






HRZ的序列

思路分析
这题刚开始是真的没看懂,但其实很简单。
因为所有三种以上不同的数字,其中有两种数字可以通过一加一减达成第三种数字,那第四种必定不可以通过任何操作等于第三种。
所以将这个数列去重后,若数字个数大于3则不可以,小于3肯定可以,当等于3时,若排序后为等差数列,则可以。
这里也是我第一次用set数组,以到达去重的目的,不过取set中值时要用到迭代器。
AC代码
#include<cstdio>
#include<set>
using namespace std;
int main()
{
int t;
scanf("%d",&t);
while(t--)
{
int n;
long long a;
scanf("%d",&n);
set<long long> s;
for(int i=0;i<n;i++)
{
scanf("%lld",&a);
s.insert(a);//set自动去重
}
//printf("%d\n",s.size());
if(s.size()<3)//只有1种或两种数字,必然可以
{
printf("YES\n");
}
else if(s.size()>3)//若其中有两种数字可以通过一加一减达成第三种数字,那第四种必定不可以
{
printf("NO\n");
}
else//三种呈等差数列
{
set<long long>::iterator it;
long long ans[3];
int index=0;
for(it=s.begin();it!=s.end();it++)
{
//printf("%lld\n",*it);
ans[index]=*it;
index++;
}
/*for(int i=0;i<3;i++)
{
printf("%lld\n",ans[i]);
}*/
if((ans[1]-ans[0])==(ans[2]-ans[1]))
{
printf("YES\n");
}
else
{
printf("NO\n");
}
}
}
return 0;
} HRZ学英语

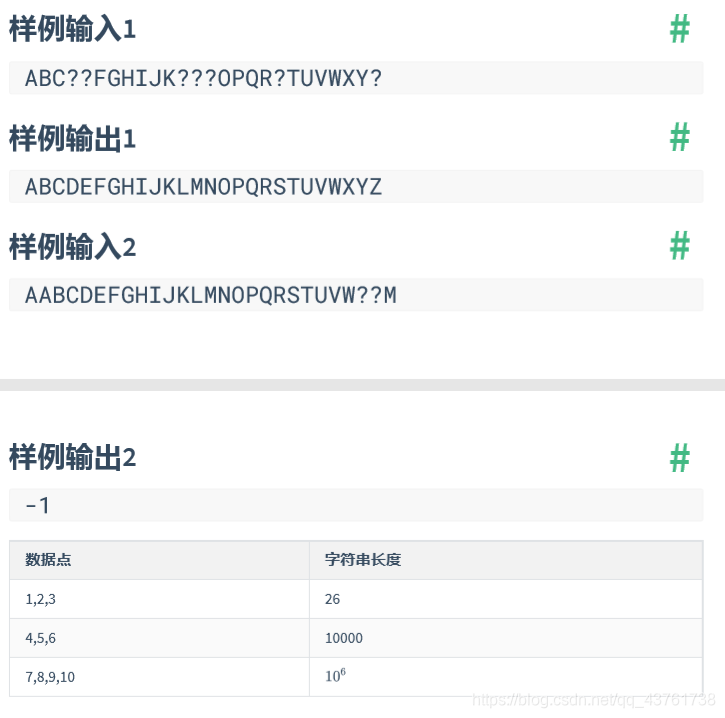
思路分析
看到这题我就想起了尺取法。(不是,但类似)
先使l=0,r=25取字符串中前26个字母进行判断,数组count存放当前[l,r]中26字母和‘?’的个数。若26个字母中有个数大于1的,则肯定不满足,str[l]对应count元素–,str[r+1]对应count元素++,l++,r++。若26个字母中没有大于1的,则满足,因为要输出字典序最小的,所以这里我们借助队列,从A开始,将所有count[i]==0的字母插入队列中,输出时,每当遇到‘?’就取出队首元素输出。
AC代码
#include<iostream>
#include<cstdio>
#include<string>
#include<queue>
using namespace std;
int tag[26];
int count[27]={0};
void add(char x)
{
if(x!='?')
{
count[x-'A']++;
}
else
{
count[26]++;
}
}
void sub(char x)
{
if(x!='?')
{
count[x-'A']--;
}
else
{
count[26]--;
}
}
bool judge()
{
for(int i=0;i<26;i++)
{
if(count[i]>1) return false;
}
return true;
}
int main()
{
string str;
cin>>str;
int l=0,r=25;
if(str.size()<26)
{
cout<<"-1"<<endl;
return 0;
}
for(int i=l;i<=r;i++)
{
add(str[i]);
}
while(r<str.size())
{
if(!judge())//不满足条件,l++,r++
{
if(r+1==str.size())
{
break;
}
sub(str[l]);
add(str[r+1]);
l++;r++;
}
else
{
queue<char> v;
for(int i=0;i<26;i++)//得到没有出现的字母字典序最小的顺序
{
if(count[i]==0)
{
char a='A'+i;
v.push(a);
}
}
for(int i=l;i<=r;i++)
{
if(str[i]!='?')
{
cout<<str[i];
}
else
{
cout<<v.front();
v.pop();
}
}
return 0;
}
}
cout<<"-1";
return 0;
}咕咕东的奇妙序列

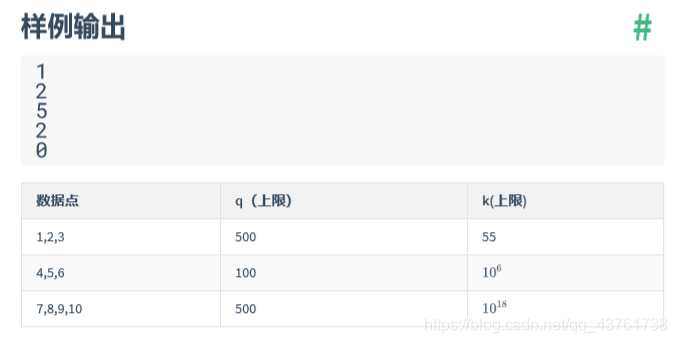
思路分析
首先我们知道k最大可达到10^18,所以暴力列举是不可能的,必然要对序列进行一些划分,以此降低复杂度。

观察上图序列可以发现,第1-9部分每个数字最多占1位,第10-99最多占2位,第100~999最多占3位,所以我们可以根据数字位数的不同将序列划分为不同区域,每个区域都满足等差数列,即在第i个区域中,后一个部分总比前一个部分多i项。数组count存放前i个区域共有多少项,数组a1为第i个区域的首项序号(这个区域第一部分的项数),数组an为第i个区域的尾项序号(这个区域最后一部分的项数)。
//初始化
void init()//初始化,等差数列前n项和公式 na1+n(n-1)d/2
{
count[0]=0;
a1[0]=0;
an[0]=0;
num[0]=0;
long long n;
for(int i=1;i<20;i++)
{
n=pow(10,i)-pow(10,i-1);//项数
d=i;//公差
a1[i]=an[i-1]+d;//首项
an[i]=a1[i]+(n-1)*d;//项数
count[i]=count[i-1]+(n*(a1[i]+an[i]))/2;//当前区域的等差数列和 +前一个
num[i]=n*d+num[i-1];
if(count[i]>=inf) break;
}
}先判断k在哪个区域cur,再判断k-count[cur-1]属于这个区域的第几部分。因为部分序号是单调的,所以就可以使用二分查找。
//二分
k=k-count[cur-1];
long long l=1,r=pow(10,cur)-pow(10,cur-1),index=0;//找到k具体属于哪一部分
while(l<=r)
{
long long mid=(l+r)/2;//在这一区域中是第几部分,从1开始
if(k<=mid*a1[cur]+((mid*(mid-1))/2)*cur)//前mid项和
{
index=mid;
r=mid-1;
}
else
{
l=mid+1;
}
}
//cout<<"index "<<index<<endl;
k-=(index-1)*a1[cur]+(((index-1)*(index-2))/2)*cur;//第index部分中的第k项 找到k在第几部分后又面临一个问题,因为含1至i之间的数字每个数字所占的项数也不一样,所以我们还要进行分区,数组num表示前前i个区域共有多少项,找到k属于哪个区域。

找到后还要找k为这个区域(now)中的哪个数字ans,于是继续二分。最后确定k为这个数字的第几项,输出答案。
综上,用了两次分区–二分的操作,降低了复杂度。
考虑到本题的数据要求,方便起见除了存放询问次数的变量q外,都定义为long long型,否则就一直WA!
AC代码
#include<iostream>
#include<cstdio>
#include<cmath>
using namespace std;
long long inf=1e18;
long long count[20],a1[20],an[20],num[20];
long long d=0;//公差,同时也是区域数
void init()//初始化,等差数列前n项和公式 na1+n(n-1)d/2
{
count[0]=0;
a1[0]=0;
an[0]=0;
num[0]=0;
long long n;
for(int i=1;i<20;i++)
{
n=pow(10,i)-pow(10,i-1);//项数
d=i;//公差
a1[i]=an[i-1]+d;//首项
an[i]=a1[i]+(n-1)*d;//项数
count[i]=count[i-1]+(n*(a1[i]+an[i]))/2;//当前区域的等差数列和 +前一个
num[i]=n*d+num[i-1];
if(count[i]>=inf) break;
}
}
int main()
{
int q;
long long k;
scanf("%lld",&q);
init();
while(q--)
{
scanf("%lld",&k);
long long cur=1;//所在区域编号
for(;cur<=d;cur++)
{
//cout<<"count "<<cur<<" ="<<count[cur]<<endl;
if(k<=count[cur])
{
break;
}
}
//cout<<"cur "<<cur<<endl;
k=k-count[cur-1];
long long l=1,r=pow(10,cur)-pow(10,cur-1),index=0;//找到k具体属于哪一部分
while(l<=r)
{
long long mid=(l+r)/2;//在这一区域中是第几部分,从1开始
if(k<=mid*a1[cur]+((mid*(mid-1))/2)*cur)//前mid项和
{
index=mid;
r=mid-1;
}
else
{
l=mid+1;
}
}
//cout<<"index "<<index<<endl;
k-=(index-1)*a1[cur]+(((index-1)*(index-2))/2)*cur;//第index部分中的第k项
//cout<<"现在K "<<k<<endl;
long long now=1;//当前第index部分的哪个位置
for(;now<=d;now++)
{
if(k<=num[now])
{
break;
}
}
//cout<<"now "<<now<<endl;
k=k-num[now-1];
//cout<<"现在K "<<k<<endl;
l=1;r=pow(10,now)-pow(10,now-1);index=0;//找到k具体属于now中的第几个数
while(l<=r)
{
long long mid=(l+r)/2;
if(k<=mid*now)//前now项和
{
index=mid;
r=mid-1;
}
else
{
l=mid+1;
}
}
/*if(k%now==0) index=k/now;
else
{
index=k/now+1;
}*/
k-=(index-1)*now;
//cout<<"index "<<index<<endl;
//cout<<"现在K "<<k<<endl;
long long ans=pow(10,now-1)+index-1;//这个数是ans
//cout<<"ans "<<ans<<endl;
//找ans中第k项
while(now>=k)
{
if(now==k)
{
ans=ans%10;
printf("%lld\n",ans);
break;
}
ans=ans/10;
now--;
}
}
return 0;
}

















 231
231

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











