







1. 感知机定义
感知机是一种线性分类模型,它的输出为二值,如1和0(或-1)
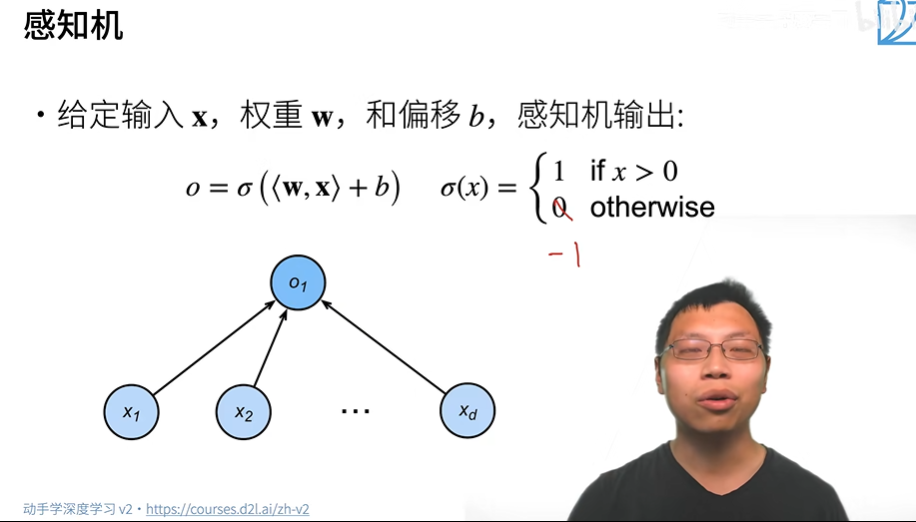
2. 感知机学习算法
这里我们探讨感知机学习算法的原始形式,其另一种形式为对偶形式。
感知机实际上是输入了一个将实例划分为两个类别的超平面,由于输出和输出是已知的,我们可以将其转化为损失函数的最优化求解,即求出最优的w和b,数学模型的建立过程如下:
给定一个训练数据集
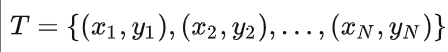
可行域D为
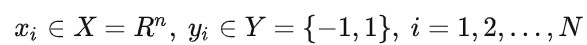
建立目标函数:
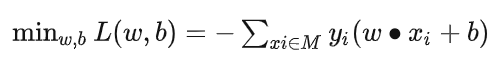
其中M为误分类点的集合。
然后,我们开始目标函数的优化,首先初始化 w0 和 b0,下降算法选择随机梯度下降法,损失函数的梯度为:
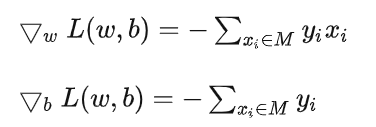
根据梯度公式,我们每采样到一次误分类点,就更新一次模型参数:
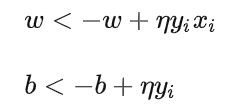
以上更新过程的直观解释为:当一个实例点被误分类,即位于分离超平面的错误一侧时,则调整w, b的值,使分离超平面向该误分类点的一侧移动,以减少该误分类点与超平面的距离,直至超平面越过该误分类点使其被正确分类。
3. 训练过程
下面是感知机训练过程的伪代码。
首先将权重w和偏置b初始化为0,然后开始迭代逼近w、b。其中,yi是真实输出,权重和输入向量的内积加上偏置是预测值。由于输出是二值,即1或0,所以如果预测值和真实值的乘积小于等于0,代表预测和真实的输出不是同一类别,此时更新w和b。如果乘积大于0,则分类成功,继续下一次迭代。

感知机的训练过程也可以看作是使用批量大小为1的梯度下降,损失函数如上图所示。如果真实值和预测值的乘积小于等于0,即分类不准确,则更新模型参数。
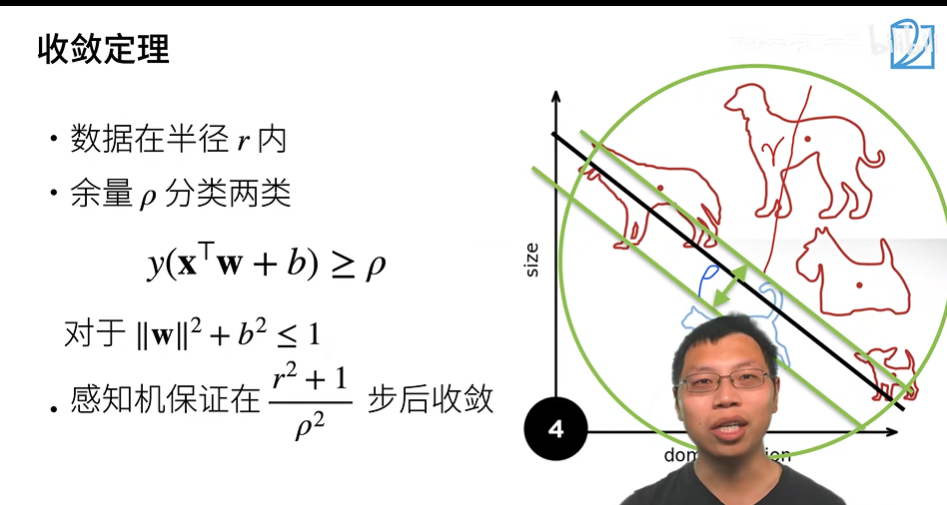
4. 收敛定理
在分类过程中,实际上是存在余量ρ的,只要目标函数在这个余量内,分类就是正确的。这种情况下,感知机是一定会收敛的。r 代表数据的大小,数据越大,收敛越慢。ρ 代表数据的好坏,如果两类数据分得不是很开,则收敛就会很慢。
5. 总结
- 感知机是一个二分类模型,是最早的AI模型之一
- 求解算法等价于使用批量大小为1的梯度下降
- 不能拟合XOR函数,直到多层感知机的提出
6. 参考文献
https://zhuanlan.zhihu.com/p/30155870
https://www.bilibili.com/video/BV1hh411U7
https://zh-v2.d2l.ai/chapter_multilayer-perceptrons/mlp.html

















 5002
5002

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









