







 本文介绍了大数据技术中的Hive和Impala,详细阐述了Hive作为数据仓库工具的工作原理、架构及其与传统数据库的对比。Hive依赖HDFS和MapReduce,适合批处理,而Impala提供低延迟的实时查询,两者在架构和性能上有显著差异。Hive和Impala共享相同的元数据和SQL语法,但在执行引擎和延迟上存在区别,它们在大数据分析场景中各有优势,可以结合使用以满足不同需求。
本文介绍了大数据技术中的Hive和Impala,详细阐述了Hive作为数据仓库工具的工作原理、架构及其与传统数据库的对比。Hive依赖HDFS和MapReduce,适合批处理,而Impala提供低延迟的实时查询,两者在架构和性能上有显著差异。Hive和Impala共享相同的元数据和SQL语法,但在执行引擎和延迟上存在区别,它们在大数据分析场景中各有优势,可以结合使用以满足不同需求。
大数据技术原理与应用学习笔记(九)
本系列历史文章
大数据技术原理与应用学习笔记(一)
大数据技术原理与应用学习笔记(二)
大数据技术原理与应用学习笔记(三)
大数据技术原理与应用学习笔记(四)
大数据技术原理与应用学习笔记(五)
大数据技术原理与应用学习笔记(六)
大数据技术原理与应用学习笔记(七)
大数据技术原理与应用学习笔记(八)
数据仓库Hive
数据仓库概念
数据仓库: 数据仓库是一个面向主题的集成的相对稳定的、反映历史变化的数据集合,用来支撑管理决策。
数据仓库的体系结构包括:数据源、数据存储和管理、分析、挖掘引擎及应用。
传统数据仓库面临的挑战:
- 无法满足快速增长的海量数据存储需求
- 无法有效处理不同类型的数据
- 计算和处理能力不足
Hive简介
Hive——构建在Hadoop之上的数据仓库工具。
Hive本身并不存储处理数据
- 依赖于HDFS存储
- 依赖于MapReduce处理
Hive采用HiveQL语言
Hive两方面特性:
- 采用批处理方式处理海量数据
- Hive提供了一系列对数据进行提取、转换、加载(ETL)的工具
Hive与其他组件的关系:
- Pig可替代Hive用于数据仓库的ETL环节
- Hive主要用于数据仓库海量数据的批处理分析
- HBase支持实时数据访问,与Hive互补
Hive与传统数据库的对比:
如下表:
| 对比项目 | Hive | 传统数据库 |
|---|---|---|
| 数据存储 | HDFS | 本地文件系统 |
| 数据插入 | 支持批量导入 | 支持单条和批量导入 |
| 数据更新 | 不支持 | 支持 |
| 索引 | 支持 | 支持 |
| 分区 | 支持 | 支持 |
| 执行引擎 | MapReduce、Tez、Spark | 使用自身引擎 |
| 执行延迟 | 高 | 低 |
| 扩展性 | 好 | 有限 |
Hive系统架构
用户接口模块
用户接口模块主要包括:
- 用户接口模块
- CLI——命令行
- HWI——Hive的Web接口
- JDBC和ODBC——开放数据库连接接口
- Thrift Server——基于Thrift架构开发的接口
- 驱动模块
包含编译器、优化器、执行器。负责把HiveQL语句转换成MapReduce作业。 - 元数据存储模块
独立的关系型数据库。
Hive HA基本原理——(高可用性)
Hive HA基本原理如图所示:
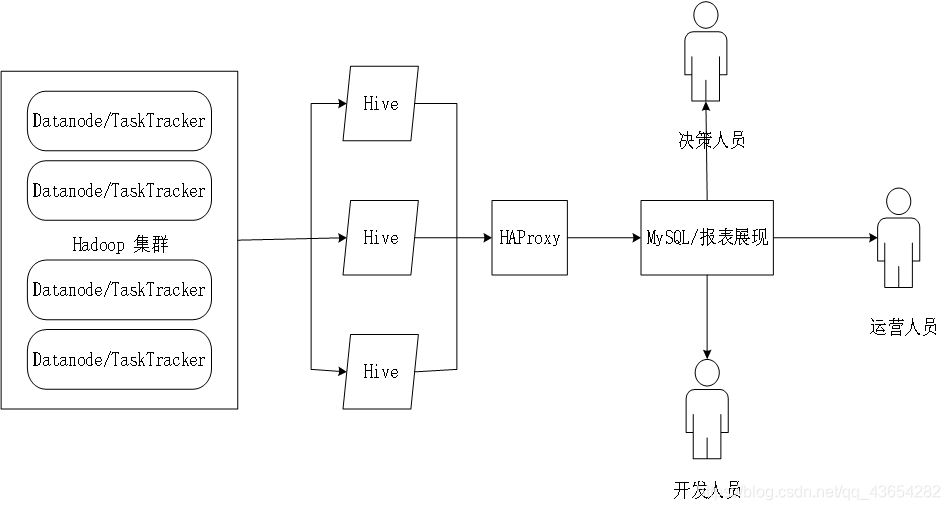
在Hive HA中,在Hadoop集群上构建的数据仓库是由多个Hive实例进行管理的,这些Hive实例被纳入一个资源池中,并由HAProxy提供一个统一的对外接口。客户端的查询请求首先访问HAProxy,由HAProxy对访问请求进行转发。HAProxy收到请求后,会轮询资源池里可用的Hive实例,执行逻辑可用性测试。如果某个Hive实例逻辑可用,就会把客户端的访问请求转发到该Hive实例,如果该Hive实例逻辑不可用,就把它放入黑名单,并继续从资源池取出下一个Hive实例进行逻辑可用性测试,如果重启成功,就再次放入资源池中。
Hive的工作原理
由SQL转换为MapReduce的工作原理
- Input(SQL)转换为抽象语法树(AST)
- AST转换成查询块(Query Block)
- 将Query Block转换成逻辑查询计划
- 重写逻辑查询计划,合并优化等,减少MapReduce的任务数量
- 转换成MapReduce作业
- 优化生成最终版的执行计划。
- 执行并输出
Impala——开源大数据分析引擎
Impala简介
Impala是由Cloudera公司开发的新型查询系统。Impala的目的不在于替换现有的MapReduce工具,而是提供一个统一的平台用于实时查询。
- 与Hive类似,Impala也可以直接与HDFS和HBase进行交互。
Hive底层执行使用的是MapReduce,所以主要用于处理长时间运行的批处理任务,例如批量提取、转化、加载类型的任务。 - Impala通过与商用并行关系数据库中类似的分布式查询引擎,可以直接从HDFS或者HBase中用SQL语句查询数据,从而大大降低了延迟,主要用于实时查询。
- Impala和Hive采用相同的SQL语法、ODBC 驱动程序和用户接口。
Impala架构
Impala主要由3部分构成:Impalad、State Store、CLI
Impalad
- Query Planner
- Query Coordinator
- Query Exec Engine
作用:
- 协调Client提交的查询的执行
- 给其他Impalad分配任务
- 收集其他Impalad执行结果并汇总
State Store
创建一个State Stored进程,负责收集分布在集群中各个Impalad进程的资源信息用于查询调度。
CLI——执行查询的命令行工具
Notes:
- Impala元数据直接存储在Hive中
- 与HIve相同的元数据,相同的SQL,相同的ODBC驱动程序和用户接口
- 目的:可以在Hadoop统一部署Hive/Impala使同时满足批处理和实时处理
Impala执行过程
执行过程可简略记为:
- 注册和订阅
- 提交查询
- 获取元数据与数据地址
- 分发查询任务
- 汇聚结果
- 返回结果
Hive与Impala的比较
不同点:
- Hive适合长时间批处理查询分析,而Impala适合实时交互式SQL查询;
- Hive依赖于MapReduce,而Impala把执行计划表现为完整的执行计划树;
- Hive内存不够时,利用外存,而Impala在内存不够时,也不会用外存(适合小规模);
相同点:
- Hive与Impala使用相同的存储数据池,支持存入HDFS、HBase
- Hive与Impala使用相同的元数据
- Hive与Impala中对SQL解释处理较为相似(都是通过词法分析生成执行计划)
在实际应用中,由于Hive和Impala的不同特性,可以先由Hive进行数据转换,在用Impala进行数据分析。
Hive编程实践
关于Hive的编程实践可参考厦大数据库博客:基于Hadoop的数据仓库Hive 学习指南

















 3215
3215

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









