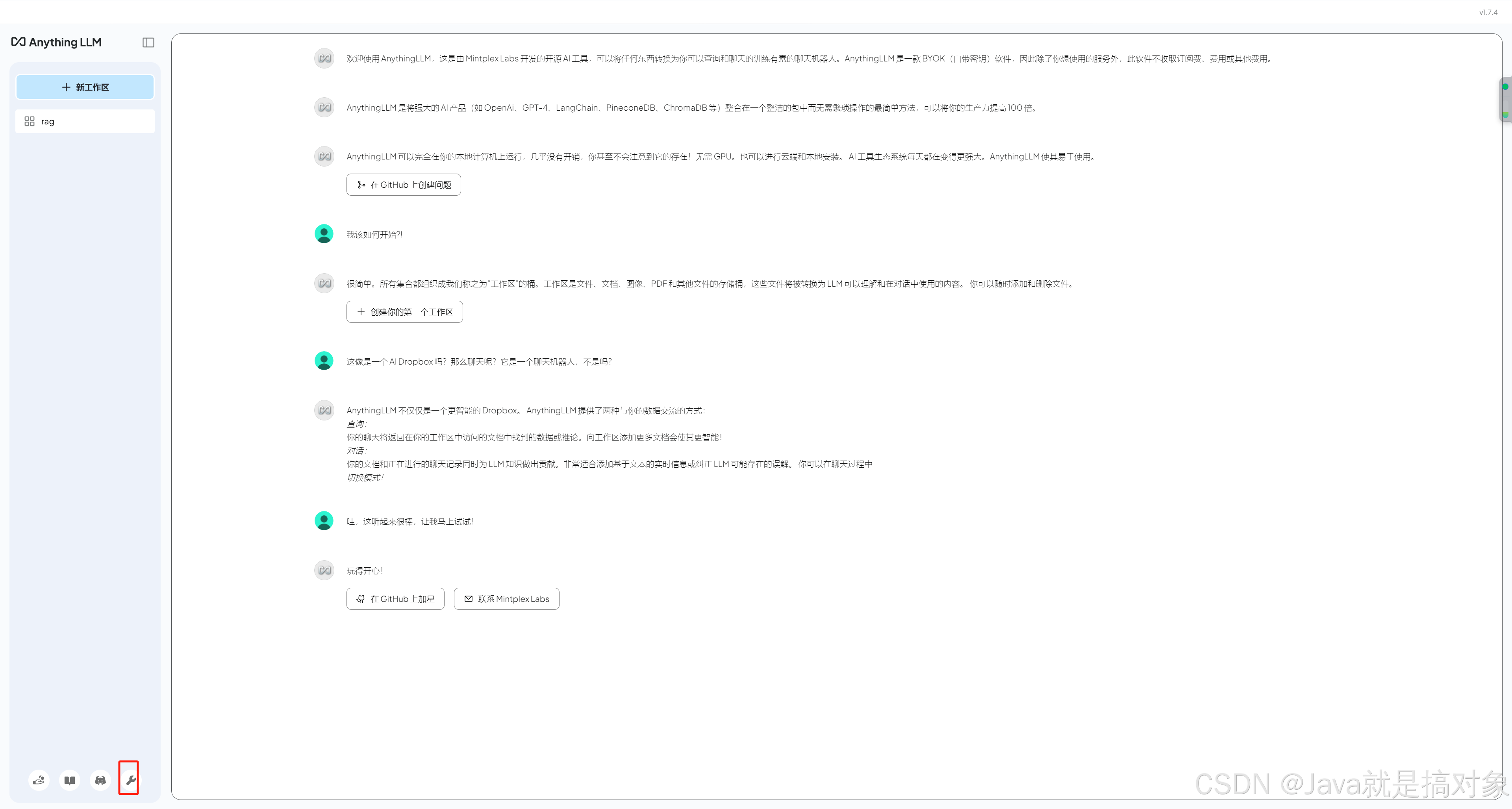
修改软件语言为中文
这个时候在底部对话框就可以进行对话了
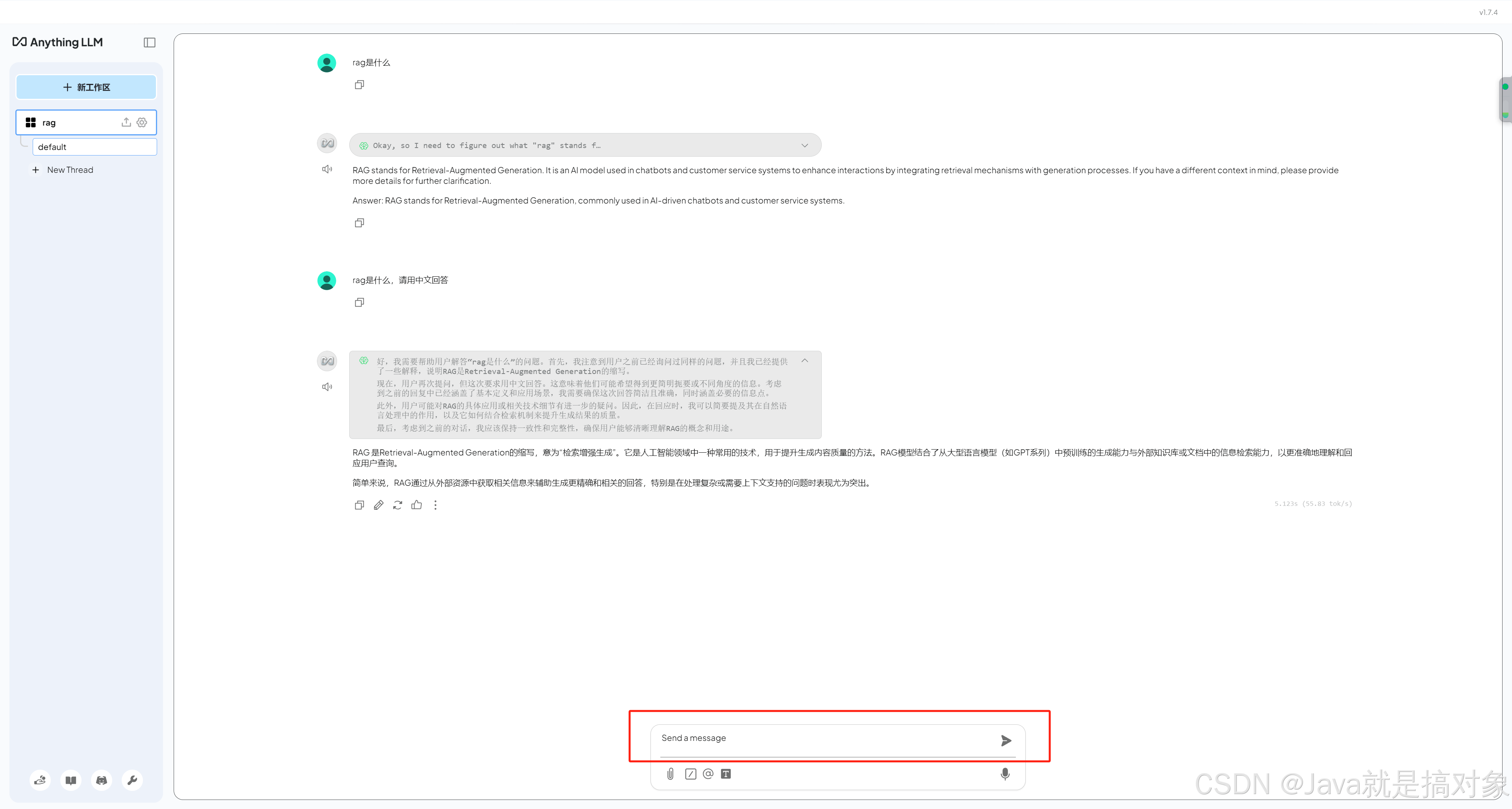
上面的回答就是 DeepSeek-R1:8B 模型默认的回答,大家可以看出回答的效果并不好
建立个人知识库
这个时候,我们可以将第一步的 什么是RAG 相关内容拷贝出来创建一个文档 测试Rag.docx
选择我们建立的Test工作区,上传此文档:
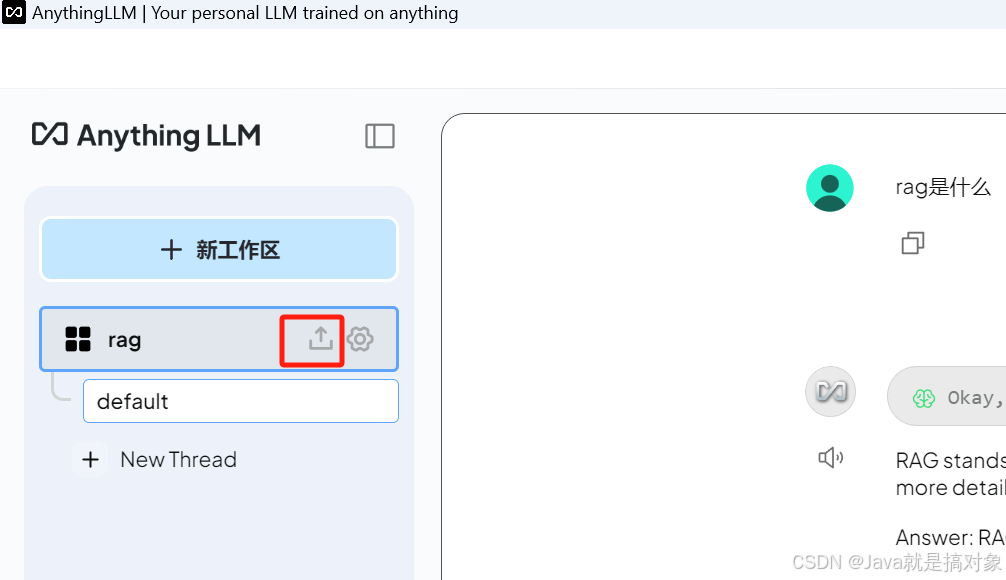
上传文档并准备移入工作区,如下图:
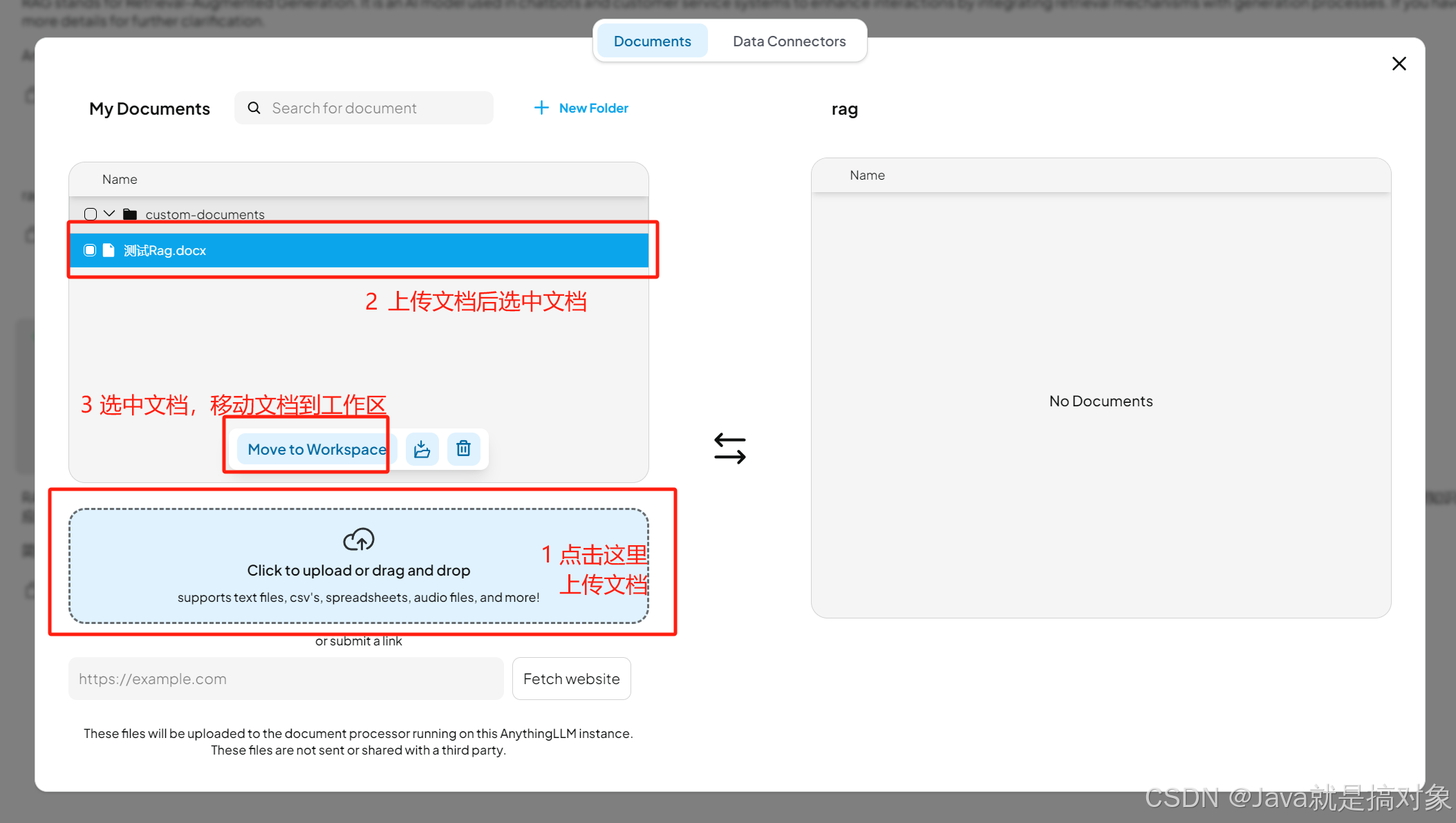
把文档移动到工作区,并点击Save and Embed,等系统处理完成:
文档 Embed = 把文本变成向量 + 存入数据库 + 进行相似搜索。它是 AI 知识库、搜索推荐、智能问答的核心技术,让 AI 理解文本语义,而不再只是匹配关键词。
测试Rag.docx文档的内容是:
本地部署 RAG 的优势
### 1. 数据隐私与安全
- **本地化存储**:敏感数据无需上传至外部服务器,规避泄露风险。
- **完全控制**:自主管理访问权限,确保信息私密性。
### 2. 高度定制化
- **私有知识库**:按需构建专属知识库。
- **参数调优**:灵活调整模型配置以适配特定需求。
### 3. 成本效益
- **一次性投入**:避免云服务持续订阅费用。
- **零额外成本**:无数据存储/处理附加费。
### 4. 离线可用性
- **无需网络**:支持断网环境下运行,保障服务稳定性。
### 5. 检索效率提升
- **精准匹配**:快速定位知识库关键信息。
- **智能生成**:结合检索结果生成高质量回答。
### 6. 个性化适配
- **场景定制**:自由配置功能模块以满足垂直领域需求(如医疗、金融)。
大模型结合上下文给我们的回答:
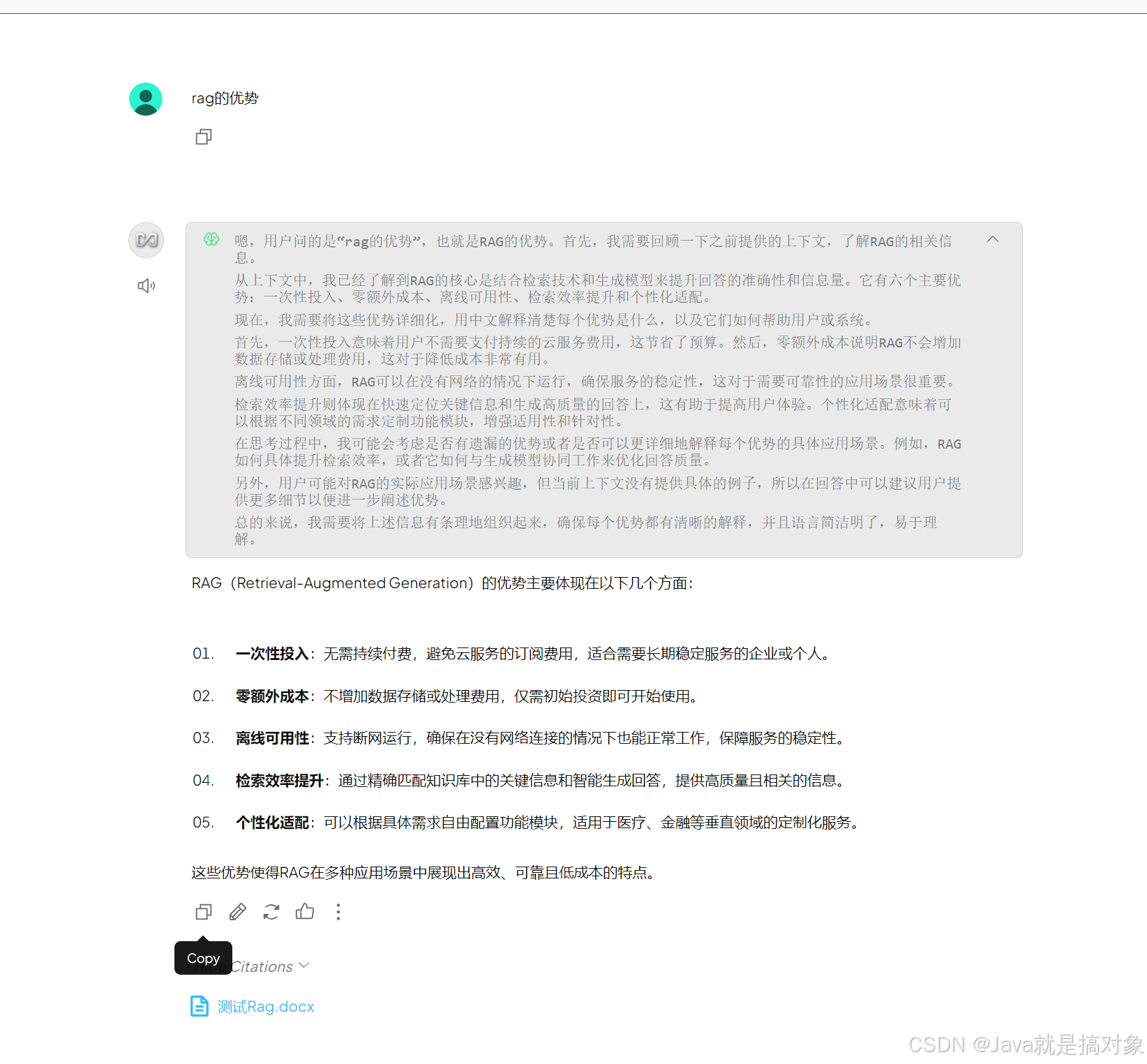
<think>
嗯,用户问的是“rag的优势”,也就是RAG的优势。首先,我需要回顾一下之前提供的上下文,了解RAG的相关信息。
从上下文中,我已经了解到RAG的核心是结合检索技术和生成模型来提升回答的准确性和信息量。它有六个主要优势:一次性投入、零额外成本、离线可用性、检索效率提升和个性化适配。
现在,我需要将这些优势详细化,用中文解释清楚每个优势是什么,以及它们如何帮助用户或系统。
首先,一次性投入意味着用户不需要支付持续的云服务费用,这节省了预算。然后,零额外成本说明RAG不会增加数据存储或处理费用,这对于降低成本非常有用。
离线可用性方面,RAG可以在没有网络的情况下运行,确保服务的稳定性,这对于需要可靠性的应用场景很重要。
检索效率提升则体现在快速定位关键信息和生成高质量的回答上,这有助于提高用户体验。个性化适配意味着可以根据不同领域的需求定制功能模块,增强适用性和针对性。
在思考过程中,我可能会考虑是否有遗漏的优势或者是否可以更详细地解释每个优势的具体应用场景。例如,RAG如何具体提升检索效率,或者它如何与生成模型协同工作来优化回答质量。
另外,用户可能对RAG的实际应用场景感兴趣,但当前上下文没有提供具体的例子,所以在回答中可以建议用户提供更多细节以便进一步阐述优势。
总的来说,我需要将上述信息有条理地组织起来,确保每个优势都有清晰的解释,并且语言简洁明了,易于理解。
</think>
RAG(Retrieval-Augmented Generation)的优势主要体现在以下几个方面:
1. **一次性投入**:无需持续付费,避免云服务的订阅费用,适合需要长期稳定服务的企业或个人。
2. **零额外成本**:不增加数据存储或处理费用,仅需初始投资即可开始使用。
3. **离线可用性**:支持断网运行,确保在没有网络连接的情况下也能正常工作,保障服务的稳定性。
4. **检索效率提升**:通过精确匹配知识库中的关键信息和智能生成回答,提供高质量且相关的信息。
5. **个性化适配**:可以根据具体需求自由配置功能模块,适用于医疗、金融等垂直领域的定制化服务。
这些优势使得RAG在多种应用场景中展现出高效、可靠且低成本的特点。
可以看出,AnythingLLM通过调用deepseek模型完成了知识问答
图片底部显示 Hide Citations表明,本次问答引用了我们之前上传的文档
通过使用Ollama、DeepSeek和AnythingLLM搭建本地知识库,我们不仅能够享受大模型带来的便利,还能够确保数据的安全性和隐私性。这种方法特别适合那些对数据保密有严格要求的企业和个人用户,同时也解决了在线DeepSeek不稳定的问题。
参考资料
https://blog.youkuaiyun.com/2401_84204207/article/details/145413949
https://zhuanlan.zhihu.com/p/22733349472
https://www.panziye.com/ai/13223.html

















 1666
1666

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









