







大数据技术原理与应用学习笔记(十)
本系列历史文章
大数据技术原理与应用学习笔记(一)
大数据技术原理与应用学习笔记(二)
大数据技术原理与应用学习笔记(三)
大数据技术原理与应用学习笔记(四)
大数据技术原理与应用学习笔记(五)
大数据技术原理与应用学习笔记(六)
大数据技术原理与应用学习笔记(七)
大数据技术原理与应用学习笔记(八)
大数据技术原理与应用学习笔记(九)
Spark
Spark简介
Spark的特点:
- 运行速度快
- 容易使用
- 通用性
- 运行模式多样
Spark采用Scala语言1为Spark主要编程语言,同时还支持Java、python、R语言编程。
Spark与Hadoop对比
Spark相对于Hadoop MapReduce的优点:
- 属于但不限于Map和Reduce,编程模型比MapReduce灵活
- Spark提供内存计算,迭代效率更高。
- Spark基于DAG的任务调度执行机制,优于MapReduce迭代机制
Spark生态系统
通常应用中大数据处理包括以下三个类型:
- 复杂的批处理(十分钟 ~ 数小时)例:MapReduce对等于Spark
- 基于历史数据的交互式查询(数十秒 ~ 数分钟)例:Impala对等于Spark SQL
- 基于事实数据流的数据处理(数百毫秒 ~ 数秒)例:Store对应于Spark Streaming
通常存在的问题:
- 不能无缝共享
- 难以维护
- 难以资源分配
而Spark一个软件栈满足不同应用场景。
Spark的组件如下:
- Spark Core 内存计算,主要面向批处理
- Spark SQL基于历史数据的交互式查询
- Spark Streaming 实时流数据处理
- Structed Streaming 流处理
- MLlib 机器学习
- GraphX 图计算
Spark运行架构
基本概念
- RDD(弹性分布式数据集):提供了一种高度受限的共享内存模型。
- DAG(有向无环图):反映了RDD间依赖关系。
- Executor:运行在WorkNode(工作节点)的一个进程,负责运行Task。
- Application:用户编写的Spark应用程序。
- Task:运行在Executor上的工作单元。
- Job:一个Job包含多个RDD及作用于相应RDD上的各种操作。
- Stage(TaskSet):每Job被分为多组Task,每组Task称Stage。
运行架构
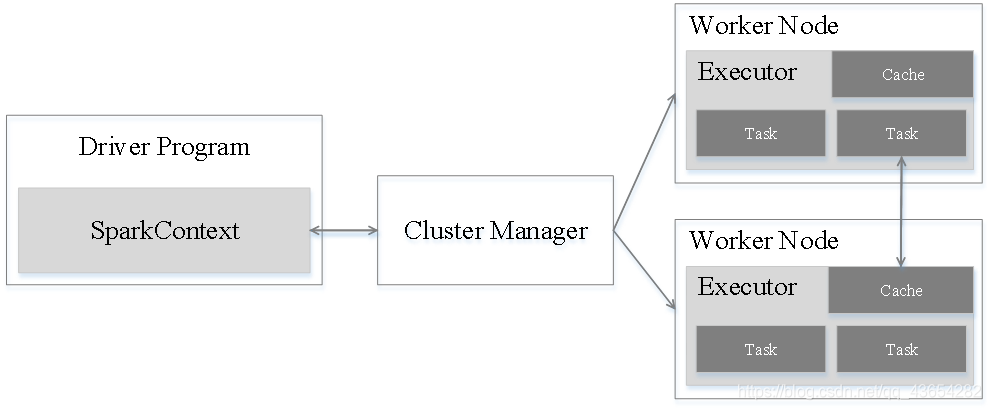
Executor优点:
- 多线程执行,开销小
- Block Manager作为存储,减少I/O开销
基本流程
- 当Spark应用被提交时,首先为其构建运行环境,由Driver创建SparkContext(sc),由其负责和Cluster Manager(资源管理器)的通信并进行资源申请,任务分配及监控等。SparkContext会向Cluster Manager注册并申请运行Executor资源。
- Cluster Manager为Executor分配资源,启动Executor进程,Executor运行情况随“心跳”发送到Cluster Manager。
- SparkContext根据RDD的依赖构建DAG,并将DAG提交至DAG Scheduler,由其解析为Stage,然后把一个个TaskSet提交给底层调度器 Task Scheduler处理。Executor向SparkContext申请Task Scheduler将Task发放给Executor运行,并提供应用程序代码。
- 任务在Executor运行,把执行结果反馈给Cluster Manager,然后反馈给DAG Scheduler运行完毕后写入数据并释放所有资源。
Spark运行架构特点:
- 每个Application均有属于自己的Executor进程且在Application运行期间一直驻留,Executor以多线程方式运行Task。
- Spark运行过程与资源管理器无关,只要获取Executor并保持通信即可。
- Task采用了数据本地性和推测执行等优化机制。
RDD
RDD的设计背景:迭代化算法不同阶段会重用中间结果,不需要中间数据存储。
RDD概念:分布式对象集合。读入内存后分区存储(不可修改,只可转换)。
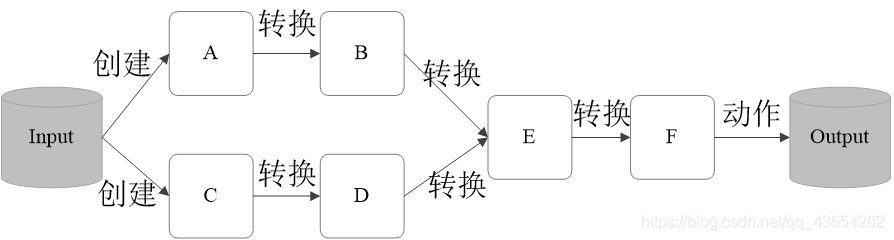
对RDD可执行两大动作:
- Action:由RDD类型→非RDD类型
- Transformation:由RDD→RDD
RDD的执行过程如下图示例:
RDD特性
- 高效的容错性,通过RDD父子依赖
- 中间结果持久化到内存
- 存放的数据可以为Java对象,避免了不必要的读写开销
RDD依赖关系和运行过程
依赖关系分为两种:
- 宽依赖:一个父RDD的一个分区对应一个子RDD的多个分区;
- 窄依赖:一个父RDD的分区对应一个子RDD分区或者多个父RDD分区对应一个子RDD的分区
可以通过宽窄依赖的区分划分Stage,每当遇到宽依赖,则断开;若遇到窄依赖则把当前RDD加入到Stage中。
将窄依赖尽量划分在同一Stage中,可实现流水线计算,从而使数据直接在内存中进行交换,避免磁盘I/O开销。
Spark SQL
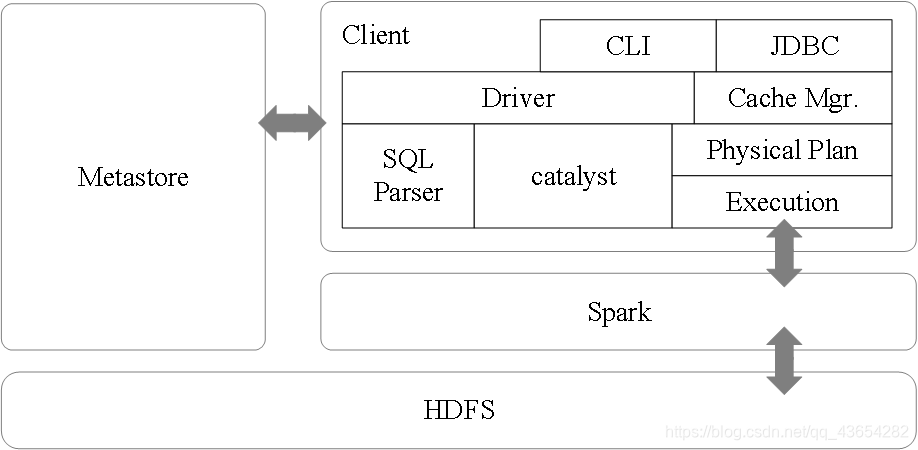
Spark SQL在Hive兼容层面仅依赖HiveQL解析、Hive元数据,也就是说,从HQL被解析成抽象语法树(AST)起,就全部由Spark SQL接管了。Spark SQL执行计划生成和优化都由Catalyst(函数式关系查询优化框架)负责。
Spark SQL架构如下图所示:
Spark部署应用方式
- Standalone:类似于MapReduce1.0,slot为资源分配单位。
- Spark on Mesos
- Spark on YARN
Hadoop、Spark统一部署的原因:
- 部分功能Spark无法替代
- 鲜柚应用多基于Hadoop开发
好处:
- 资源方便按需伸缩
- 不用负载应用混搭
- 共享底层存储,避免数据跨集群迁移
Spark编程实践
关于Spark编程实践部分请参考厦大数据库博客:Spark
Scala是一门多范式的编程语言,一种类似java的编程语言,设计初衷是实现可伸缩的语言 、并集成面向对象编程和函数式编程的各种特性。 ↩︎

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









