




 基数排序是一种非比较型整数排序算法,通过分配和收集的步骤实现。本文介绍了多关键字排序的MSD(最高位优先)和LSD(最低位优先)方法,重点讲解了LSD链式基数排序的原理,包括数据元素分配到桶中,再按顺序收集。算法稳定,时间复杂度为O(d(n+radix)),适用于关键字位数固定且基数已知的情况。
基数排序是一种非比较型整数排序算法,通过分配和收集的步骤实现。本文介绍了多关键字排序的MSD(最高位优先)和LSD(最低位优先)方法,重点讲解了LSD链式基数排序的原理,包括数据元素分配到桶中,再按顺序收集。算法稳定,时间复杂度为O(d(n+radix)),适用于关键字位数固定且基数已知的情况。
9.6 基数排序
基数排序又被称为桶排序。与前面介绍的几种排序方法相比较,基数排序和它们有明显的不同。前面所介绍的排序方法都是建立在对数据元素关键字进行比较的基础上,所以可以称为基于比较的排排序;而基数排序首先将待排序数据元素依次“分配”到不同的桶里,然后再把各桶中的数据元素“收集”到一起。通过使用对多关键字进行排序的这种**“分配”和“收集”的方法,基数排序实现对单关键字**进行排序。
9.6.1 多关键字排序
- 一般情况下,假定数据表中有n个数据元素(elem[0],elem[l],…… elem[n-1])。每个数据元素elem[i] (0<=i<=n-1)含有d个关键字(k1i,k2i,…,kdi)。如果对于序列中任意两个数据元素 elem[j]和 elem[i] (0<=j<i<=n-1)都满足:
(k1i,k2i,…,kdi)<(k1j,k2j,…,kdj)
则称数据元素序列以关键字(k1,k2,…,kd)有序。在此,k1称为最高位关键字,kd称为最低位关键字。 - 实现多关键字排序有两种常用的方法:
(1)最高位优先法 MSD (Most Significant Digit first)
最高位优先法通常是一个递归的过程:
- 首先根据最高位关键字k1进行排序,按k1值的不同,将整个数据表分成若干个子表,每个子表中的数据元素具有相同的关键字k1。
- 然后分别对每一个每个子表中的数据元素根据关键字(k2,…,kd)用最高位优先法进行排序。
- 如此递归,直到对关键字kd完成排序为止。
(2)最低位优先法LSD (Last Significant Digit first)
最低位优先法是: - 首先依据最低位关键字kd对数据表中所有数据元素进行一趟排序;
- 然后依据次低位关键字kd-1对上一趟排序的结果再排序。
- 依次重复,直到按关键字k1完成最后一趟排序。
- 两种方法对比:
- LSD排序方式由关键字的最右边位(低位)开始,先按关键字的最低位把所有元素分配到不同的“子桶”,然后依次把每个“子桶”中元素全部回收,完成一趟“分配”和“回收”:第2趟再按关键字的次低位把所有元素分配到不同的“子桶”,然后依次把每个“子桶”中元素全部回收……如此反复,在最后一趟“分配”“收集”完成后,所有数据元素就按其关键字的值从小到大排序好了。
- 而 MSD 则相反,由关键字的最左边位(高位)开始,是由高位开始进行“分配”,但在“分配”之后并不把所有元素立即“收集”到一起,而是把每个“子桶”中的元素按照下一高位的值分配到“子子桶”中如此不断“分配”,在完成最低位数的“分配”后,再把所有元素依次“收集”到一起。
由此可见,最高位优先分配法的实现要比最低位优先分配法复杂。
使用LSD排序方法时,每一趟排序都是对整个数据表操作,且需采用稳定的排序方法。下面将介绍基于LSD方法的基数排序方法。
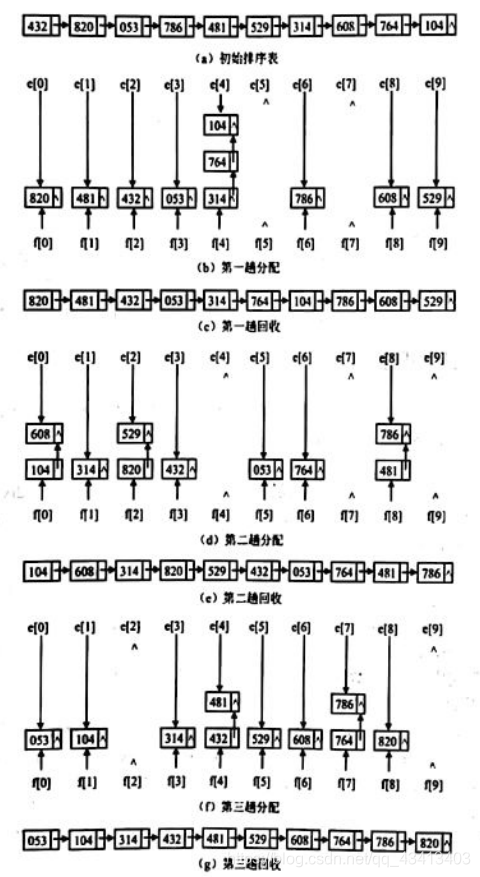
9.6.2 链式基数排序
- LSD排序方法是一种典型的基数排序,它利用“分配”和“收集”这两种运算实现多关键字排序。在这种方法中,把关键字k看成是一个d元组:(k1,k2,…,kd)。其中的每一个分量可以看成是一个单关键字,假设分量kj(1<=j<=d)有radix种取值,则称radix 为基数。
- 例如,关键字984可以看成是一个三元组(9,8,4),位数d=3,每一位可以取0,1.…, 9,这10种值,所以其基数radix=10。
- 用LSD方法排序对d元组中的每一个分量kj,①把数据表中的所有数据元素按kj的取值先“分配”到radix个队列(桶)中去,
②然后再按各队列的顺序,依把数据元素从队列中“收集”起来,这样所有数据元素按kj取值排序完成。
③如果对数据表中所有数据元素按关键字k(k1,k2,…,kd),依次对各分量kj (j=d,d-1,…,1)分别用这种“分配”、“收集"的运算逐趟进行排序,在最后一趟“分配”、“收集”完成后,所有数据元素就按其关键字的值从小到大排序好了。 - 在上述基数排序中,各个队列可以考虑采用链表存储结构,分配到同一队列的关键字通过指针链接起来。
一共有 radix个队列,每一个队列设置两个队列指针:
- 一个指示队头,记为f[ i ](0<=i<radix);
- 另一个指向队尾,记为e[ i ](0<=i<radix)。
- 同时为了有效地存储和重排,数据以静态链表作为它的存储结构。
- 代码实现
template<class ElemType> void RaxidSort(Node<ElemType> elem[],const int d,const int radix)
{
int e[radix],f[radix],p,i,j,k,power;
for(i=0; i<d; i++) //做d趟分配、收集
{
for(j=0; j<radix; j++)
f[j]=0;//初始化各队列分配
power=(int)pow((double)radix,i);
p=elem[0].next;//初始化链表搜索指针
while(p!=-1)//逐个元素分配
{
k=(elem[p].data/power)%radix;//取当前数据元素关键字的第i位
if(f[k]==0)
f[k]=p;//原链表为空时,数据元素入队首
else//原链表非空时,数据元素入队尾
elem[e[k]].next=p;
e[k]=p;//修改链尾指针
p=elem[p].next;//取链表中下一个节点
}
j=0;//开始数据收集
while(f[j]==0)//跳过空队列
j++;
elem[0].next=f[j];
p=e[j];
for(k=j+1; k<radix; k++)
if(f[k]!=0)//回收每个非空队列链入
{
elem[p].next=f[k];
p=e[k];
}
elem[p].next=-1;
}
}
- 对于有n个数据元索的链表,若每个关键字有d位,算法需要重复执行d趟“分配”与“收集”。
①每趟进行**“分配”的循环需要执行n次**,把n个数据元素分配到radix个队列中去;进行**“收集”的循环需要执行radix次**,把radix 个队列中的数据元素收集起来按顺序链接。所以总的时间复杂度为 O(d(n+radix)。
②算法所需要的附加存储空间是为每个是数据元素结点增设的链接指针,及为每一个队列设置的队头和队尾指针,总共为n+2*radix。
③在基数排序中不需要移动数据元素,并且它是一种稳定的排序方法。

















 2097
2097

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









