






 本文介绍了一种爬取简书网站文章的方法,包括分析网页加载方式、判断异步加载和请求方式,以及如何构造请求参数获取文章链接。通过Python代码实现了获取文章详细信息并保存至数据库和本地文件。
本文介绍了一种爬取简书网站文章的方法,包括分析网页加载方式、判断异步加载和请求方式,以及如何构造请求参数获取文章链接。通过Python代码实现了获取文章详细信息并保存至数据库和本地文件。
问题描述
我想输入一个关键词,获取简书搜索界面的每一页中每一篇文章的url链接。
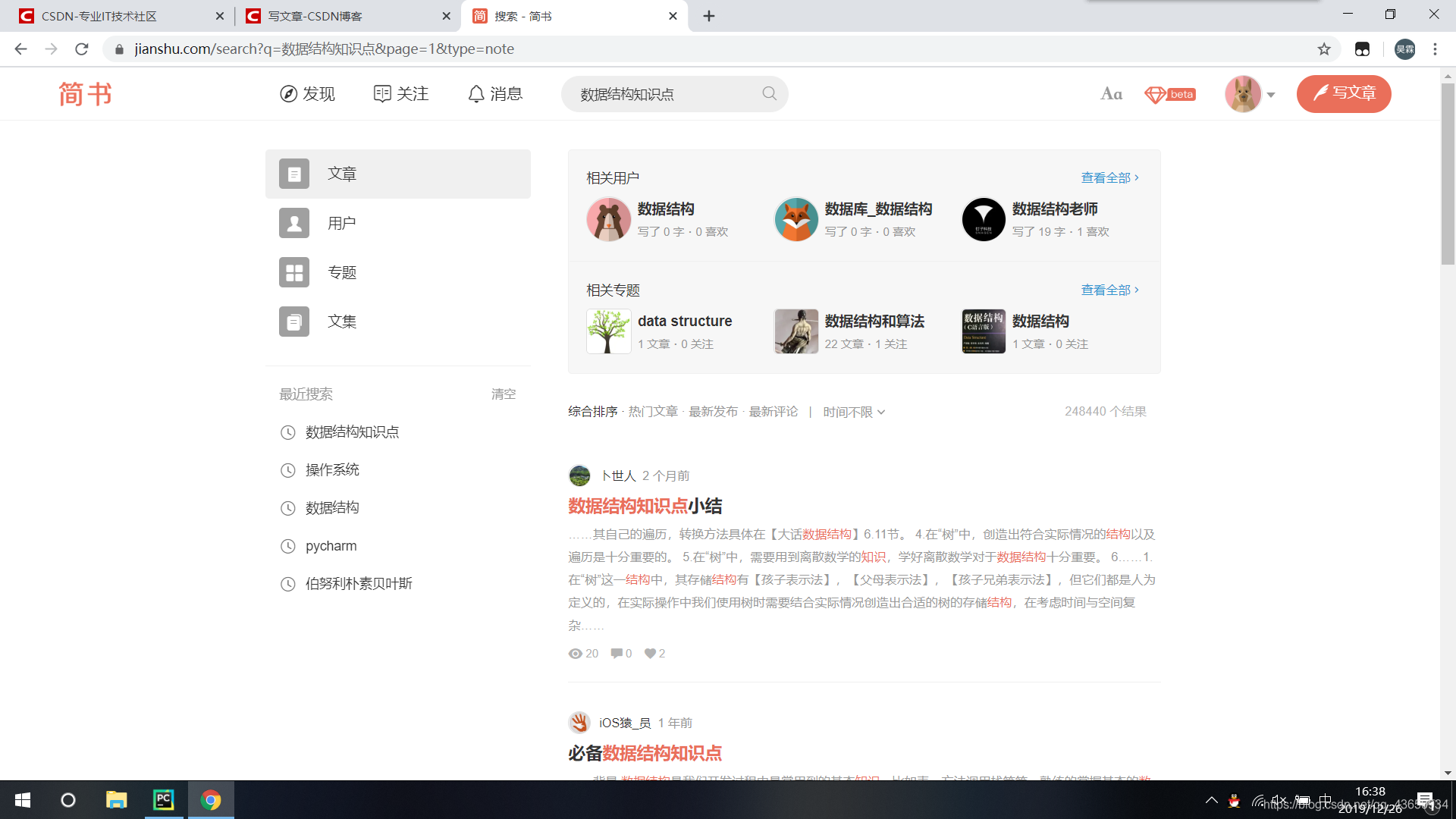
分析网页
1.判断网页加载方式
1)右键查看源代码,发现想要的数据不在源代码里,初步判断网页没那么简单。
2)Google Chorme,f12进入控制台后f5刷新,找到Doc选项,预览第一个包的加载页面,发现只是加载了一些标题等无关紧要的信息,可以判断页面中有价值的东西不是静态加载出来的。
注:Doc是网站第一批请求的包,一般来讲doc中的信息都是静态的,可以直接通过requests库轻易的获取到。
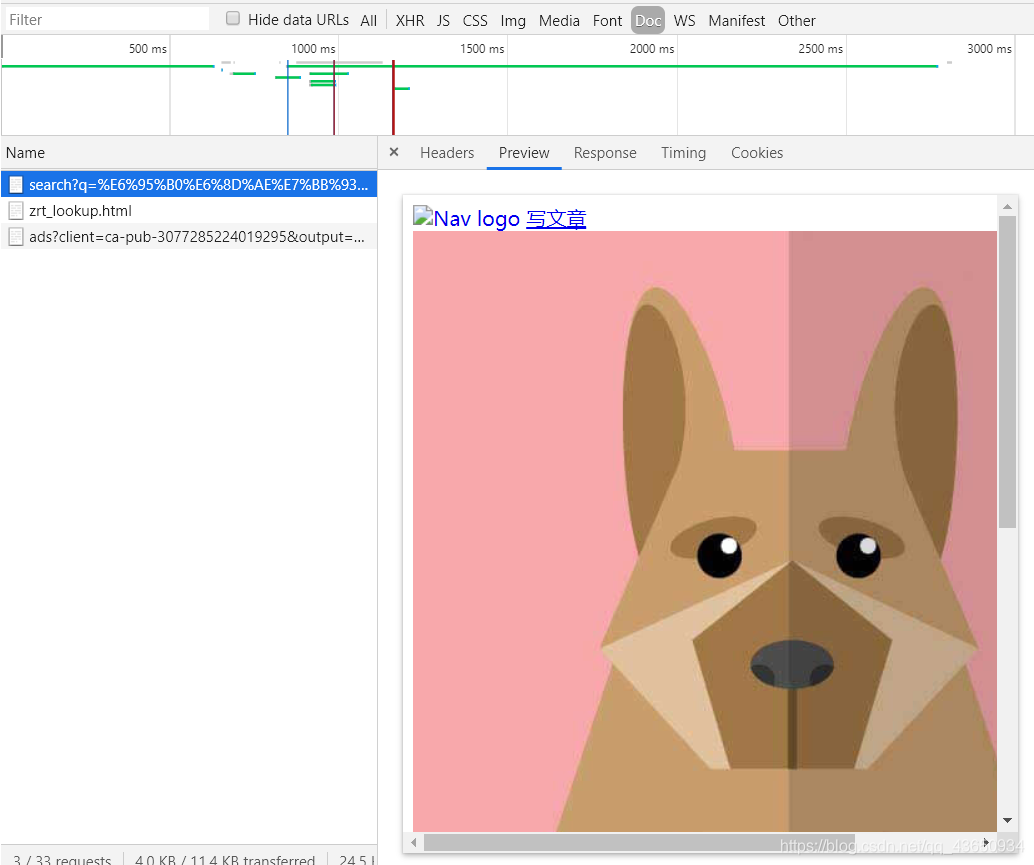
2.判断网页是否为异步加载
3)我们进入XHR栏中,发现加载了一个包,经过观察分析,发现文章的重要信息放在了“entries”中,包含了文章id,标题等信息:
注:XHR是一种浏览器API,可以极大简化异步通信的过程。
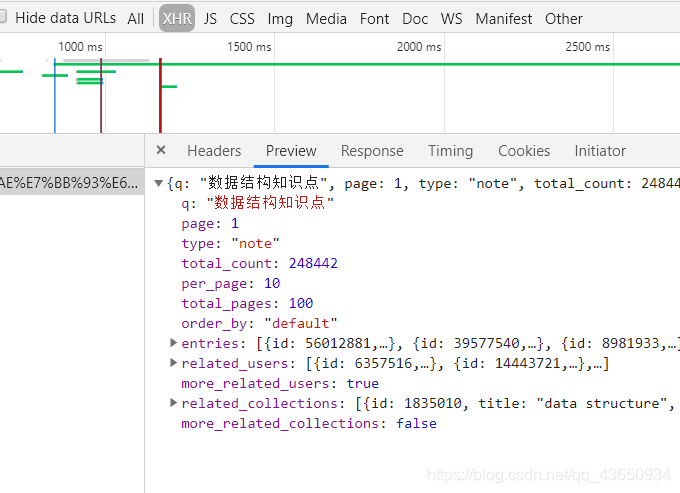
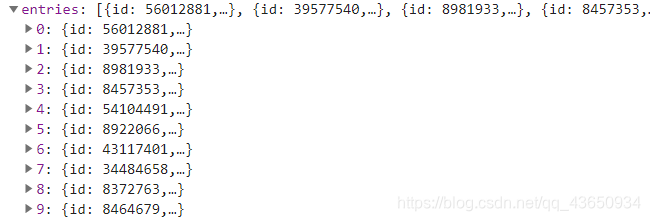
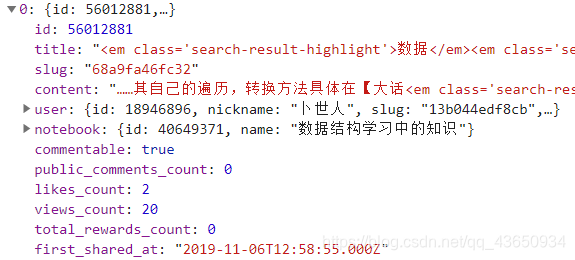
再仔细观察一下,可以发现每篇文章的具体信息中包含一个“slug”标签,这正是每一篇文章的url的后半部分:
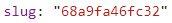

这个方向对了,网页中有价值的信息是以异步加载的方式完成的。
这一值得说明一点的是:Ajax加载也是异步加载的一种形式,而判断是否为Ajax加载的方式是,判断XHR栏中包的Request Headers中是否有以下标签:

当然,简书不是Ajax加载的,经过测试我发现优快云的评论区是Ajax加载的,不过这是另一个问题。如果HDR中有包是Ajax加载的,而你恰好又想要这部分的数据,那么你需要在请求头中加入一对标签:
x-requested-with: XMLHttpRequest
3.判断网页请求方式
还是这个XHR包,我们观察它的Headers信息,很明显地看到它是一个POST请求:
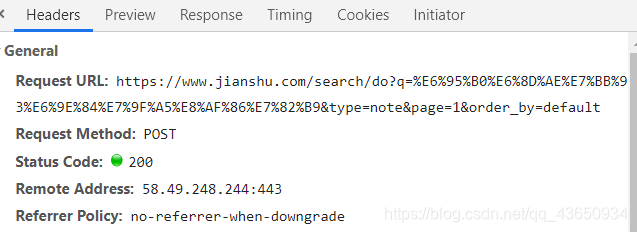
POST请求的意思是,每一次访问网页,需要在请求的url地址后面加上要请求的参数。那么接下来我们就需要找到请求url和请求参数。
获取请求url和请求参数
显而易见,请求url就在Headers的“Requests URL”中:
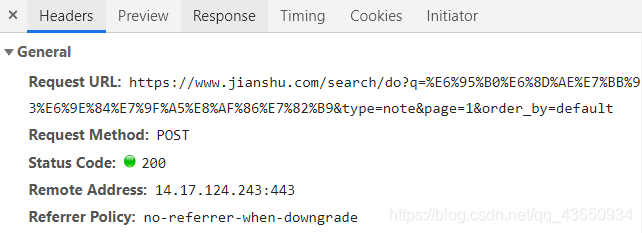
请求参数在Headers的最下面,存放在“Query String Parameters”:
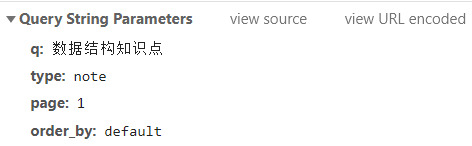
我们换到第二页第三页再看一下请求参数:
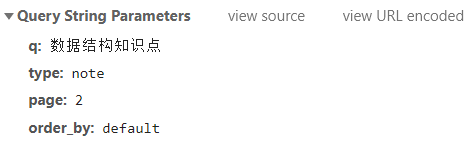

问题逐渐明朗了,请求参数共有4个,而其中只有“page”是跟随页面变化的,这样,我们就能构造一个params,利用post提交参数,进而爬虫。
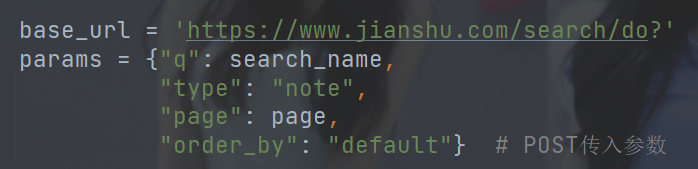
代码展示
直接上代码:
import requests
from bs4 import BeautifulSoup
import re
import os
import pymysql
# 请求头
kv = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.61 Safari/537.36',
'Origin': 'https://www.jianshu.com',
'Connection': 'close'}
list_url = [] # 存放文章url
# 创建表
def Create_table():
try:
db = pymysql.connect(host='localhost', port=3306, user='root', password='52444425', database='test',
charset='utf8') # 主机,端口,用户名,密码,数据库,转义
cursor = db.cursor() # 建立游标
sql_create = """create table Information_jianshu(
url varchar(500),
title varchar(100),
username varchar(1000),
writing text(100000),
publishdate varchar(50),
view text(1000000),
good text(100000),
comments varchar(10000),
directory varchar(500)
)""" # 文章链接,标题,作者名称,内容,发布时间,热度,点赞数,评论,文章目录(如果存在的话)
cursor.execute(sql_create)
db.close()
except Exception as reason:
print('出现错误:', reason)
# 将部分信息写入表
def Insert_table(url, username, view, good, comments):
try:
db = pymysql.connect(host='localhost', port=3306, user='root', password='52444425', database='test',
charset='utf8')
cursor = db.cursor()
sql_insert = """insert into Information_jianshu(url, username, view, good, comments) values (%s, %s, %s, %s, %s)"""
values = (url, username, view, good, comments)
cursor.execute(sql_insert, values)
db.commit() # 执行语句
except Exception as reason:
print('出现错误:', reason)
db.rollback() # 发生错误时回滚
db.close()
# 修改文章内容及其他信息
def Update_writing(title, writing, directory, url):
try:
db = pymysql.connect(host='localhost', port=3306, user='root', password='52444425', database='test',
charset='utf8')
cursor = db.cursor()
sql_update = """UPDATE Information_jianshu SET title = %s, writing = %s, directory = %s WHERE url = %s"""
values = (title, writing, directory, url)
cursor.execute(sql_update, values)
db.commit() # 执行语句
except Exception as reason:
print('出现错误:', reason)
db.rollback() # 发生错误时回滚
db.close()
# 获取及插入相关内容
def Get_info(search_name, page):
# http://api3.xiguadaili.com/ip/?tid=556504418453171&num=100&filter=on
try:
ip = requests.get('http://api3.xiguadaili.com/ip/?tid=556504418453171&num=1&protocol=https') # API调用ip地址
proxies = {}
proxies[ip.text.split(':')[0]] = ip.text.split(':')[1] # 构建ip字典
base_url = 'https://www.jianshu.com/search/do?'
params = {"q": search_name,
"type": "note",
"page": page,
"order_by": "default"} # POST传入参数
demo = requests.post(base_url, data=params, headers=kv, proxies=proxies)
demo.encoding == 'utf-8'
if demo.status_code == 200:
string = str(demo.text)
slug = re.findall(r'"slug":"(.*?)"', string) # 文章标志
username = re.findall(r'"nickname":"(.*?)"', string) # 作者名称
view = re.findall(r'"views_count":(.*?),', string) # 阅读数
good = re.findall(r'"likes_count":(.*?),', string) # 点赞数
comments = re.findall(r'"public_comments_count":(.*?),', string) # 评论数
for i in slug:
url = 'https://www.jianshu.com/p/' + str(i)
username[0] = re.sub(r'<.*?>', '', username[0])
Insert_table(url, username[0], view[0], good[0], comments[0])
list_url.append(url)
del slug[0]
del username[0]
del view[0]
del good[0]
del comments[0]
else:
Get_info(search_name, page)
return list_url
except Exception as reason:
print('出现错误:', reason)
# 获取文章内容及其他信息
def Get_writing(url):
global title
try:
demo = requests.get(url, headers=kv)
demo.enconding = 'utf-8'
soup = BeautifulSoup(demo.content, 'html.parser')
if demo.status_code == 200:
# 获取文章标题
title = str(soup.title)
title = title.split('<title>')[1]
title = title.split(' - 简书')[0]
# 获取文章目录
directory = '' # 存放文章目录(如果存在的话)
try:
for i in soup.find('section', class_='ouvJEz').find_all('h1'):
directory = directory + str(i.text) + ','
except:
pass
try:
for i in soup.find('section', class_='ouvJEz').find_all('h2'):
directory = directory + str(i.text) + ','
except:
pass
try:
for i in soup.find('section', class_='ouvJEz').find_all('h3'):
directory = directory + str(i.text) + ','
except:
pass
try:
for i in soup.find('section', class_='ouvJEz').find_all('h4'):
directory = directory + str(i.text) + ','
except:
pass
try:
for i in soup.find('section', class_='ouvJEz').find_all('h5'):
directory = directory + str(i.text) + ','
except:
pass
try:
for i in soup.find('section', class_='ouvJEz').find_all('h6'):
directory = directory + str(i.text) + ','
except:
pass
# 获取文章内容
writing = demo.text.split('<article class="_2rhmJa">')[1]
writing = writing.split('<div></div>')[0]
writing = writing.replace('\n', '')
writing = writing.replace('\t', '')
writing = re.sub(r'<code(.*?)>(.*?)</code>', '', writing)
writing = re.sub(r'<(.*?)>', '', writing)
else:
raise Exception
return title, writing, directory
except Exception as reason:
print('出现错误:', reason)
# 创建文件夹
def Create_floder(search_name):
try:
os.mkdir(r'./' + search_name) # 创建文件夹
except Exception as reason:
pass
# 存储文件
def Save_writing(writing, search_name):
global title
try:
with open(r'./{}/{}'.format(search_name, title + '.txt'), 'w', encoding='utf-8') as f:
f.write(writing)
except Exception as reason:
print('出现错误:', reason)
# 主函数
def main(search_name):
global title
Create_table()
Create_floder(search_name)
count = 0
for page in range(1, 101): # 简书最多显示100页
list_url = Get_info(search_name, page)
for url in list_url:
title, writing, directory = Get_writing(url)
Save_writing(writing, search_name)
Update_writing(title, writing, directory, url)
count += 1
print("\r当前进度: {:.2f}%".format(count * 100 / int(1000)), end="") # 进度条显示
main('操作系统')

















 2552
2552

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









