







原文链接:阿里高德地图后端日常实习_牛客网 (nowcoder.com)
本文仅作为个人学习使用。
设计数据表主键用自增ID还是UUID
-
自增ID (Auto-Increment)
- 适用场景:
- 当数据表中记录数量较小,且没有跨库或跨系统需求时,自增ID是一个简单有效的选择。
- 自增ID查询性能比UUID更好,因为数据存储时是有序的。
- 优点:
- 实现简单,无需生成UUID字符串。
- 查询性能好,因为数据存储是有序的。
- 缺点:
- 不适合跨库或跨系统的数据共享,因为自增ID只在单个数据库中唯一。
- 如果数据表记录量巨大,可能会耗尽ID空间。
- 适用场景:
-
UUID (Universally Unique Identifier)
- 适用场景:
- 当您的应用需要跨库或跨系统共享数据时,UUID是一个更好的选择。
- 当您的数据表记录量非常庞大时,自增ID可能会耗尽ID空间,此时使用UUID是更好的选择。
- 优点:
- 可以跨库、跨系统共享数据,因为UUID是全局唯一的。
- 无需担心ID空间耗尽的问题。
- 缺点:
- UUID字符串较长,存储空间占用较大。
- 查询性能略低于自增ID,因为UUID是无序的。
- 适用场景:
自增ID可能会耗尽ID空间的原因如下:
ID空间有限:
- 自增ID通常采用整型数据类型,比如 int 或 bigint。这些数据类型的取值范围是有限的。
- 以 int 类型为例,其取值范围为 -2,147,483,648 到 2,147,483,647,也就是约 21 亿个 ID。
数据量不断增加:
- 随着业务的发展和数据量的不断增加,可能会很快耗尽 21 亿个 ID 的空间。
- 特别是对于一些海量数据的应用,如电商、社交网络等,ID 耗尽的风险会更高。
不能跨库共用:
- 自增ID只能在单个数据库中保证唯一性,不适合跨库或跨系统的数据共享。
- 如果需要在多个数据库或系统之间共用主键,自增ID就不太合适了。
当自增ID的ID空间耗尽时,就需要考虑更合适的主键方案,比如使用UUID。
UUID (Universally Unique Identifier) 的优势如下:
ID 空间巨大:
- UUID 由 128 位的数字组成,理论上可生成 2^128 个唯一标识,约等于 340 万亿个。
- 这个空间对于绝大多数应用来说是足够的,不太可能会耗尽。
跨库跨系统共享:
- UUID 是全局唯一的,可以跨数据库、跨系统进行数据共享。
- 这对于分布式系统或需要数据互通的应用来说非常有用。
因此,当自增ID可能耗尽ID空间时,使用UUID会是一个更好的选择。UUID能提供足够大的ID空间,同时也支持跨库跨系统的数据共享需求。
为什么自增ID更快一些
即使使用 B+树有序存储,UUID 查询通常也比自增 ID 更慢一些,主要有以下几个原因,最主要的就是,UUID 的随机生成特性导致它的数据分布也是随机的
-
数据页利用率
- 自增 ID 插入时,记录是连续增长的,可以很好地利用数据页的空间。
- 而 UUID 是随机分布的,很难命中同一个数据页,导致页内空间利用率较低,需要更频繁的页分裂操作。
-
索引维护开销
- 自增 ID 插入时,只需在索引末尾追加新记录,维护成本较低。
- UUID 插入时,需要在合适的位置插入新记录,索引维护开销较大。
-
缓存命中率
- 自增 ID 的连续性可以更好地利用数据库缓存,提高命中率。
- UUID 的随机分布使缓存命中率相对较低。
-
范围查询性能
- 自增 ID 作为主键时,可以很好地利用 B+树的有序性进行范围查询。
- UUID 作为主键时,由于数据分布随机,范围查询性能会较差。
尽管 UUID 也可以使用 B+树有序存储,但由于其本身的随机特性,在数据页利用率、索引维护开销和缓存命中率等方面,都无法完全发挥 B+树的优势。
因此,对于大多数场景,自增 ID 作为主键通常能提供更好的查询性能。但在某些特殊需求下,如数据分区和隐私保护,UUID 也可能是更合适的选择。
查询数据时,到了B+树的叶子节点,之后的查找数据是如何做
感觉问的是聚簇索引与非聚簇索引查找数据。参考MySQL索引之 B+树详解(看完你就明白了)_b+树的数据结构 mysql 详细解读-优快云博客
B+ 树索引可以分为两种类型:聚簇索引和非聚簇索引。
聚簇索引
- 定义: 聚簇索引是数据本身的物理存储顺序,也就是说,数据行按照索引键的顺序存储在磁盘上。
- 查找数据: 由于数据本身按照索引键排序,因此查找数据时可以直接通过索引键定位到数据行,效率很高。
- 特点:
- 每个表只能有一个聚簇索引。
- 聚簇索引的索引键通常是主键。
- 更新数据时,如果主键发生变化,则需要移动数据行,效率较低。
非聚簇索引
- 定义: 非聚簇索引存储的是索引键和数据行的逻辑地址(指针)。
- 查找数据: 查找数据时,需要先通过非聚簇索引找到数据行的逻辑地址,然后根据逻辑地址找到数据行。
- 特点:
- 一个表可以创建多个非聚簇索引。
- 非聚簇索引的索引键可以是任何列。
- 更新数据时,如果索引键发生变化,只需要更新索引条目,效率较高。
查找数据效率对比
- 聚簇索引: 查找速度快,因为直接定位到数据行。
- 非聚簇索引: 查找速度相对较慢,需要先找到数据行的逻辑地址,再找到数据行。
总结
- 如果需要频繁查询数据,并且查询条件是主键,则使用聚簇索引效率更高。
- 如果需要查询非主键列,或者需要创建多个索引,则使用非聚簇索引。
示例
假设有一个学生表,包含学号、姓名、年龄等信息。
- 聚簇索引: 如果以学号作为主键,并创建聚簇索引,则数据行按照学号排序存储。查找某个学生的详细信息时,可以直接通过学号定位到数据行。
- 非聚簇索引: 如果以姓名创建非聚簇索引,则索引条目存储的是姓名和对应数据行的逻辑地址。查找所有姓王的同学时,需要先通过姓名索引找到所有姓王的同学的逻辑地址,然后根据逻辑地址找到对应数据行。
需要注意的是,索引的创建和使用需要根据实际情况进行选择,才能达到最佳的查询效率。
B+树索引
结构:
- 节点: B+ 树由节点组成,每个节点包含多个数据项和指针。
- 数据项: 每个数据项包含一个键值和指向数据记录的指针。
- 指针: 指针指向其他节点,包括子节点和兄弟节点。
- 叶子节点: 所有数据记录都存储在叶子节点中,并且叶子节点按顺序链接在一起。
- 非叶子节点: 非叶子节点存储键值,用于快速定位数据记录。
特点:
- 平衡树: B+ 树始终保持平衡,确保所有叶子节点都在同一层级,提高了搜索效率。
- 顺序访问: 叶子节点按顺序链接,可以有效地进行范围查询。
- 磁盘效率: B+ 树的结构使得它能够有效地利用磁盘空间,减少磁盘访问次数。
MySQL有哪些存储引擎
InnoDB
特点: 支持事务、行级锁、外键约束、MVCC (多版本并发控制),并提供高性能和数据完整性。
适用场景: 要求高数据完整性和并发性能的应用,例如电商网站、金融系统等。
MyISAM
特点: 支持全文索引,速度快,但缺乏事务支持和外键约束。
适用场景: 适用于读操作频繁,对数据完整性要求不高的应用,例如日志记录、数据仓库等。
InnoDB的四种隔离级别
- READ UNCOMMITTED (读未提交):最低隔离级别,允许读取未提交的数据,可能出现脏读、不可重复读和幻读。
- READ COMMITTED (读已提交):允许读取已提交的数据,可以避免脏读,但可能出现不可重复读和幻读。
- REPEATABLE READ (可重复读,默认):保证同一事务内多次读取相同数据的结果一致,可以避免脏读和不可重复读,但可能出现幻读。
- SERIALIZABLE (串行化):最高隔离级别,所有事务都按顺序执行,可以避免脏读、不可重复读和幻读,但性能最低。
- 脏读: 一个事务读取了另一个事务未提交的数据。
- 不可重复读: 一个事务多次读取同一数据,得到的结果不一致,因为另一个事务在该事务读取数据期间提交了修改。
- 幻读: 一个事务读取数据后,另一个事务插入了新的数据,导致该事务再次读取数据时,发现出现了新的数据。
举例:
假设有两个事务 T1 和 T2:
- T1 读取一个账户的余额为 100 元。
- T2 将该账户的余额修改为 200 元,但尚未提交。
- T1 再次读取该账户的余额,可能读到 200 元(脏读)。
- T2 提交了修改。
- T1 再次读取该账户的余额,可能读到 100 元,也可能读到 200 元(不可重复读)。
- T2 插入了一条新的记录,该记录与 T1 查询条件匹配。
- T1 再次读取数据,发现多了一条记录(幻读)。
可重复读有没有幻读的问题
可重复读使用的是快照读 (Snapshot Read),它在事务开始时创建了一个数据快照,并在事务期间读取该快照。因此,T1 在第一次读取数据时,只看到了快照中的数据,而 T2 插入的新数据不在快照中,所以 T1 无法看到新数据。
解决方法:
- 使用间隙锁 (Gap Lock): 可重复读隔离级别下,InnoDB 会使用间隙锁来防止幻读。间隙锁会锁定数据行之间的间隙,防止其他事务在该间隙插入新的数据。
- 使用 Next-Key Lock: Next-Key Lock 是间隙锁和记录锁的组合,可以锁定数据行和数据行之间的间隙,更有效地防止幻读。
InnoDB 就引入了间隙锁 (Gap Lock) 和 Next-Key Lock。
MySQL的锁
参考MySQL数据库的锁 --- 六种分类 - 14种锁详细介绍_mysql的锁-优快云博客
设计一个行级锁的死锁
首先参考:Mysql死锁问题如何排查和解决 - hanease - 博客园 (cnblogs.com)
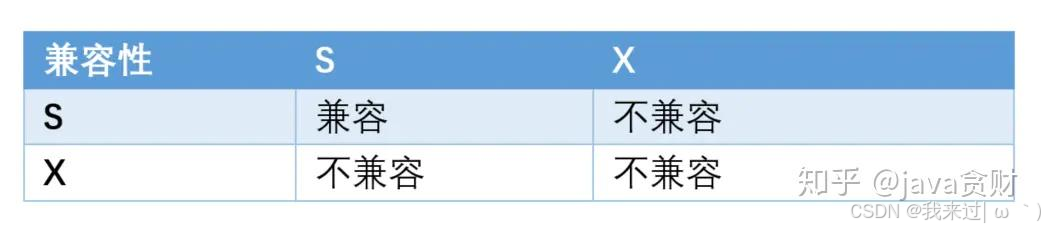
如果事务 T1 持有行 r 的 s 锁,那么另一个事务 T2 请求 r 的锁时,会做如下处理:
- T2 请求 s 锁立即被允许,结果 T1 T2 都持有 r 行的 s 锁
- T2 请求 x 锁不能被立即允许,需要等待T1 s锁释放
如果 T1 持有 r 的 x 锁,那么 T2 请求 r 的 x、s 锁都不能被立即允许,T2 必须等待T1释放 x 锁才可以,因为X锁与任何的锁都不兼容。
那么,当T1 T2同时持有s锁时,都希望进行更新操作就会互相等待对方释放s锁,这时没有合适的处理机制就会陷入死等。
MyBatis中的#和$有什么区别
# 符号
- 预处理占位符:
#符号用于预处理语句中的占位符,它会将参数值替换到 SQL 语句中,并进行类型转换和安全处理。 - 防止 SQL 注入: 使用
#符号可以有效地防止 SQL 注入攻击,因为 MyBatis 会将参数值进行转义,避免恶意代码的执行。 - 提高性能: 使用
#符号可以提高 SQL 语句的执行效率,因为 MyBatis 会将预处理语句缓存起来,减少数据库解析 SQL 语句的时间。
$ 符号
- 直接拼接字符串:
$符号会直接将参数值拼接进 SQL 语句中,不会进行类型转换和安全处理。 - 容易造成 SQL 注入: 使用
$符号容易造成 SQL 注入攻击,因为参数值不会被转义,恶意代码可能会被执行。 - 性能较低: 使用
$符号会导致 SQL 语句的执行效率降低,因为 MyBatis 需要每次都解析 SQL 语句。
// 使用 # 符号
String sql = "SELECT * FROM users WHERE username = #{username}";
// 使用 $ 符号
String sql = "SELECT * FROM " + ${tableName} + " WHERE username = '" + ${username} + "'";SQL 注入攻击
SQL 注入攻击是一种常见的网络安全攻击,攻击者通过将恶意 SQL 代码注入到应用程序的输入数据中,从而绕过应用程序的安全机制,获取敏感数据、修改数据库内容甚至控制整个数据库服务器。
攻击原理:
- 应用程序接收用户输入: 应用程序通常会接收用户输入,例如用户名、密码、搜索关键词等。
- 用户输入包含恶意代码: 攻击者会将恶意 SQL 代码插入到用户输入中,例如:
' or '1'='1'--- 应用程序将用户输入拼接进 SQL 语句: 应用程序将用户输入拼接进 SQL 语句,例如:
SELECT * FROM users WHERE username = 'admin' or '1'='1'--- 数据库执行恶意代码: 数据库执行拼接后的 SQL 语句,由于恶意代码的存在,数据库会执行攻击者预期的操作,例如获取所有用户数据。
本地缓存和Redis缓存的区别
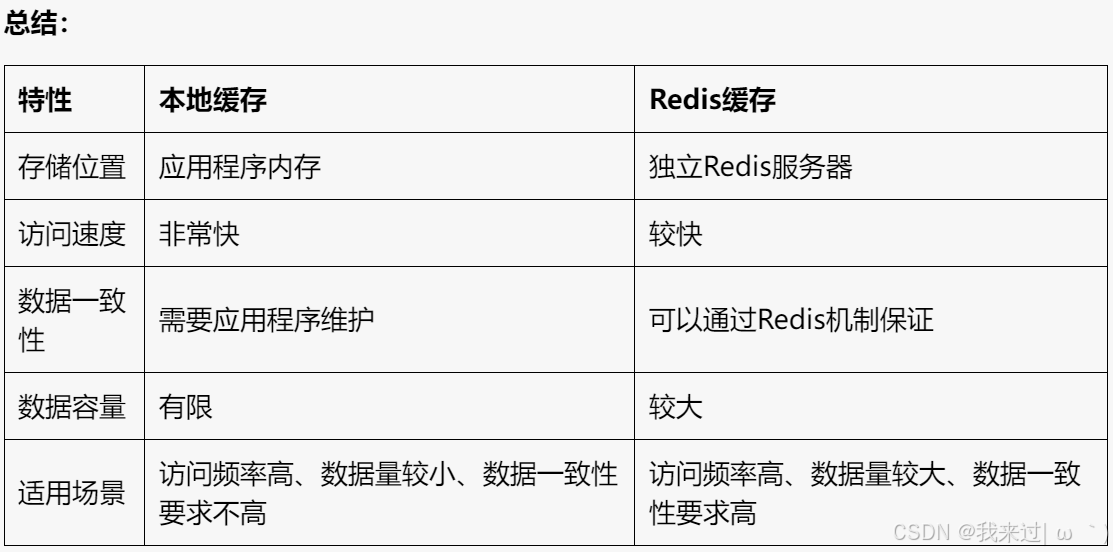
本地缓存
- 存储位置: 存储在应用程序的内存中,通常使用 HashMap 或其他数据结构来实现。
- 访问速度: 速度非常快,因为数据直接存储在内存中,无需进行网络通信。
- 数据一致性: 数据一致性需要应用程序自己维护,如果数据更新了,需要手动更新缓存。
- 数据容量: 受到应用程序内存限制,容量有限。
- 适用场景: 适用于访问频率高、数据量较小、数据一致性要求不高的场景,例如用户登录信息、热门商品信息等。
Redis缓存
- 存储位置: 存储在独立的Redis服务器中,是一个高性能的键值存储数据库。
- 访问速度: 速度也很快,但比本地缓存略慢,因为需要进行网络通信。
- 数据一致性: 可以通过Redis提供的各种机制来保证数据一致性,例如缓存穿透、缓存雪崩、缓存击穿等。
- 数据容量: 容量较大,可以根据需求进行扩展。
- 适用场景: 适用于访问频率高、数据量较大、数据一致性要求高的场景,例如商品信息、用户行为数据等。
Redis的Key过期了是立马删除吗
Redis 的 Key 过期机制并不是实时删除的,而是通过惰性删除和定期删除的组合来实现。这种机制可以最大程度地减少删除操作的开销,同时也能保证过期 Key 不会长时间占用内存。
惰性删除 (Lazy Deletion)
- 当你尝试访问一个已过期的 Key 时,Redis 才会发现该 Key 已经过期,并将其删除。
- 这种方式的好处是,如果一个 Key 很少被访问,那么它可能永远不会被删除,从而节省了删除操作的开销。
定期删除 (Expire Eviction)
- Redis 会定期检查数据库中的 Key,并删除那些已经过期的 Key。
- 定期删除的频率可以通过
hz参数进行配置,默认值为 10 秒,表示每 10 秒检查一次。 - 定期删除可以防止大量过期 Key 积压,但也会增加 CPU 负载。
需要注意的是:
- 惰性删除和定期删除的机制并不保证过期 Key 一定会被删除。如果一个 Key 非常活跃,即使它已经过期,也可能在被删除之前被多次访问。
- 如果你需要确保过期 Key 一定会被删除,可以使用
EXPIRE命令设置 Key 的过期时间,然后使用DEL命令手动删除。
惰性删除的内存问题主要体现在以下几个方面:
- 内存占用: 过期的 Key 仍然占用内存,直到被访问或被定期删除。如果有很多 Key 过期,但很少被访问,那么这些 Key 就会一直占用内存,导致内存泄漏。
- 内存碎片: 过期的 Key 占据的内存空间可能无法被其他 Key 使用,导致内存碎片化,降低内存利用率。
- 性能下降: 当内存占用过高时,Redis 的性能会下降,因为需要更多的时间来查找和访问数据。
如何缓解惰性删除的内存问题:
- 合理设置过期时间: 尽量设置合理的 Key 过期时间,避免 Key 过期后长时间占用内存。
- 定期清理: 定期执行
EXPIRE命令,将 Key 的过期时间设置为一个较短的值,以便尽快清理过期 Key。- 使用
DEL命令: 当你不再需要某个 Key 时,可以使用DEL命令手动删除它,而不是等待它自动过期。- 调整定期删除频率: 适当提高定期删除的频率,可以更及时地清理过期 Key,但也会增加 CPU 负载。
- 使用其他数据结构: 如果你的数据不需要持久化,可以考虑使用其他数据结构,例如
List或Set,它们没有过期时间,可以避免内存问题。
Redis的大Key问题
Redis中什么是Big Key(大key)问题?如何解决Big Key问题?_redis bigkey-优快云博客
Redis 的大 Key 问题是指 Key 对应的 Value 占用内存过大,会导致以下问题:
影响性能
- 内存占用高: 大 Key 占用大量内存,导致 Redis 内存使用率高,甚至可能导致内存不足,影响其他操作的执行。
- 慢查询: Redis 在处理大 Key 时,需要读取和写入大量数据,导致查询速度变慢。
- 内存碎片: 大 Key 可能会导致内存碎片化,降低内存利用率,进一步影响性能。
影响其他操作
- 阻塞其他操作: 大 Key 的操作会占用大量 CPU 和内存资源,可能阻塞其他操作的执行,导致 Redis 响应延迟。
- 影响持久化: Redis 的持久化操作需要将所有数据写入磁盘,大 Key 会导致持久化时间过长,影响数据恢复速度。
影响稳定性
- 内存溢出: 大 Key 可能会导致 Redis 内存溢出,导致服务崩溃。
- 数据丢失: 如果 Redis 因为内存溢出而崩溃,可能会导致数据丢失。
如何解决大 Key 问题
- 拆分 Key: 将一个大 Key 拆分成多个小 Key,例如将一个包含用户信息的 Key 拆分成多个 Key,分别存储用户的不同信息。
- 使用 Hash 结构: 使用 Hash 结构存储多个字段,可以有效减少 Key 的数量,避免大 Key 问题。
- 使用压缩: 对 Value 进行压缩,可以减少内存占用,但会增加 CPU 负载。
- 设置过期时间: 为 Key 设置合理的过期时间,避免 Key 长时间占用内存。
- 使用其他数据结构: 如果数据不需要持久化,可以考虑使用其他数据结构,例如
List或Set,它们通常比String更节省内存。 - 使用 Redis Cluster: 将数据分散到多个 Redis 节点,可以降低单个节点的内存压力。
如果有一个接口存的是大Key QPS比较低,另外有10个接口QPS非常高那有什么影响
QPS (Queries Per Second) 指的是每秒查询次数,是衡量服务器处理能力的一个重要指标。
简单来说,QPS 就是指服务器每秒能够处理的请求数量。
例如:
- 如果一个网站的 QPS 是 100,就意味着该网站每秒能够处理 100 个用户请求。
- 如果一个 API 接口的 QPS 是 1000,就意味着该接口每秒能够处理 1000 个 API 请求。
对大 Key 接口的影响
- 性能影响较小: 由于大 Key 接口的 QPS 比较低,即使它占用较多内存,对 Redis 的整体性能影响也不会太大。
- 内存占用: 大 Key 仍然会占用大量内存,但由于 QPS 低,影响相对较小。
- 持久化影响: 大 Key 可能会影响 Redis 的持久化速度,但由于 QPS 低,影响相对较小。
对高 QPS 接口的影响
- 竞争资源: 高 QPS 接口可能会与大 Key 接口竞争 Redis 的资源,例如 CPU、内存、网络带宽等,导致高 QPS 接口的性能下降。
- 阻塞问题: 如果大 Key 接口的执行时间较长,可能会阻塞高 QPS 接口的执行,导致高 QPS 接口的响应延迟。
- 缓存命中率: 高 QPS 接口的缓存命中率可能会降低,因为 Redis 的内存被大 Key 占用,导致高 QPS 接口的数据无法被缓存。
对 Redis 整体的影响
- 内存压力: 大 Key 会占用大量内存,导致 Redis 的内存压力增加,可能会影响其他操作的执行。
- 性能下降: Redis 的整体性能可能会下降,因为大 Key 会占用 CPU 资源,影响其他操作的执行速度。
- 稳定性风险: 如果 Redis 的内存被大 Key 占用过多,可能会导致 Redis 崩溃,影响系统稳定性。
为什么key不是大key但QPS非常高的接口,对性能影响没那么大
-
内存占用: 非大 Key 的接口,即使 QPS 非常高,单个 Key 占用的内存也相对较小,不会对 Redis 的整体内存占用造成太大压力。
-
数据处理量: 即使 QPS 非常高,但由于单个 Key 占用的内存小,每次请求处理的数据量也相对较小,因此对 CPU 和网络带宽的压力也相对较小。
-
缓存命中率: 高 QPS 接口通常会使用缓存机制,缓存命中率高,意味着大部分请求可以直接从缓存中获取数据,减少对 Redis 的访问压力。
-
Redis 的设计: Redis 本身的设计就非常适合处理高 QPS 的请求,它使用单线程模型,避免了多线程带来的上下文切换开销,并且使用了高效的数据结构和算法,可以快速处理数据。
-
其他因素:
- 数据结构的选择: 如果使用
Set或List等数据结构,即使 QPS 非常高,对性能的影响也相对较小。 - 请求类型: 如果请求只是简单的读操作,对性能的影响也相对较小。
需要注意的是:
- 即使是小的 Key,如果 QPS 非常高,也可能会对 Redis 的性能造成一定的影响。
- 如果 QPS 持续很高,建议对 Redis 进行性能调优,例如增加内存、使用 Redis Cluster 等。
ZSet的底层数据结构,查询的时间复杂度是多少
Redis 的 ZSet 底层使用的是 跳跃表(Skip List) 数据结构。
跳跃表是一种概率数据结构,它结合了链表和多级索引的优点,可以实现高效的插入、删除和查找操作。
跳跃表的主要特点:
- 多级索引: 跳跃表有多个层级,每个层级都是一个有序链表,层级之间通过随机指针连接。
- 概率性: 每个节点加入下一层级的概率是固定的,通常为 1/2。
- 平衡性: 由于概率性,跳跃表可以保持一定程度的平衡性,避免了单链表的查找效率低的问题。
ZSet 的查询时间复杂度:
- 范围查询: 由于跳跃表的多级索引,ZSet 的范围查询时间复杂度为 O(log N),其中 N 是 ZSet 中元素的数量。
- 单个元素查询: ZSet 的单个元素查询时间复杂度也为 O(log N)。
Redis的持久化
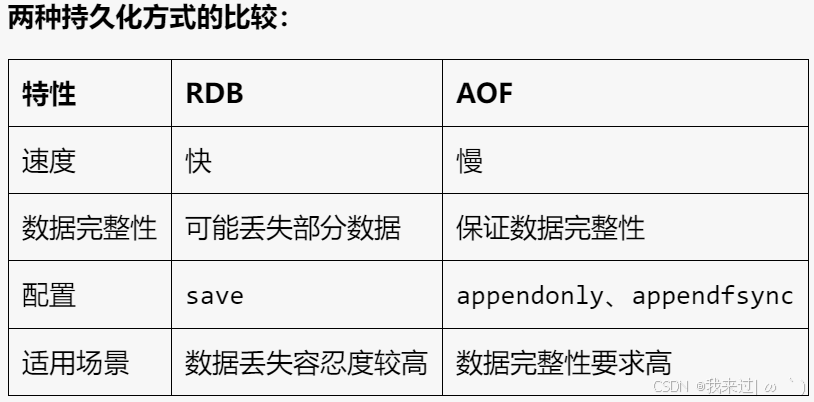
Redis 的持久化是指将内存中的数据保存到磁盘,以便在服务器重启后能够恢复数据。Redis 提供了两种持久化方式:
RDB(Redis Database Backup,快照持久化)
- 原理: RDB 持久化会定期将内存中的数据快照保存到磁盘上的一个或多个 RDB 文件中。
- 优点: RDB 持久化速度快,恢复数据也很快,适合数据丢失容忍度较高的场景。
- 缺点: 如果 Redis 进程意外退出,而上次保存快照的时间较长,则会丢失部分数据。
- 配置: 通过
save配置项控制快照保存频率,例如save 900 1表示每 900 秒(15 分钟)如果至少有 1 个键被修改,则保存一次快照。
RDB 持久化过程如下:
- fork 子进程: Redis 主进程会 fork 出一个子进程,子进程会复制当前 Redis 服务器的内存数据。
- 生成 RDB 文件: 子进程会将内存数据序列化成 RDB 文件,并将文件写入磁盘。
- 替换旧 RDB 文件: 子进程完成 RDB 文件的生成后,会将新的 RDB 文件替换旧的 RDB 文件。
- 通知主进程: 子进程完成 RDB 文件的生成后,会通知主进程,主进程会继续处理客户端请求。
RDB 持久化的优点:
- 速度快: RDB 持久化速度快,因为它是将内存数据直接序列化成文件,不需要逐条写入数据。
- 恢复数据快: RDB 持久化恢复数据也很快,只需要将 RDB 文件加载到内存中即可。
- 适合数据丢失容忍度较高的场景: 由于 RDB 持久化是定期保存快照,如果 Redis 进程意外退出,则会丢失上次保存快照之后的数据。
RDB 持久化的缺点:
- 数据丢失: 如果 Redis 进程意外退出,而上次保存快照的时间较长,则会丢失部分数据。
- 内存占用: fork 子进程会占用额外的内存,如果数据量很大,则会影响 Redis 的性能。
AOF(Append Only File,追加文件持久化)
- 原理: AOF 持久化会将所有写操作命令追加到一个名为 appendonly.aof 的文件中。
- 优点: AOF 持久化能够保证数据的一致性,即使 Redis 进程意外退出,也可以通过重放 AOF 文件恢复数据。
- 缺点: AOF 持久化速度比 RDB 持久化慢,恢复数据也比 RDB 持久化慢。
- 配置: 通过
appendonly配置项开启 AOF 持久化,并通过appendfsync配置项控制 AOF 文件同步频率,例如appendfsync everysec表示每秒同步一次 AOF 文件到磁盘。
AOF 持久化过程如下:
- 写入命令: 当 Redis 服务器接收到一个写操作命令时,会将该命令追加到 AOF 文件的末尾。
- 同步到磁盘: AOF 文件的同步频率可以通过
appendfsync配置项进行控制。
appendfsync always:每次写操作命令都同步到磁盘,数据安全性最高,但性能较低。appendfsync everysec:每秒同步一次 AOF 文件到磁盘,数据安全性较高,性能也较高。appendfsync no:不主动同步 AOF 文件到磁盘,由操作系统决定何时同步,性能最高,但数据安全性最低。- 重写 AOF 文件: 当 AOF 文件过大时,Redis 会启动一个子进程,将 AOF 文件中的命令进行压缩,并生成一个新的 AOF 文件。
- 替换旧 AOF 文件: 子进程完成 AOF 文件的重写后,会将新的 AOF 文件替换旧的 AOF 文件。
AOF 持久化的优点:
- 数据完整性: AOF 持久化能够保证数据的一致性,即使 Redis 进程意外退出,也可以通过重放 AOF 文件恢复数据。
- 数据安全性: AOF 持久化可以通过
appendfsync配置项控制数据同步频率,保证数据安全性。AOF 持久化的缺点:
- 速度慢: AOF 持久化速度比 RDB 持久化慢,因为需要将所有写操作命令追加到 AOF 文件中。
- 文件大小: AOF 文件会随着时间的推移而越来越大,占用磁盘空间。
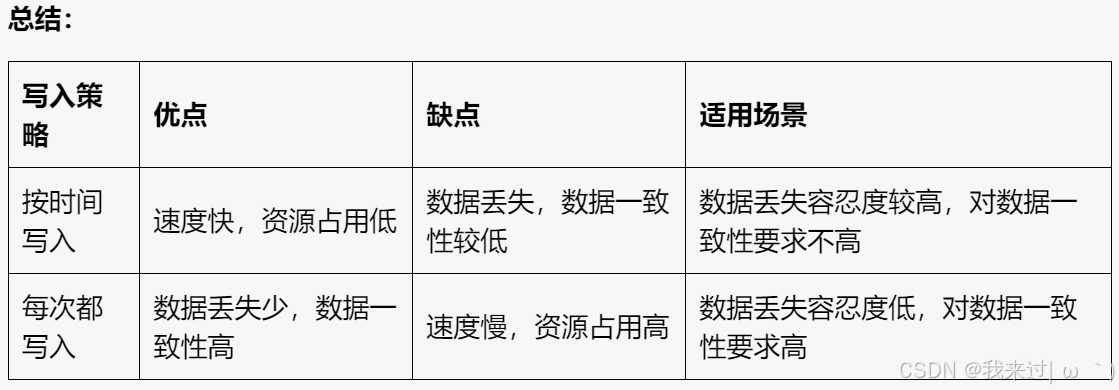
RDB的写入策略,按时间写入和每次都写入的区别,优缺点
按时间写入 (save 900 1)
- 原理: 每隔一段时间(例如 900 秒)检查是否有数据被修改,如果有,则生成一个新的 RDB 文件并替换旧的 RDB 文件。
- 优点:
- 速度快:因为只有在时间间隔达到时才会进行写入操作,所以速度较快。
- 资源占用低:因为只有在时间间隔达到时才会生成新的 RDB 文件,所以资源占用较低。
- 缺点:
- 数据丢失:如果 Redis 进程在两次写入之间意外退出,则会丢失部分数据。
- 数据一致性:数据一致性较低,因为 RDB 文件是定期生成的,所以可能存在数据丢失。
每次都写入 (save 0 1)
- 原理: 每当有数据被修改时,就生成一个新的 RDB 文件并替换旧的 RDB 文件。
- 优点:
- 数据丢失少:因为每次修改数据都会生成新的 RDB 文件,所以数据丢失的可能性较小。
- 数据一致性高:数据一致性较高,因为每次修改数据都会生成新的 RDB 文件,所以数据是一致的。
- 缺点:
- 速度慢:因为每次修改数据都会生成新的 RDB 文件,所以速度较慢。
- 资源占用高:因为每次修改数据都会生成新的 RDB 文件,所以资源占用较高。
Redis 混合持久化
参考Redis 混合持久化 - 朝才 - 博客园 (cnblogs.com)
Redis 的混合持久化(混合持久化)是一种将 RDB 快照和 AOF 日志相结合的持久化策略。它结合了两种方法的优点,提供了一种更灵活和高效的持久化方式。
工作原理
- RDB 快照: Redis 定期将内存中的数据快照保存到磁盘上的 RDB 文件中。这类似于传统的备份方式,可以快速恢复数据。
- AOF 日志: Redis 将所有写入操作都追加到 AOF 文件中。这类似于事务日志,可以确保数据的一致性。
- 混合持久化: 混合持久化策略将 RDB 快照与 AOF 日志结合起来。Redis 会定期创建 RDB 快照,并将所有后续的写入操作追加到 AOF 日志中。
- 恢复数据: 当 Redis 重新启动时,它会首先加载最新的 RDB 快照,然后从 AOF 日志中读取所有后续的写入操作,以恢复到最新的状态。
优点
- 更高的性能: 与 AOF 日志相比,RDB 快照的创建速度更快,因此可以降低 Redis 的性能开销。
- 更快的恢复速度: 与 AOF 日志相比,RDB 快照的恢复速度更快,因为只需要加载一个文件。
- 更高的数据安全性: AOF 日志可以确保数据的一致性,而 RDB 快照可以提供数据恢复的保障。
Bean的生命周期
参考一文读懂 Spring Bean 的生命周期_spring bean的生命周期-优快云博客
Bean 的生命周期指的是 Bean 从创建到销毁的过程,在这个过程中,Bean 会经历一系列的步骤,包括实例化、属性注入、初始化、销毁等。
Bean 生命周期的阶段:
- 实例化: Spring 容器根据 Bean 的定义信息,使用反射机制创建 Bean 的实例。
- 属性注入: Spring 容器将 Bean 定义中的属性值注入到 Bean 实例中,例如使用
@Autowired注解进行依赖注入。 - Aware 接口: 如果 Bean 实现了
Aware接口,例如BeanNameAware、BeanFactoryAware等,Spring 容器会调用相应的回调方法,将相关信息传递给 Bean。 - BeanPostProcessor: Spring 容器会调用
BeanPostProcessor接口的postProcessBeforeInitialization方法,在 Bean 初始化之前进行一些操作,例如 AOP 代理。 - 初始化: Spring 容器会调用 Bean 的
init方法或@PostConstruct注解标记的方法,完成 Bean 的初始化工作。 - 使用: Bean 现在可以被应用程序使用。
- BeanPostProcessor: Spring 容器会调用
BeanPostProcessor接口的postProcessAfterInitialization方法,在 Bean 初始化之后进行一些操作,例如 AOP 代理。 - 销毁: 当 Bean 不再被使用时,Spring 容器会调用 Bean 的
destroy方法或@PreDestroy注解标记的方法,完成 Bean 的销毁工作。
Bean默认单例, 非单例 Bean 的销毁通常在 Bean 实例不再被使用时进行,例如当它被垃圾回收时。
Spring容器里存的是什么
Spring 容器里存放的是 Bean 定义 和 Bean 实例。
Bean 定义
- Bean 定义是关于 Bean 的元数据,包括 Bean 的类名、属性值、依赖关系、作用域、初始化方法、销毁方法等等。
- Spring 容器通过解析配置文件(XML、Java 配置类)或注解来获取 Bean 定义。
- 这些 Bean 定义信息存储在 Spring 容器的内部数据结构中,例如一个 Map 或 Set。
Bean 实例
- 当 Spring 容器启动时,它会根据 Bean 定义信息创建 Bean 实例。
- 这些 Bean 实例也被存储在 Spring 容器中,以便应用程序可以获取和使用它们。
- Spring 容器会管理 Bean 实例的生命周期,包括创建、初始化、销毁等。
总结:
Spring 容器就像一个工厂,它负责创建和管理 Bean。它存储着 Bean 定义和 Bean 实例,并提供各种功能来获取和使用 Bean。
形象比喻:
你可以把 Spring 容器想象成一个大型的仓库,里面存放着各种各样的工具(Bean)。仓库管理员(Spring 容器)知道每个工具的用途、使用方法、存放位置等等(Bean 定义)。当需要使用某个工具时,仓库管理员会找到相应的工具并提供给你(创建 Bean 实例)。
Bean注入和xml注入最终得到了相同的效果,它们在底层是怎样做的
无论是通过注解注入还是 XML 注入,最终都能实现将 Bean 注入到其他 Bean 中,达到相同的效果。它们在底层实现上虽然有所区别,但最终都依赖于 Spring 容器的依赖注入机制。
1. 注解注入:
- 原理: Spring 容器使用 反射机制 来解析注解,例如
@Autowired、@Resource等。 - 流程:
- Spring 容器扫描带有注解的类,并解析注解信息。
- 根据注解信息,找到需要注入的 Bean。
- 使用反射机制,将找到的 Bean 实例注入到目标 Bean 的属性中。
- 优势: 代码简洁、易于维护,更符合面向对象编程的思想。
2. XML 注入:
- 原理: Spring 容器解析 XML 配置文件,并根据配置信息创建 Bean 实例。
- 流程:
- Spring 容器解析 XML 配置文件,读取 Bean 定义信息。
- 根据 Bean 定义信息,创建 Bean 实例。
- 根据 XML 配置文件中定义的依赖关系,将 Bean 实例注入到目标 Bean 的属性中。
- 优势: 配置更加灵活,可以更细粒度地控制 Bean 的创建和注入。
底层实现:
无论是注解注入还是 XML 注入,最终都是通过 Spring 容器的 依赖注入机制 来实现的。
- 依赖注入机制: Spring 容器负责创建和管理 Bean 实例,并根据配置信息将 Bean 实例注入到其他 Bean 的属性中。
- 核心组件: Spring 容器的核心组件包括 BeanFactory 和 ApplicationContext。
- BeanFactory: 负责创建和管理 Bean 实例,并提供 Bean 实例的获取方法。
- ApplicationContext: 基于 BeanFactory,提供更多功能,例如事件发布、国际化支持、资源加载等等。
总结:
无论使用注解注入还是 XML 注入,Spring 容器都会根据配置信息创建 Bean 实例,并通过依赖注入机制将 Bean 实例注入到其他 Bean 的属性中。最终实现的效果是相同的,只是实现方式有所区别。

















 1179
1179

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









